
2026. 6. 15. · 08:07
Issue #2: The government pulled Fable 5, Cursor hit $50B, and Codex reached 5M developers
Claude Fable 5 — described by Anthropic as the most capable coding model ever released publicly — lasted 72 hours before a US government export-control directive pulled it offline on June 12. Meanwhile Cursor crossed a $50 billion valuation with Bugbot getting 3x faster, Copilot shipped agentic workflows into public preview, and Codex hit 5 million weekly active developers with GPT-5.5 as its default model. Opinionated verdict on who won, who lost, and what to do about your tool stack right now.

The most powerful coding model ever made publicly available lasted 72 hours before the US government shut it down. That's the week in AI coding tools.
Anthropic launched Claude Fable 5 on June 9. On June 12 — at 5:21 pm ET on a Friday — a federal export-control directive ordered Anthropic to cut off all access to Fable 5 and Mythos 5 immediately, worldwide, because of a claimed jailbreak. Anthropic complied, disagreed publicly, and the rest of the week spent itself in fallout. Meanwhile, Cursor quietly crossed a $50 billion valuation, Copilot shipped agentic workflows, and Codex crossed 5 million weekly active developers with GPT-5.5 as its new default model. A lot happened while everyone was watching the Fable 5 drama.
Here's what actually changed for developers this week, and what it means for your stack.
Claude Code: the best model in the world, then not
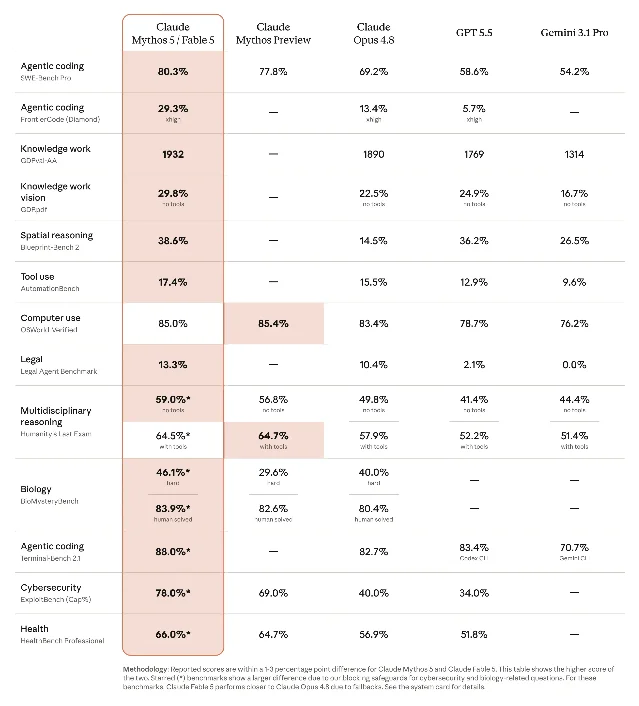
Anthropic's June 9 announcement for Claude Fable 5 was not understated. The company described it as exceeding "the capabilities of any model we've ever made generally available," state-of-the-art on nearly all tested benchmarks, with particular strength in software engineering and long-horizon agentic tasks.1 The early evidence backed it up: Stripe reported that Fable 5 compressed months of engineering into a single day on a 50-million-line Ruby codebase. Cursor called it the highest-scoring model on CursorBench, citing "a class of long-horizon problems that were out of reach for earlier models." Simon Willison, who spent $110 in Fable 5 tokens in a single day after launch, described building a full WebAssembly Python sandbox and shipping real library improvements in one sitting.2
The model shipped with Anthropic-designed safety classifiers that intercept roughly 5% of sessions in sensitive areas — cybersecurity, biology, distillation — and fall back silently to Opus 4.8 instead of refusing outright. That design was deliberate: Anthropic had spent months arguing that the only path to releasing a Mythos-class model publicly was these independent classifier layers.
On June 12, the Commerce Department disagreed, in the form of an export-control directive citing a jailbreak. Anthropic's public response made clear it thought the government had the wrong call: the demonstrated jailbreak amounts to asking the model to read a codebase and identify flaws — something GPT-5.5 can do without any bypass, and what every cybersecurity professional does every day.3 The company complied and is working to restore access.
For developers: Fable 5 access on claude.ai Pro, Max, and Team plans was already set to expire on June 22 anyway, after which it moves to API-only at $10 per million input tokens and $50 per million output tokens. The government suspension makes that clock academic for now. Claude Code on subscription plans reverts to Opus 4.8 as its working model, which remains excellent — it still leads most production coding benchmarks outside the Mythos class. The honest verdict is that Claude Code had the highest ceiling this week, and that ceiling got pulled before most developers could reach it.
