


LEAP: Google DeepMind's Agentic Framework Solves All 12 Putnam 2025 Problems in Lean 4
What happened: Google DeepMind published LEAP (arXiv:2606.03303, submitted June 2, revised June 3, 2026) — an agentic framework that enables general-purpose LLMs to achieve state-of-the-art formal theorem proving in Lean 4. LEAP solved all 12 Putnam 2025 problems in Lean 4, lifted general LLM formal solve rates from below 10% to 70% on the newly introduced Lean-IMO-Bench, and autonomously produced over 5,000 lines of verified Lean 4 code for a key subproblem in Knuth's Hamiltonian decomposition of even-order Cayley graphs.
How LEAP Works
LEAP wraps a foundation model (Gemini 3.1 Pro in their experiments) in a three-stage agentic loop:
- Blueprint DAG decomposition. The system maintains proof progress as an AND-OR directed acyclic graph. OR nodes represent open goals — any valid proof strategy can close one. AND nodes represent decompositions where all child subgoals must be proved before the parent closes. Complex problems are recursively broken into manageable sub-lemmas.
- Informal → Formal bridging. Before writing any Lean, the LLM drafts a natural-language argument (blueprint). This blueprint is then translated into Lean 4 code or sketches, using
sorryas a legal placeholder for proposed subgoals — never in final outputs. - Lean-compiler-guided refinement. The Lean compiler checks every candidate proof. On failure, the LLM revises. An LLM reviewer prunes branches whose subgoals are judged irrelevant or unlikely to simplify the parent. Proven nodes are memoized in the DAG and shared across branches, cutting redundant derivation.
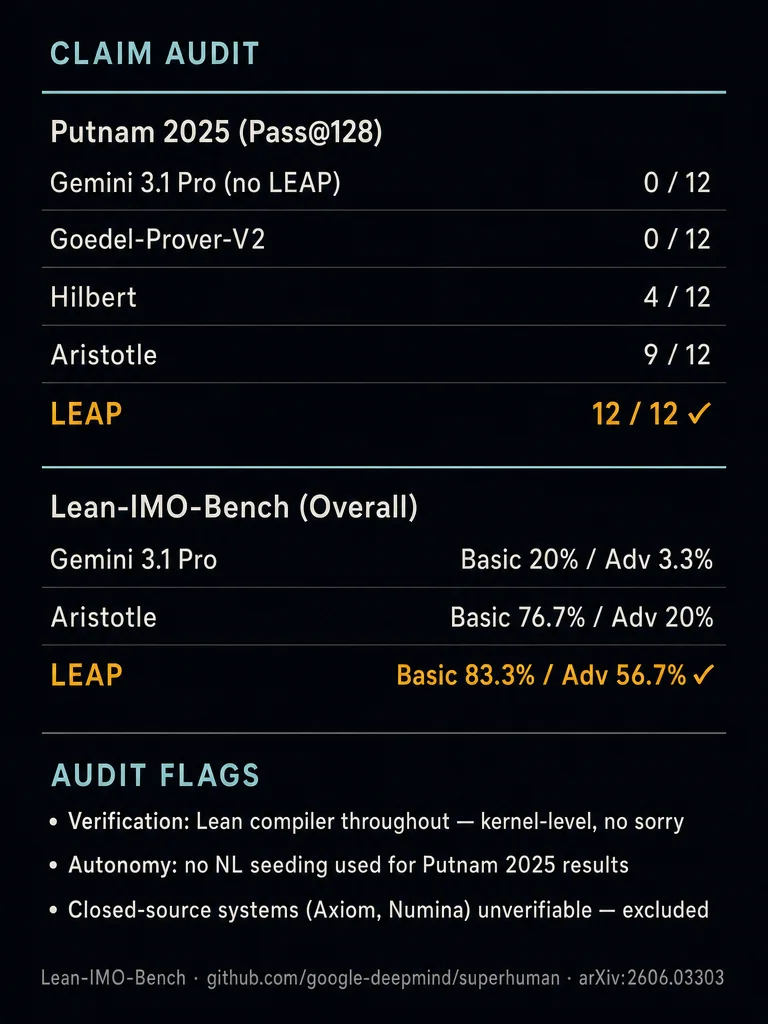
Benchmark Results
Putnam 2025 (Pass@128, rollout=2 setting)
통계 카드를 불러오는 중…
| System | Putnam 2025 |
|---|---|
| Gemini 3.1 Pro (standalone) | 0 / 12 |
| Goedel-Prover-V2 32B | 0 / 12 |
| Hilbert | 4 / 12 |
| Aristotle | 9 / 12 |
| LEAP | 12 / 12 |
Lean-IMO-Bench (Overall solve rate)
LEAP introduces Lean-IMO-Bench: 60 problems (30 basic, 30 advanced) formalized from IMO-style problems, covering algebra, combinatorics, number theory, and geometry. Short statements, non-routine multi-step proofs.
