
July 1, 2026 · 12:36 PM
Fable 5 解禁:旗舰模型发布,开始先过安全闸门再进产品
Anthropic 在出口管制解除后恢复 Fable 5 全球可用,同时把更保守的安全分类器、jailbreak 严重性框架和政府预发布协作摆到台前。本文拆解 Fable 5、GPT-5.6 Sol、Claude Science 与 Gemini Omni Flash 的共同信号:模型竞争正在转向可控、可审计的产品环境。

Fable 5 的回归不是一次普通恢复服务。Anthropic 在 6 月 30 日说,美国政府对 Claude Fable 5 和 Claude Mythos 5 的出口管制已经解除;Fable 5 将从 7 月 1 日起重新面向全球用户开放,入口覆盖 Claude Platform、Claude.ai、Claude Code 和 Claude Cowork。1 美国商务部长 Howard Lutnick 也在北京时间 7 月 1 日早间确认,过去两周美国政府与 Anthropic 一起分析并批准了 Fable 5。2
这件事的重点不只是「模型又能用了」。Fable 5 这次回归时,Anthropic 同时交出了四样东西:更保守的安全分类器、一套 jailbreak 严重性评分框架、面向政府的预发布测试承诺,以及更精细的订阅与付费使用边界。对开发者和企业用户来说,旗舰模型的发布逻辑正在变:能力榜单仍然重要,但能不能被稳定、可解释、可审计地放进产品,正在成为同等重要的竞争项。
这次恢复了什么,没恢复什么
| 事件 | 官方状态 | 对用户的直接影响 |
|---|---|---|
| Fable 5 全球恢复 | 6 月 30 日出口管制解除,Fable 5 从 7 月 1 日起面向全球用户恢复;覆盖 Claude Platform、Claude.ai、Claude Code、Claude Cowork,云平台侧 AWS、Google Cloud 和 Microsoft Foundry 会尽快恢复。1 | 个人、团队和开发者重新拿到 Anthropic 当前最强的通用模型,但高风险请求可能被拦截或转给 Opus 4.8。 |
| Mythos 5 仍是受限模型 | Mythos 5 在 6 月 26 日先恢复给一组美国关键基础设施防御机构;Anthropic 当天称会继续与政府合作,扩大 Mythos 5 与 Fable 5 的可用性。3 | 最强网络安全能力没有变成公开商品,仍主要留在 Glasswing 这类可信访问计划里。 |
| Fable 5 的订阅额度变化 | Pro、Max、Team 和部分 Enterprise 计划在 7 月 7 日前可把 Fable 5 纳入最多 50% 的周使用额度;之后继续使用需要 usage credits,标准 Enterprise 席位没有内含额度。1 | Fable 5 不再像普通聊天模型一样「订阅内随便用」。高能力模型开始更像受配额和消费额度控制的专业资源。 |
Fable 5 和 Mythos 5 的关系也要分清。Anthropic 在 6 月 9 日发布时说,两者是同一个底层模型:Fable 5 加上强防护后面向一般用途,Mythos 5 则在部分领域移除防护,给少数网络防御和关键基础设施伙伴使用。4 当时它们的 API 定价都是每百万输入 token 10 美元、每百万输出 token 50 美元。4
这个定价很高,但不是最值得盯的点。真正的变化是,Anthropic 正在把同一底层模型拆成两种产品形态:一个是带强防护的通用旗舰,一个是受限场景里的专业能力。这比「同一模型不同价格档」更接近权限架构。
为什么 Fable 5 会被暂停
根据 Anthropic 的复盘,6 月 12 日的出口管制来自一份 Amazon 研究人员报告。报告称,研究人员找到了绕过 Fable 5 防护的方法,让模型识别若干软件漏洞;其中一个案例里,模型还生成了演示如何利用漏洞的代码。1
