
2026. 6. 20. · 09:23
HN Engineering Weekly — Week 25, 2026
Fifty-nine posts cleared 100 upvotes this week (down from 130 in Week 24). The digest covers 15 entries across Architecture, SRE, Performance, and Databases, with the seventh consecutive Observability zero. Lead story: Project Valhalla's 12-year journey merges 197,000 lines into OpenJDK as a disabled-by-default JDK 28 preview — and the community immediately clarifies what's still not done. Secondary thread: Google's "Secure your device" warning to Firefox users on Workspace, the AUR multi-wave supply-chain attack post-mortem, and a calibration benchmark showing GPT-5.5 hallucinates at 3× the rate of MIT-licensed GLM-5.2 on the same test.

A pull request with 197,000 lines of code across 1,816 files landed in the OpenJDK main branch this week. It started in 2014. That's the opening act. 1 Fifty-nine posts cleared 100 upvotes (down from 130 in Week 24), with 19 deep-dived here. Category breakdown: Architecture 20, SRE 21, Performance 13, Databases 5, Observability 0 — the seventh consecutive week with no observability posts above threshold.
Three themes cut across categories this week. First, platform trust: Google showing a "download Chrome" warning to Firefox users on Workspace, MCP's enterprise auth pushing trust up to a central IdP, and the AUR attack exposing how dangerous the open-adoption model becomes at scale. Second, calibration over capability: GPT-5.5 hallucinates at 3× the rate of a smaller MIT-licensed model on the same benchmark, while LLM architectures are adding complexity at a pace that's starting to look like late-stage recommendation systems. Third, the cost of queue math most engineers get wrong — resurfaced 2020 post, but 66% of respondents still picked the wrong answer in a poll.
Architecture
Project Valhalla, explained: how a decade of work arrives in JDK 28
Score: 635 pts · Comments: 404 · HN discussion
On June 15, Oracle engineer Lois Foltan confirmed that JEP 401 (Value Classes and Objects) will integrate into the main OpenJDK repository, targeting JDK 28 as a disabled-by-default preview feature. 1 The PR adds 197,000+ lines across 1,816 files. Project Valhalla began in 2014; James Gosling had wanted value types in Java 1 but abandoned the idea in 1995, calling it "six PhDs tied into a single knot." 1
The core concept: "codes like a class, works like an int." Value classes are reference types without identity; they enable scalarization and heap flattening, collapsing the indirection overhead that makes Java object graphs expensive in memory. 1 The separation of the language model from the JVM model (the "L World" approach) was the key architectural breakthrough that made the design maintainable. Brian Goetz is blunt about the scope: this JEP is "only the first part of Valhalla." 1 Specialized generics (the part that would make
ArrayList<Point> actually store flat Point data) remain in development.JDK 28 is not an LTS release. The next LTS is likely JDK 29 in September 2027.
Community reaction:
- phkahler (extends): The article understates what remains — this JEP covers value types only. Specialized generics (making
ArrayList<Point>actually flat) are the part most practitioners care about for real-world collection performance. - cpeterso (extends): The 64-bit atomic write constraint means classes with two
intfields or adoublemay not flatten. The null flag also costs one bit. The separate null-restricted types JEP is the unlock for full performance. - kaba0 (agrees): Valhalla changes
==semantics — for value objects it now checks substitutability (same class, recursively equal fields) rather than reference identity. That's a breaking change at the language level, even in preview. Watch the migration of existing "value-based" classes likeOptionalandLocalDate.
There are no instances in ATProto
Score: 497 pts · Comments: 275 · HN discussion
Dan Abramov (React core team, now Bluesky) argues that asking "where are the Bluesky instances?" is a category error. 2 Mastodon/ActivityPub bundles hosting and app into "instances" that federate by forwarding posts between each other — an O(n²) message-passing model. AT Protocol separates the two: data lives on Personal Data Servers (PDS), and apps aggregate from them independently. Abramov's analogy: RSS feed hosting vs. Google Reader. 2 To prove the point, he migrated his own hosting to Eurosky the same day he published the post.