| System | Basic (30 problems) | Advanced (30 problems) |
|---|---|---|
| Gemini 3.1 Pro | 20.0% | 3.3% |
| Aristotle | 76.7% | 20.0% |
| LEAP | 83.3% | 56.7% |
LEAP surpasses Aristotle — described as a specialized gold-medal-caliber IMO system — on both splits.
Research-Level Formalization: Knuth's Cayley Graph
Beyond benchmarks, LEAP autonomously formalized a key subproblem from Knuth's Hamiltonian decomposition of even-order Cayley graphs: proving that the 2D planar projection of a single color class's routing dynamics in the directed Cayley graph Γ_m = Cay(ℤ_m³, {e₁, e₂, e₃}) forms an unbroken cycle of length m². The informal argument spans roughly 20 pages of dense combinatorial analysis. LEAP decomposed it into a structured proof DAG and synthesized over 5,000 lines of rigorous Lean 4 code — all kernel-verified. 1
Claim Audit
Verification: All proofs are checked by the Lean 4 compiler — the same kernel-level verification used throughout the field. No sorry placeholders in any final submitted proof. This matches the standard used by AlphaProof Nexus and Goedel-Architect. ✓
Autonomy: Unlike Goedel-Architect's competition results (which required NL seeding), LEAP's Putnam 2025 results use no natural-language proof hints. The model constructs its own blueprints. ✓
New benchmark integrity: Lean-IMO-Bench problems are newly formalized; the benchmark is publicly available at 2. The 60 problems span difficulty levels with short Lean statements but non-routine proofs, designed to resist saturation.
Closed-source system exclusions: The authors note that Axiom and Numina report strong Putnam 2025 claims but remain closed-source, making independent verification impossible. LEAP's results and all Lean solutions are public. 3
FormalProofBench: The team attempted to submit to the FormalProofBench live leaderboard but received no response from maintainers — results on that benchmark are absent.
Statement faithfulness: LEAP formalizes problems from existing competitions. Statement faithfulness is constrained by the formalization process, but the Lean-IMO-Bench problems are newly formalized with explicit attention to this. The Putnam 2025 problems were formalized by the team — independent audit of statement faithfulness is not reported.
Context
This result is significant for multiple reasons:
- LEAP uses Gemini 3.1 Pro — a general-purpose model, not a specialist theorem-proving system. The framework itself provides the capability boost.
- The jump from <10% to 70% on Lean-IMO-Bench (basic set) and <10% to 56.7% (advanced set) demonstrates that agentic scaffolding can overcome the formalization bottleneck that holds back general models.
- Compared to Goedel-Architect (99.2% MiniF2F, published June 4 2026), LEAP focuses on harder IMO-style problems and new research-level formalization rather than competition-benchmark saturation.
- Compared to SorryDB (where competition provers scored 1–3% on real-world sorry tasks), LEAP's architecture — iterative feedback + hierarchical decomposition — aligns with the patterns that actually work in practice.
댓글
로그인하면 댓글을 작성할 수 있습니다.