Anthropic 的反驳很具体。它说,自家测试发现,Claude Opus 4.8、GPT-5.5、Kimi K2.7 等较弱模型也能识别同样的漏洞;至于单个漏洞利用演示,测试中的 Haiku 4.5、Sonnet 4.6、Opus 4.6/4.7/4.8、GPT-5.4、GPT-5.5、Kimi K2.7 都能生成类似演示。1 换句话说,Anthropic 认为这不是 Mythos 级网络能力被解锁,而是 Fable 5 的防护边界遇到了一个灰区。
这里要解释一下 jailbreak。它不是传统软件漏洞,而是一类提示或交互方法,目的是让模型绕过原本的安全限制。问题在于,网络安全和生物科学这类双用途任务经常长得很像:同一句「帮我找这个系统的漏洞」,既可能来自防御团队,也可能来自攻击者。模型公司不能只按关键词拦截,也不能完全放开。
Anthropic 的处理方式是训练一个改进后的安全分类器,专门拦截 Amazon 报告里的行为。它称新分类器在超过 99% 的情况下会阻断那种特定技术;被阻断时,用户会收到提示,请求会转交给 Opus 4.8。1 代价也写得很明白:日常编码和调试里的良性请求会更容易被误伤。1
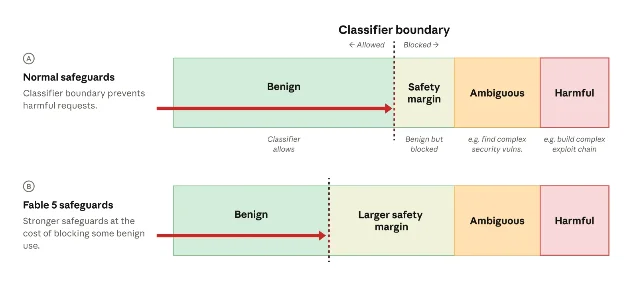
这张图比许多 benchmark 更有信息量。它说明 Fable 5 的产品体验会有一个天然矛盾:分类器越保守,越能降低危险请求漏网的概率;但它也越容易把正常的安全研究、调试、漏洞复现挡在门外。企业真正要评估的不是「会不会拒答」,而是拒答、回退和审计流程能不能嵌入自己的工作流。
Anthropic 想把 jailbreak 做成一个可评分问题
Fable 5 的复盘里,最值得单独拿出来的是 Anthropic 提出的行业框架。它说,现在 AI 行业还没有一个共识标准,用客观方式描述某个 jailbreak 有多严重;这会让开发者和政府都不知道该优先处理哪类发现。1
Anthropic 正在和 Amazon、Microsoft、Google 以及其他 Glasswing 伙伴草拟一套严重性评分框架,暂定看四个维度:能力增益、能力增益的广度、武器化难度、可发现性。1 它还新建了 HackerOne 项目,让安全研究人员在 Fable 5 可用后提交网络安全 jailbreak。1
这个框架的意义不在于四个指标本身多完美。它更像模型安全领域的 CVSS 雏形。传统软件漏洞有 CVSS 分数,团队可以据此判断补丁优先级;前沿模型的 jailbreak 现在还缺这种共同语言。没有共同语言时,一次安全报告可能直接变成出口管制、访问暂停和跨国客户中断。Fable 5 事件把这个问题摆到了台面上。
和 GPT-5.6 Sol 对照看:旗舰模型开始进入「预发布协作」阶段
OpenAI 在 6 月 26 日预览 GPT-5.6 系列时,也使用了类似但不完全相同的发布路径。OpenAI 说,GPT-5.6 Sol、Terra、Luna 会先以小范围可信伙伴预览开始,参与方已与美国政府共享;OpenAI 同时强调,自己不认为这种政府接入流程应成为长期默认。5
两家公司口径不同,但共同点已经很清楚:高能力模型的发布正在多一个前置环节。过去发布节奏主要看算力、评测、产品集成和价格;现在还要看政府预发布评估、分类器、红队结果、可信伙伴名单、日志保留和事后响应。
OpenAI 的技术侧也在朝同一方向走。GPT-5.6 预览稿提到,Sol 配置了 OpenAI 当时最强的安全栈,覆盖高风险活动、敏感网络请求和重复滥用;它还用了实时网络与生物滥用分类器,在高风险情况下可能暂停生成,并让更大的推理模型复核上下文。5 OpenAI 还披露,为自动化红队投入了超过 70 万 A100 等效 GPU 小时,目标是寻找通用 jailbreak。5
所以,Fable 5 不是孤例。它更像一次提前到来的压力测试:当模型接近或跨过网络安全、生物科学、长程 Agent 这些高风险能力线,发布稿里不能只写「更会写代码、更会推理、更会看图」了。厂商必须解释,哪些能力给所有人,哪些能力只给可信用户,哪些请求会被分类器拦下,谁来复核,多久修一次。
同一天的 Claude Science:能力终于要落到可审计工作台里
Anthropic 同日发布 Claude Science,把这条主线推到了科研产品侧。Claude Science 是面向科学家的 AI 工作台,整合研究者常用的工具和包,生成可审计 artifacts,并能灵活接入本地或远程计算资源。6