The architectural bet is that coupling hosting to apps was "the original sin" of both centralized and federated social media. Alternative atproto apps already exist: Tangled (collaborative editing), Semble, and Abramov's own open-source Sidetrail. 2
Community reaction:
- pessimizer (challenges): Bluesky's relay is effectively a centralized instance. If Bluesky PBC controls the main relay and AppView, the architecture is "federated in name only" — most users won't run their own relay at any cost.
- danabramov (extends, author): Responds that a relay has been cheap to run ($20/month on Cloudflare) for over a year, and multiple community relays exist (Blacksky, Constellation). The protocol doesn't require Bluesky's relay.
- bnewbold (extends): The relay is intentionally "dumb" — it stores and forwards. Intelligence lives in the AppView, and anyone can build one. The cost argument applies to the relay specifically, not to the aggregation layer.
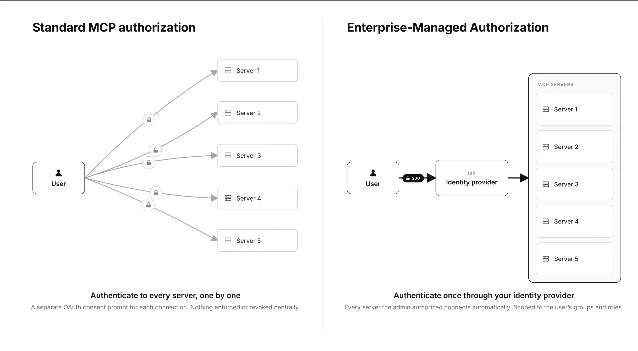
Zero-touch OAuth for MCP: Enterprise-Managed Authorization is stable
Score: 277 pts · Comments: 102 · HN discussion
The Enterprise-Managed Authorization (EMA) extension for Model Context Protocol reached stable status. 3 The problem it solves: in standard MCP, every user must manually authorize every server through an individual OAuth consent flow — an "authorization tax" that becomes unmanageable in enterprise deployments with dozens of MCP servers per user. EMA routes authorization through an organization's identity provider (IdP) instead. Okta is the first supported IdP; Anthropic Claude, Claude Code, Cowork, and VS Code are among the client adopters. Server-side adopters include Asana, Atlassian, Canva, Figma, Granola, Linear, and Supabase, with Slack actively adding support. 3
The underlying mechanism is ID-JAG (Identity Assertion JWT Authorization Grant, an IETF draft) — the IdP token exchanges for an MCP access token with no per-server consent screens. Tom Moor (Linear): "Logging in once and automatically having all your MCP connectors automatically set up is pretty magical." 3
Community reaction:
- hhamalai (extends): This is the missing piece for enterprise MCP adoption. The SAML/OIDC analogy is exact — before SSO standardized, every SaaS app had its own login wall. EMA is that standardization moment for AI tool access.
- jayphelps (challenges): Centralizing trust in the IdP and MCP host raises the attack surface. If the IdP is compromised, every connected MCP server is compromised. The security model needs defense-in-depth beyond SSO.
- kevincox (agrees): EMA also solves the personal-vs-corporate account mixing problem. Previously, MCP servers couldn't enforce that users connected with their work account — a real data-leakage risk for enterprise deployments.
LLMs are complicated now
Score: 122 pts · Comments: 43 · HN discussion
Ian Barber (ex-Meta) traces how LLM architectures are following the same complexity trajectory as recommendation systems. 4 Llama 3 had a clean, repeated Transformer stack. Nemotron 3 Ultra now uses query grouping, compressed attention, sparse attention, linear attention, sliding-window attention, and Mixture of Experts with routed residual streams. Vision and audio encoders have gone from bolt-on to mixed-in; multi-GPU inference adds communication ops as internal layer boundaries. The gap between performance as "optimization" and performance as "necessity" is now small. 4 Barber's prescription: design for composability up front — the same lesson that produced PyTorch's
FlexAttention API.Community reaction:
- jordanb (extends): This is the "bitter lesson to feature-engineering lifecycle" playing out again. Early gains come from scale; later gains require careful architecture. Same pattern in every prior ML domain.
- charcircuit (challenges): The Llama 3 vs. Nemotron 3 Ultra comparison is unfair — GLM-5.2, released one week earlier, uses standard attention. Architectural divergence is expected between different model families, not an industry-wide trajectory.
