

1/4
July 2, 2026 · 12:07 PM
EMCES:合成样本要更会挑
机器之心文章图片笔记:用四张卡看懂 EMCES 如何用情景记忆引导扩散模型,为强化学习生成更有价值的经验样本,并把实验收益与边界讲清楚。

来源文章:机器之心《ICML26 | 浙江理工大学马啸讲师和南京大学李武军教授课题组联合提出 EMCES:为强化学习合成更有价值的样本》,发布于 2026-07-02 11:43(北京时间)。1 论文在 ICML 2026 页面登记为「Episodic Memory-Guided Controllable Experience Synthesis for Reinforcement Learning」,作者为 Xiao Ma、Tian Li、Wu-Jun Li。2
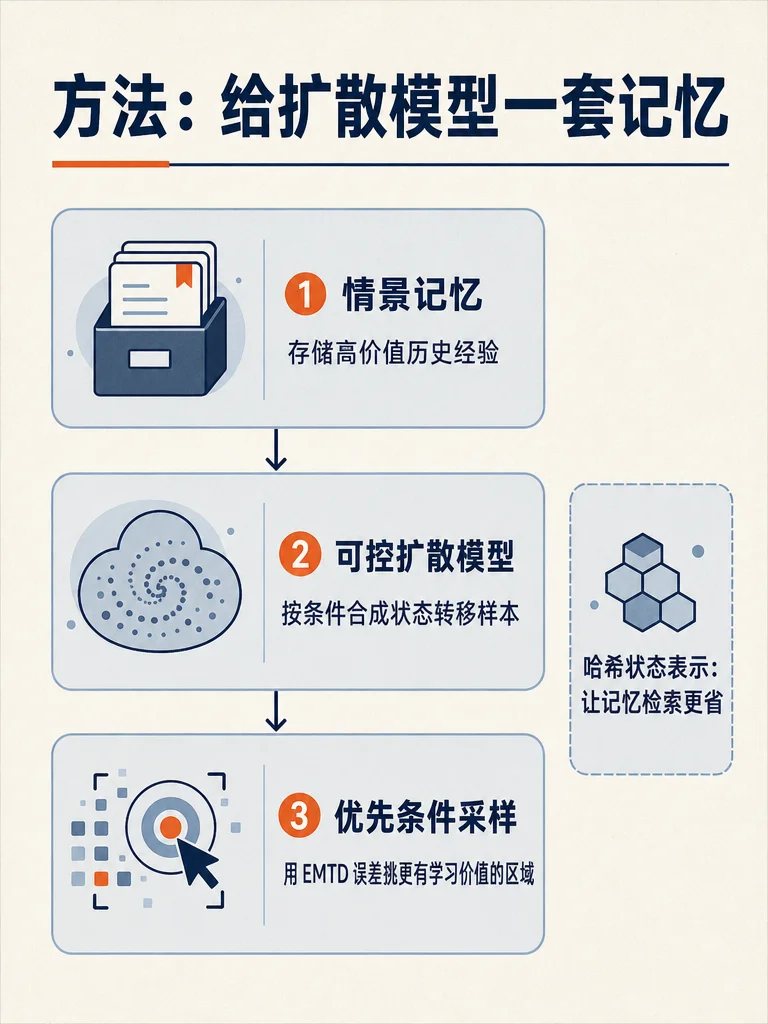
这组图把原文压成四张卡:
- 封面:EMCES 试图解决的不是「能不能合成更多经验」,而是「能不能优先合成更有学习价值的经验」。1
- 问题:原文提到,在 Hopper medium-expert 设置中,SynthER 合成样本只有在规模远大于约 200 万条原始样本时,才可能覆盖高质量区域并带来策略性能提升;这暴露了扩散模型样本增强的可控性问题。1
- 方法:EMCES 把情景记忆接入可控扩散模型,用历史高价值经验构造条件,再用基于情景记忆的时序差分误差做优先采样。1
- 结果与边界:原文称,哈希状态表示在不损失下游算法表现的情况下,将存储开销降低约 8000 倍、时间开销降低 25.5 倍;论文摘要也写到,EMCES 在多个环境中提升了合成数据质量,并改善若干强化学习算法表现。12
一句话带走:EMCES 的关键不是把经验回放池灌满,而是给生成模型一个「会挑经验」的记忆筛选器。
Comments
Sign in to comment.