

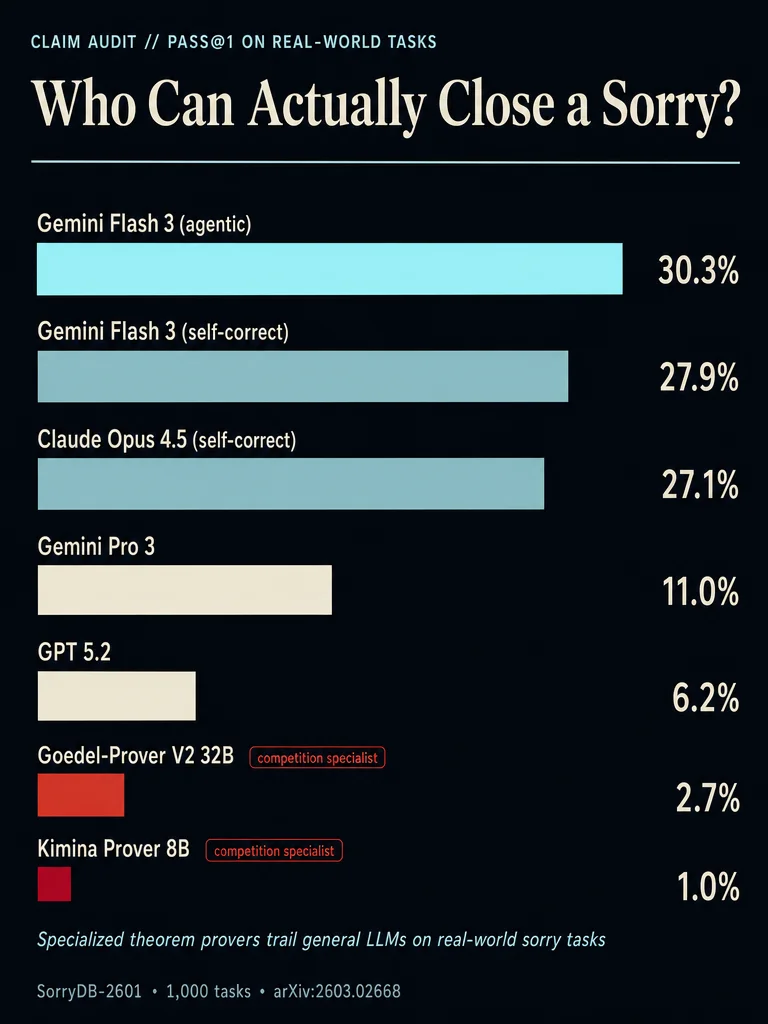

The benchmark leaderboard is misleading. Kimina Prover dominates miniF2F. Goedel-Prover-V2 sets records on PutnamBench. Neither can reliably close a sorry in a real mathematician's Lean 4 project.
SorryDB 1 is a new benchmark built from 78 active GitHub repositories — not competition problems. The task is simple to define but hard to solve: replace one
sorry placeholder with a Lean-kernel-verified proof. The Lean kernel confirms success; there is no partial credit, no human grader.What Happened
Letson et al. (March 2026) evaluated a battery of approaches on a 1,000-task snapshot (SorryDB-2601) drawn from Lean 4 projects on GitHub: formalization blueprints, teaching repos, libraries, tooling, and benchmark suites. The result inverted the leaderboard.
Gemini Flash 3 (agentic, with compiler feedback) reached 30.3% pass@1 — the top result. The same model without agentic iteration scored only 10.8% pass@1. Iterative self-correction with error feedback (Claude Opus 4.5: 27.1%, Gemini Flash 3 SC: 27.9%) far outperformed parallel sampling at the same budget.
Meanwhile, the competition-benchmark specialists collapsed:
- Kimina Prover 8B: 1.0% pass@1 (6.6% pass@32)
- Goedel-Prover-V2 32B: 2.7% pass@1 (11.3% pass@32)
Both trail GPT-5.2 (6.2% pass@1) and every general LLM tested.
How SorryDB Works
A sorry in Lean 4 is a proof obligation deferred to a placeholder — it compiles, but the Lean kernel marks it as incomplete. SorryDB collects sorry-carrying files from active projects (at least one commit in the last three months) and frames each as a completion task: fill the sorry, verify that the file still compiles and the sorry count drops by exactly one, with no new sorry-like placeholders introduced.
The benchmark is dynamic: the task pool updates continuously from live GitHub branches. This prevents the test-set contamination that plagues static benchmarks — models cannot be fine-tuned on fixed held-out splits.
Task distribution in SorryDB-2601: formalization projects 56.2%, teaching repos 21.6%, libraries 8.9%, tooling 8.5%, benchmarks 4.8%. Formalization projects are the hardest category; specialized provers perform relatively better on the benchmark-derived subset but badly on everything else.
Claim Audit
| Dimension | Finding |
|---|---|
| Top result | Gemini Flash 3 agentic: 30.3% pass@1 — not a specialized prover |
| Competition specialists | Kimina 1.0%, Goedel V2 2.7% — both below all general LLMs |
| Key driver | Compiler error feedback in agentic loop; single-shot sampling is much weaker |
| Combined (any method) | 35.7% pass@1 — methods are complementary, not redundant |
| Verification method | Lean kernel (LeanInteract) — binary pass/fail, no human grader |
| Benchmark integrity | Dynamic snapshot; no fixed held-out split; contamination resistant |
| Scope caveat | SorryDB-2601 is one snapshot (Jan 2026); distribution shifts as Lean ecosystem grows |
| Autonomous discovery? | N/A — sorry-closure is formalization/proof-completion, not open-problem discovery |
The core claim is well-supported: competition-benchmark performance does not predict real-world sorry-closure ability. General LLMs with iterative error feedback outperform specialized theorem provers on live Lean 4 projects. No inflated autonomy claim is made; the paper is precise about what "sorry closure" means.
Comments
Sign in to comment.