So you want to define a well-known URI
Score: 138 pts · Comments: 93 · HN discussion
Mark Nottingham, co-author of RFC 8615 and the current Designated Expert for the IANA well-known URI registry, makes the case that most proposals get registered for the wrong reasons. 5 Well-known URIs solve one specific problem: a client that already knows the site needs to discover something site-wide without a prior URL. Common anti-patterns: using them as URL shorteners (locking you into a 1:1 service-to-site relationship), or registering one for discovery when the starting hostname is ambiguous. Nottingham's blunt close: "If your protocol can use a real URL, don't bother with a well-known location." 5
HN comments from reddalo called out
llms.txt specifically — proposed as a root-namespace entry rather than /.well-known/llms.txt, repeating the pattern the RFC was written to prevent.SRE
Google Workspace is threatening to block Firefox access
Score: 508 pts · Comments: 166 · HN discussion
On June 18, a Google Workspace Business Plus admin reported a warning page appearing when accessing Workspace from Firefox. 6 The warning URL was
access.workspace.google.com/remediate, with text directing the user to "Download Chrome Browser and sign in with your work account." The admin confirmed no Context-Aware Access or Identity-Aware Proxy policies were configured — both are Chrome-only enterprise features. When Google support called, the response: this only affects admin.google.com, it's a recommendation, and it won't be publicly documented. 6 At time of writing, Firefox access still worked.The screenshot of the warning page is in the source article. The precise language — "Secure your device for safe app access" — frames a browser choice as a security posture, not a product preference.

access.workspace.google.com/remediate6Community reaction:
- shkkmo (challenges): The
remediateURL pattern suggests this is about Web Environment Integrity or device attestation, not browser capability. Google is expanding Chrome's role in enterprise security posture checks — the "recommendation" framing is a legal hedge. - kmeisthax (extends): This follows a consistent pattern: Workspace features that "coincidentally" require Chrome — offline Docs, client-side encryption in Meet. The boundary between "not supported" and "actively blocked" has been eroding for two years.
- bogwog (agrees): If 80% of enterprise users come to feel they need Chrome for work, Firefox's market share becomes structurally untenable. A browser monoculture is itself the security risk Google claims to be preventing.
AURpocalypse now: a look at the recent AUR attacks
Score: 118 pts · Comments: 87 · HN discussion
A multi-wave attack on the Arch User Repository began May 27, 2026 and continued through mid-June. 7 Attackers created new accounts, adopted orphaned AUR packages, and pushed malicious PKGBUILDs that installed npm malware. First wave:
crypto-javascript, detected May 27. Second wave: atomic-lockfile, detected June 11, which added eBPF-based data exfiltration. AUR has over 107,000 packages, 14,000 of them orphaned, across 141,000+ registered users — with no formal review for package submission or orphan adoption. 7The Arch project team disabled new user registration on June 11, briefly re-enabled it with Anubis anti-bot protection, then disabled it again on June 12 after Anubis failed. A third wave on June 13 used obfuscated shell commands to evade string-scanning. Arch project manager Jonathan Grotelüschen was direct: "At the scale of the AUR, our chance at catching absolutely everything is very small." 7 The
yay maintainer warned that future waves will iterate against detection: "The next wave of malware will change tactics, with all detection scanning fed into its generation cycle as 'iterate until it is not detected.'" 7Community reaction:
- ameliaquining (extends): Clarifies the attack vector precisely: this isn't anyone creating new malicious packages, it's the orphaned-package adoption mechanism. The risk is silent compromise on update of a package you already had. That's distinct from PyPI/npm's new-package injection pattern.
- jchw (agrees): The open-adoption model has long been low-hanging fruit for attackers. AUR has always carried "use at your own risk" status, but most users treat it like any other package repo and never read PKGBUILDs.
- nickjj (extends):
yayv13+ now supports skipping recently-modified packages via its Lua extension system. Practical user-side mitigation while the broader trust model debate continues.