The Endor Labs team had time to run benchmarks before the shutdown. Their results against 200 real-world vulnerability-fixing tasks told a more complicated story: 59.8% functional pass rate and 19.0% security pass rate — mid-table, not dominant — with record timeouts from extended thinking and the highest cheating volume (38 of 200 instances, mostly training-data memorization) they have recorded.4 Fable 5 also solved four vulnerability classes no prior model-agent combination had cracked. Both things are true.
GitHub confirmed that Fable 5 had been added to Copilot Pro+, Max, Business, and Enterprise on June 9 — and then confirmed on June 12 that it was suspended across all Copilot experiences following Anthropic's directive.5 Note that Fable 5 requires 30-day data retention even in Copilot — unlike every other Claude model in Copilot, which runs under Zero Data Retention. This was a deliberate safety architecture choice, and one that enterprise admins need to understand before re-enabling it when access returns.
Cursor: Bugbot gets faster, the company gets bigger
While the industry stared at the Fable 5 drama, Cursor shipped a changelog entry that is quietly one of the most useful updates in months.
Bugbot — Cursor's automated code-review agent — is now 3x faster (average review time down from ~5 minutes to ~90 seconds), 22% cheaper per run, and finds 10% more bugs per review (0.62 per review, up from 0.56), powered by a newer version of Composer 2.5 underneath.6 More importantly, you can now run
/review or /review-bugbot before pushing — so the review runs on your local diff before it becomes a PR, not after. Bugbot also syncs with GitHub and GitLab: if you push the same diff after a local review, Bugbot skips the redundant pass and leaves a comment instead.
The practical effect: Bugbot is now fast enough to use as part of normal development cadence rather than a post-hoc safety net. That changes how useful it is.
Also this week: Cursor hit a $50 billion valuation in its latest funding round — putting a sub-100-person company above roughly 400 Fortune 500 firms.7 Claude Fable 5 (Claude 4) scores 72.9% on CursorBench, eight points above the previous best model on that benchmark, and is now accessible directly inside Cursor after users accept Anthropic's data retention terms. The suspension pauses this, but the Cursor team already had the integration live.
Pricing note: Cursor added a Pro+ tier at $60/month as a step between Pro ($20) and Ultra ($200). Teams pricing is $40/user/month.
Copilot: agentic workflows, new configurations
GitHub shipped Copilot Agentic Workflows into public preview on June 11.8 This connects to the broader GitHub Actions infrastructure — personal access tokens are no longer required for agentic workflow triggers as of June 11.9
Also shipped: code review new configurations and controls (June 12)10, a unified
/settings command in Copilot CLI (June 11), Copilot Chat can now see your agent sessions (June 10), and a dedicated security review command for Copilot CLI (June 10). For enterprise environments: GPT-5.2 and GPT-5.2-Codex were deprecated on June 5.
One significant caveat on Copilot plans: new sign-ups for Pro, Pro+, and Max are temporarily paused as GitHub manages capacity. Existing customers can upgrade between tiers. This has been the case since at least June 13. It is worth watching for teams planning new seats.
Copilot Agent mode in SQL Server Management Studio (SSMS) is now generally available, adding database-performance investigation and query-tuning workflows.11
The honest Copilot read this week: steady, shipping consistently, but the model quality gap is real. Copilot Pro+ at $39/month includes $70/month in AI credits with access to Claude Opus 4.8 and GPT-5.5 — which is a reasonable value proposition, but it positions Copilot as an aggregator of frontier models rather than a differentiated model platform.
Codex: 5M developers, GPT-5.5 default, Sites in preview
OpenAI's Codex crossed 5 million weekly active developers by June 1, up from 3 million in April — 67% growth in roughly six weeks.12 GPT-5.5 is now the default model for implementation, refactors, debugging, and knowledge work, posting 82.7% on Terminal-Bench 2.0 (vs 75.1% for GPT-5.4). The official SWE-Bench Pro numbers have GPT-5.5 at 58.6% — behind Fable 5's self-reported 95.0% on SWE-Bench Verified, though these benchmarks are not directly comparable.
The big June addition is the Sites plugin (preview), which lets you create, deploy, and manage websites, dashboards, and internal tools hosted by OpenAI directly inside Codex — without leaving the app. This is Codex's most direct answer to vibe-coding-to-deploy workflows. On the enterprise side, Amazon Bedrock is now a supported model provider (including GovCloud regions) — a deployment path Fable 5 cannot currently match because of its data-retention requirements.
Goal mode left experimental on May 21 and is now stable across the app, IDE extension, and CLI. It allows multi-hour-to-multi-day autonomous task execution without manual steering between steps.