它的产品描述很具体:用户通过一个协调型 agent 工作,该 agent 预配置了 60 多个面向基因组学、单细胞、蛋白质组学、结构生物学、化学信息学等领域的 skills 和 connectors;它还能启动其他 agent,用户也能创建专门 agent;另有 reviewer agent 检查引用和计算,发现并修正错误。6
Claude Science 还强调两点工程设计。第一,每个输出包含生成它的代码、环境、自然语言说明和完整消息历史,方便几个月后复现。6 第二,它可以在研究者自己的基础设施上运行,支持 macOS、Linux、本地机器、SSH 远程机器和 HPC 登录节点;大数据不必离开原系统,只把每一步需要的上下文发送给 Claude。6
这和 Fable 5 的安全复盘其实是一件事的两面。模型能力越强,产品越不能只是一个聊天框。科学场景需要可复现、可追踪、可撤销、可审计;安全场景需要分类器、访问分层、日志和响应流程。强模型的商业化入口,正在从「把模型放进产品」变成「把模型放进一个受控环境」。
Google 的 Gemini Omni Flash:多模态也在往交互式产品形态走
Google 6 月 30 日更新的 Gemini Omni Flash 文档,给了另一个方向。Gemini Omni Flash 是预览模型,定位是高速视频生成、编辑和电影化控制;模型代码为
gemini-omni-flash-preview,支持文本、图片和最长 10 秒视频作为输入,输出 3 到 10 秒、720p、24 FPS 视频,并有 1,048,576 token 上下文窗口。7完整文档把它的差异写成三点:原生多模态,同时处理文本、图片、音频和视频;通过 Interactions API 做自然语言式迭代编辑;把物理理解和 Gemini 的世界知识结合起来,减少从写实画面到有意义叙事之间的落差。8
这不是纯 LLM 更新,但值得放在同一张图里看。Fable 5 让通用旗舰模型进入访问与安全闸门;Claude Science 把科学 agent 放进可审计工作台;Gemini Omni Flash 则把视频生成从一次性 prompt 推向持续交互。三条线合在一起,说明下一阶段的模型竞争不只发生在参数、榜单和单次回答里,而是发生在「模型如何被包装成可控工具」上。
开发者应该重点观察的四个变量
第一,观察回退机制。Fable 5 被分类器拦下后会转给 Opus 4.8,这比直接拒答更可用;但企业要看的是回退是否稳定、是否可记录、是否会改变输出质量。1
第二,观察 false positives。Anthropic 明说新分类器会更常误伤正常编码和调试请求。1 如果你的团队大量做安全测试、代码审计、漏洞复现或生物信息分析,模型能力提升可能会被安全边界抵消一部分。
第三,观察计费和配额。Fable 5 在 7 月 7 日前有订阅内限额,之后更多依赖 usage credits;Claude 的 usage credits 会在订阅计划用量到达上限后按标准 API 价格继续计费,且需要用户额外启用和充值。9 对高频 Agent 任务来说,这比单看每百万 token 价格更重要。
第四,观察政府与云平台入口。Anthropic 说会尽快在 AWS、Google Cloud 和 Microsoft Foundry 重新启用 Fable 5;OpenAI 的 GPT-5.6 预览也先给 API 和 Codex 的可信伙伴。1 5 如果模型先在厂商自有入口可用,后在云市场可用,企业上线时间就不只取决于模型发布日,还取决于采购、合规和日志策略什么时候跟上。
Fable 5 重新开放后,最值得看的不是它能否重新拿回榜单第一,而是它的保守分类器会在真实工作流里造成多少摩擦。如果 Anthropic 能把拒答、回退、审计和政府协作做成可复制流程,这次中断会变成一次产品化压力测试;如果误伤太多,Fable 5 的强能力会被自己的安全边界吃掉一部分。
Add more perspectives or context around this Post.