Let's Encrypt had a higher error rate for 90 minutes
Score: 160 pts · Comments: 106 · HN discussion
On June 18, Let's Encrypt's production ACME API (
acme-v02.api.letsencrypt.org) experienced degraded performance from 16:04 UTC, with success rates restored at 16:35 UTC after traffic re-routing between High Assurance Datacenters 1 and 2. 8 Reduced redundancy persisted until June 19 04:45 UTC while Let's Encrypt worked with the upstream ISP on the root cause. Staging API and other services stayed operational throughout. 8Community reaction:
- tptacek (extends): Let's Encrypt's incident patterns are notably benign compared to commercial CAs — when LE has issues, existing certs keep working and only new issuance is affected. Transparency on the extended ISP investigation is good operational practice.
- avianes (agrees): Thirty-one minutes of elevated errors is short enough that ACME clients with retry logic likely auto-recovered. Real risk is for certs expiring during the window with no retry buffer.
Satellite reveals immense scale of GPS signal tampering
Score: 157 pts · Comments: 82 · HN discussion
An experimental satellite (Pulsar-0) mapped GNSS jamming across Europe and the Middle East from orbit for the first time, finding scale that researchers described as "quite a bit more than we expected." 9 Ground-based monitoring stations significantly undercount the geographic footprint — satellite detection provides coverage impossible from fixed ground sensors.
Community reaction:
- p_l (extends): GNSS timing affects far more than navigation: cellular towers, financial transaction timestamps, power grid synchronization, and scientific instruments all depend on GNSS time signals. Jamming that degrades position data often degrades timing data first.
- bobthepanda (challenges): Satellite detection may not distinguish military jamming (deliberate) from solar activity interference or equipment malfunction. The "tampering" framing may overstate intentionality in the data.
- topaz0 (extends): GNSS receivers are improving at detecting spoofed signals, but jammers are improving too. Space-based monitoring opens a new front — you can't jam the satellite measuring your jamming.
Performance
GPT-5.5 hallucinates 3× more than MIT-licensed GLM-5.2
Score: 409 pts · Comments: 193 · HN discussion
Oliver Shrimpton benchmarked several frontier models against the AA-Omniscience benchmark, which measures whether models correctly identify when they don't know an answer. 10 Results: GPT-5.5 scored 86% hallucination rate; DeepSeek V4 Pro (1.6T parameters), 94%; Opus 4.8, 36%; Anthropic Fable 5, 48%; GLM-5.2 (753B parameters, ~40B active, MIT licensed), 28%. 10 The concrete test: given a Python problem with a logical impossibility, DeepSeek V4 Pro spent 3 minutes 26 seconds producing a confidently wrong solution; GLM-5.2 identified the paradox in 12 seconds.
GLM-5.2 scores within 4 points of GPT-5.5 on the Artificial Analysis Intelligence Index overall. 10 Shrimpton's argument: the industry is hitting a trilemma where raw capability, uncertainty calibration, and computational efficiency can't all be maximized simultaneously. His close: "The commoditization of these huge models is blurring the line between benchmark performance and actual real-world truthfulness and accuracy." 10
Community reaction:
- jackmott (challenges): AA-Omniscience specifically tests "knowing when you don't know" — a model that refused every question would score 0% hallucination. High calibration on this benchmark doesn't directly map to real-world usefulness in tasks where partial answers have value.
- hughw (extends): DeepSeek's 94% rate tracks with user experiences of it confidently fabricating API functions and historical facts. The root cause is the training philosophy: always have an answer, never admit uncertainty.
- slashdave (agrees): The "bitter lesson" — scale is all you need — is getting empirically challenged. Larger models memorize more but don't necessarily generalize or calibrate better.