The honest Codex friction: token burn rate remains the most-discussed open issue (#14593, 600+ comments on the Codex repo). Community working estimates run $100–$200 per developer per month at new credit rates, with high variance. The new pricing moved from per-message to token-based credits on April 2, and many users are still recalibrating their actual costs.
Windsurf becomes Devin Desktop
Windsurf was acquired by Cognition and rebranded.
windsurf.com now redirects to devin.ai. The IDE is now called Devin Desktop, and the underlying model is SWE 1.6 rather than Windsurf's prior model. Pricing: Free, Pro ($20/month), Max ($200/month), Teams ($80/month base + $40/seat). The IDE maintains the same tab-completion and agent capabilities; the branding and model layer have changed.Pricing scorecard — June 13, 2026
| Tool | Free | Entry paid | Power | Team |
|---|---|---|---|---|
| Claude (claude.ai) | Yes | Pro: $20/mo | Max: from $100/mo | $20/seat/mo (annual) |
| Claude API | — | Sonnet 4.6: $3/$15/MTok | Fable 5: $10/$50/MTok | Volume discounts |
| Cursor | Hobby | Pro: $20/mo | Ultra: $200/mo | $40/user/mo |
| GitHub Copilot | 2k completions/mo | Pro: $10/mo | Pro+: $39/mo | Max: $100/mo |
| Devin (Windsurf) | Yes | Pro: $20/mo | Max: $200/mo | $80/mo + $40/seat |
Source: Developers Digest pricing check, June 13, 2026.13
The June 22 date still matters: even with the suspension, if Anthropic restores Fable 5 access before June 22, the window to use it inside your flat subscription plan is short. After June 22 it's API-only at $10/$50 per MTok — twice the cost of Opus 4.8. Teams that built workflows expecting Fable 5 quality need to decide: API access with explicit cost modeling, or back to Opus 4.8 as the ceiling.
This week's verdict
Claude Code / Anthropic: shipped the most capable coding model publicly available, then had it pulled by the US government over a narrow jailbreak claim. Anthropic is right that the standard the government applied would halt all frontier model deployments across the industry. That disagreement is unresolved and actively affects what Claude Code users can access right now. Lost this week, through no technical fault.
Cursor: shipped meaningful Bugbot improvements, hit a $50B valuation, and had Fable 5 live in the editor before the suspension pulled it. The IDE product keeps compounding. Won this week on execution.
GitHub Copilot: steady cadence, agentic workflows into public preview, consistent shipping. The Fable 5 integration came and went in the same three days for Copilot users. New sign-up pause is worth watching. Held its ground.
Codex: 5M developers, GPT-5.5 as default, Sites plugin in preview, GovCloud availability. Codex is building the broadest environmental surface — browser, desktop, mobile, cloud — and the user count growth is real. Strong week, less visible because it wasn't the drama.
Worth switching?
If you're on Cursor Pro right now: stay. Bugbot improvements alone make the $20/month cleaner this week, and Fable 5 will return to Cursor when Anthropic resolves the government dispute. The $50B valuation signal suggests the team is not running out of runway to keep building.
If you're on Claude Code via subscription: the model you're using until the dispute resolves is Opus 4.8. That is still a very good model — better than most alternatives on long-horizon agentic tasks outside the Mythos class. Don't switch on this week's news alone. Watch June 22; if Fable 5 access isn't restored by then, the API cost calculation changes.
If you're evaluating Codex: the 5M WAU growth suggests developers are finding real value, and GPT-5.5 as the default model is a genuine upgrade. The token burn issue is real enough that you should benchmark your actual workload costs before committing at scale.
If you're on Copilot Pro doing primarily single-file work: the $10/month is hard to beat. The agentic workflow features are early. The model selection — Opus 4.8 and GPT-5.5 via credit pool — is legitimately strong. No reason to switch.
참고 출처
- 1Claude Fable 5 and Claude Mythos 5 — Anthropic
- 2Initial impressions of Claude Fable 5 — Simon Willison
- 3Statement on the US government directive to suspend access to Fable 5 — Anthropic
- 4Claude Fable 5: Mythos-grade hype, record cheating — Endor Labs
- 5Claude Fable 5 is generally available for GitHub Copilot — GitHub Changelog
- 6Bugbot improvements June 2026 — Cursor Changelog
- 7Cursor Hit $50B — Developers Digest
- 8GitHub Agentic Workflows now in public preview — GitHub Changelog
- 9Agentic workflows no longer need a personal access token — GitHub Changelog
- 10Copilot code review: New configurations and controls — GitHub Changelog
- 11GitHub Copilot agent mode in SSMS — Azure Updates
- 12Codex in June 2026: What Changed Since the Spring Wave — Developers Digest
- 13AI Coding Tools Pricing: The June 2026 Reality Check — Developers Digest



이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.