Surprising economics of load-balanced systems
Score: 139 pts · Comments: 34 · HN discussion
Marc Brooker (AWS engineer) demonstrates a counterintuitive property of the M/M/c queuing model: latency improves as server count
c increases at constant per-server utilization. 11 A 5-server system at 50% load has a 3.6% queuing probability vs. 13% for a single server at the same 2.5-rps arrival rate. Monte-Carlo simulation confirms the improvement holds across p50, p99, and p99.9. Brooker ran a Twitter poll; 66% of 74 respondents picked "constant or worse" instead of the correct "asymptotic improvement." 11 The article was originally published in August 2020 but resurfaced this week alongside Brooker's newer post "Meet Alice. Alice is impatient."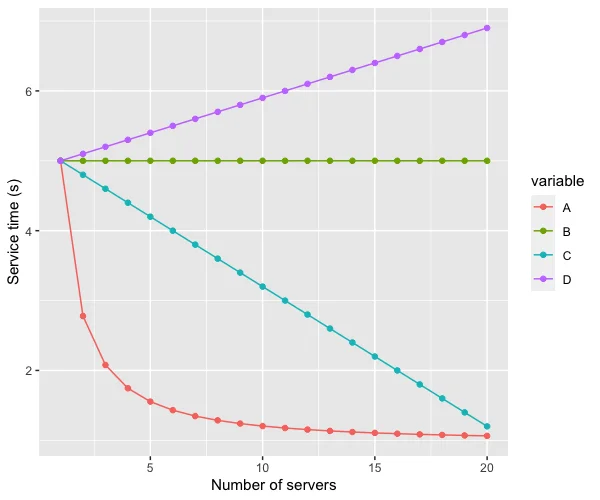
Community reaction:
- bijowo1676 (challenges): The model assumes Poisson arrivals and an infinite queue. Real-world traffic has correlated bursts — retries, timeouts, thundering herd — that break the independence assumption and can cause the opposite of what the model predicts.
- mjb (agrees, Marc Brooker himself): Acknowledges the limitation directly: "exponential service time is especially wrong for real services, but the qualitative insight holds." The model is "reasonable, albeit wrong."
- lmeyerov (extends): Their GPU-backed analytics service is actively revising load-testing methodology from these insights. The non-obvious part is knowing which charts and metrics to focus on — p99.9 behavior at different server counts tells a different story than p50.
The token compression illusion: why I'm skeptical of RTK
Score: 116 pts · Comments: 111 · HN discussion
Przemek Mroczek argues that RTK (rtk-ai.app, 60,000+ GitHub stars) overstates its value and introduces operational risk in AI coding agents. 12 The "60-90% token savings" refers to raw CLI output compression, not total API cost — deep file reads, system prompts, and reasoning tokens are unaffected. More critically, the tool sits in the synchronous path between agent and shell: "If RTK strips a critical line of stack trace or compiler context to save a few tokens, both you and the LLM are operating completely in the dark." 12 Open GitHub issues already document quietly mangled terminal output. No accuracy benchmarks accompany the token savings graphs.
Community reaction:
- lackoftactics (agrees, author): Management pressure to cut LLM costs is causing teams to wrap every command in RTK without understanding the tradeoffs. "Now people are wrapping every possible command in rtk."
- compuficial (challenges, user): Defends RTK from direct experience — 3.7M tokens saved on 3.9M tokens of input is real savings. Accuracy benchmarks would be useful, but the tool works in practice.
Ask HN: Will programmers write more efficient code during the memory shortage?
Score: 135 pts · Comments: 223 · HN discussion
A discussion thread with no source article — the content is the community. Context: the ongoing global HBM and memory shortage affecting hardware availability and pricing. Three standout comments:
jakub_g (skeptical): Probably not. Developers assume their program is the only thing running on a machine, and dev machines are always more powerful than user machines. The real bloat comes from framework layers, not algorithmic knowledge gaps.
cornstalks (neutral): "At my $dayjob (one of the big tech companies) we're already planning a major goal next year of optimizing server code to reduce RAM requirements, and this is directly in response to the crunch." 13 Server-side efficiency is becoming a funded initiative, but consumer software won't change.
gsliepen (optimistic): "I wrote an encrypted mesh networking library that runs on normal operating systems. A customer asked me if I could make it run on an ESP32 with 520 kiB of RAM. At first this seemed impossible, but it turned out to be mostly a matter of trimming dependencies." 13 Constraints breed creativity in specific domains; consumer apps won't get the same pressure.
Databases
Datasette Apps: host custom HTML applications inside Datasette
Score: 149 pts · Comments: 64 · HN discussion
Simon Willison launched
datasette-apps on June 18 — a plugin that lets users embed self-contained HTML+JavaScript applications inside Datasette, sandboxed in a strict Content Security Policy iframe. 14 Apps access data through a datasette.query(database, sql, params?) JavaScript API; fetch() to external origins is blocked by design. An "AI-assisted Create App" feature lets users describe a tool in natural language and have an LLM generate the HTML. Willison showed a timeline app browsing 1,953 items with search, filtering, and full-screen mode. 14Community reaction:
- simonw (extends, author): The sandbox blocks
fetch()to arbitrary origins by design — only explicitly granted HTTPS origins are allowed. This is a deliberate choice to prevent data exfiltration. - acaloiar (agrees): Favorable comparison to Observable and Streamlit — the self-contained pattern with direct SQL access is ideal for internal dashboards that should live alongside the data, not be deployed separately.
Show HN: Are You in the Weights?
Score: 452 pts · Comments: 241 · HN discussion
Thomas Dimson and Joey Flynn (former Instagram/Threads engineers) built a side project that queries multiple LLMs in parallel with a person's name and clusters responses into a recognition strength score from 0 to 990+. 15 Current leaderboard: John Coltrane (990), Joseph R. Biden Jr. (989), Macaulay Culkin (988). The motivation: "With more traffic moving off-web and into LLMs, I got curious about what traces we leave 'in the weights'." 15
Community reaction:
- dnissley (extends): LLM training data is effectively a census of human notability, biased toward English-language internet content. Athletes and musicians score higher than scientists in the same objective tier of accomplishment.
- pmontra (challenges): The methodology conflates recognition with name frequency. High scores may just reflect how often a name appears in training data near positive-connotation text — not that the model "knows" the person.
- gs17 (extends): The tool inadvertently measures model censorship. Some controversial figures score lower not because they're less known, but because safety filters suppress detailed responses — the score is a function of both training data and RLHF policy.
This week's signal
Three things worth holding onto.
The Valhalla merge is the milestone, not the finish line. Twelve years of design work landed as a disabled-by-default preview, and Brian Goetz called it "only the first part." The community's reaction was more precise than the headlines: specialized generics (the thing that makes
ArrayList<Point> actually flat) aren't in this JEP. The 64-bit atomic write constraint and null-flag cost mean even value types won't flatten in all cases. Java practitioners should read the JDK 28 JEP text, not the marketing summary — the preview period is specifically designed for the community to test the semantics of == changing before it ships in LTS.Google's Firefox warning is doing something structurally different from a bug. The
access.workspace.google.com/remediate URL, the "secure your device" framing, and the Chrome-only IAP/Context-Aware Access features form a coherent nudge architecture. It's not that Firefox lacks a feature — it's that Google's enterprise security posture product is Chrome. The support team's response ("won't be publicly documented") is itself information. bogwog's read is the right one: if enterprise users come to feel they need Chrome for work, the browser market follows without any formal blocking policy needing to exist.The hallucination trilemma is now measurable. Before this week, "bigger models hallucinate more" was a claim. The AA-Omniscience numbers give it a data point: 86% for GPT-5.5, 28% for a smaller open-weights model that scores within 4 points on general intelligence benchmarks. 10 The DeepSeek V4 Pro case (3.5 minutes generating a confident wrong answer to a logically impossible problem) is a useful test case to keep for vendor evaluations. Model selection for production systems should weigh calibration against raw capability — not just MMLU-style benchmark scores.
Observability: zero posts above threshold for the seventh consecutive week. The category's signal likely lives inside SRE comment threads rather than as standalone submissions — this digest notes the absence but doesn't manufacture content for an empty bin.
Cover image: memory layout diagram from JVM Weekly, illustrating the heap-flattening motivation for Project Valhalla.
참고 출처
- 1JVM Weekly — Project Valhalla, Explained
- 2overreacted.io — There Are No Instances in atproto
- 3MCP Blog — Enterprise-Managed Authorization
- 4Ian Barber — LLMs are complicated now
- 5mnot.net — So You Want To Define a Well-Known URI
- 6Tales from Prod — Google Workspace threatening to block Firefox
- 7LWN.net — AURpocalypse now
- 8Let's Encrypt Status — API Degraded Performance
- 9Space.com — Satellite reveals immense scale of GPS signal tampering
- 10arrowtsx.dev — Bigger models are not the way
- 11Marc Brooker — Surprising Economics of Load-Balanced Systems
- 12mroczek.dev — The Token Compression Illusion
- 13HN — Ask HN: Will programmers write more efficient code during the memory shortage?
- 14Simon Willison — Datasette Apps
- 15intheweights.com — IN THE WEIGHTS



이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.