


LeanMarathon: 4 Erdős Problems, 258 Lemmas, 0 Sorry — Without a Blueprint
AI-generated diagram based on 1. Card 2: the four contract-scoped agents + two-stage orchestrator.
A closed-source commercial tool (Aristotle) was given the same inputs: the source paper text and the target theorem statements. It ran for over 40 hours on Erdős–Graham (#1051) and over 24 hours on ESS #1196 — and failed both, leaving sorry placeholders in a Lean file that barely compiled. LeanMarathon, a new open-source multi-agent harness from Warwick/Michigan/Tokyo/Berkeley/SJTU, completed all four Erdős problems across 7 target theorems, proving 258 lemmas and theorems with zero sorry remaining. 1
What Actually Happened
LeanMarathon was evaluated on two 2026 research papers covering four Erdős problems: #1051 (Erdős–Graham irrationality), #1196 (Primitive Sets and von Mangoldt Chains), #164 (Erdős Primitive Set Conjecture), and #1217 (Erdős–Sárközy–Szemerédi divisible chains). Across three autonomous runs, the system:
- Proved all 7 target theorems with zero sorry
- Generated 27,093 lines of Lean 4 across the three problem sets
- Ran on Codex (GPT-5.5-xhigh, 258K context) as the backbone LLM — no human proof blueprint was provided; the system built its own DAG from source paper text
- Cost $257–$624 per paper depending on complexity
The commercial baseline Aristotle produced 751 lines on Erdős–Graham (vs 8,513 by LeanMarathon), left 2 sorry, and failed after 40+ hours. On ESS #1196: Aristotle 24 lines, 1 sorry, failed; LeanMarathon 3,988 lines, 0 sorry, complete.
The Core Idea: Agent Durability Over Prover Power
The paper's central argument is that the bottleneck in research-level (as opposed to competition-level) autoformalization is not whether an LLM can close a single Lean goal — it's whether the system stays coherent across hundreds of mutually-dependent declarations over a multi-hour run.
Three failure modes kill monolithic agents at scale:
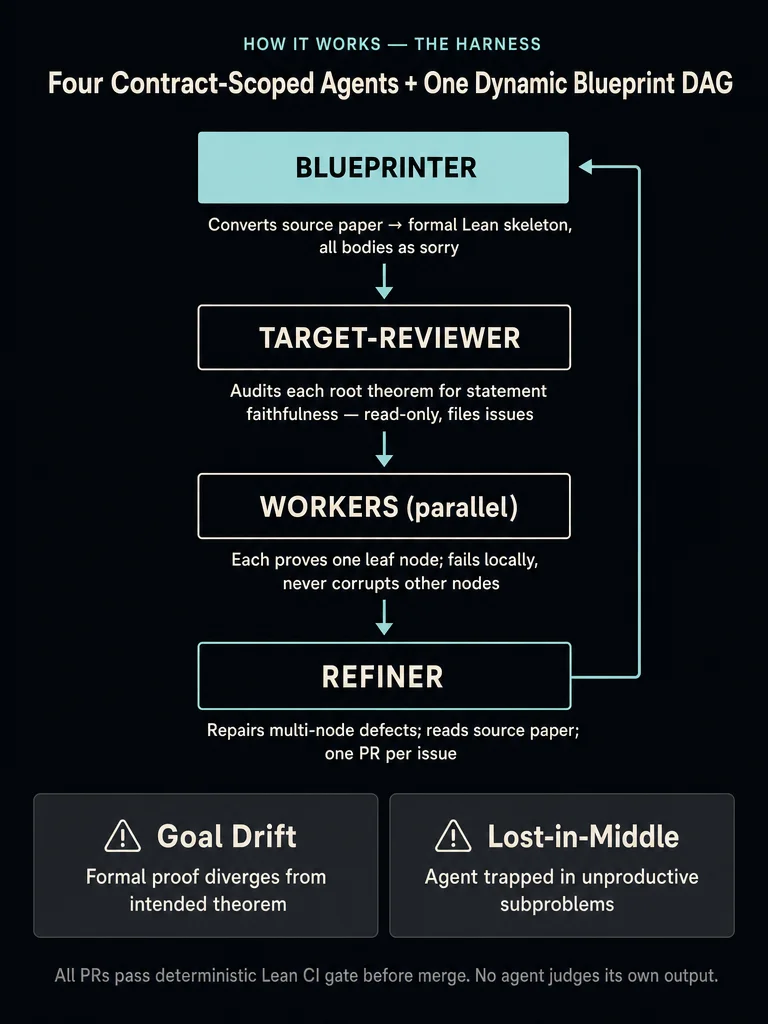
- Goal drift — formal statements gradually diverge from the intended theorem; the agent proves something formally valid but mathematically wrong
- Lost-in-the-middle — the agent gets trapped in unproductive subproblem trees and can't backtrack
- Coherence loss — local repairs to one lemma silently invalidate distant proofs
LeanMarathon's answer is fault containment through contract-scoped agents:
- Blueprinter — reads the source proof and generates the initial Lean skeleton with all proofs as sorry; optimizes for small repair radius (minimizes the blast zone if a node is wrong)
- Target-Reviewer — audits each root theorem statement against the canonical mathematical claim before large-scale proving begins; read-only, cannot corrupt anything
- Workers (parallel) — each proves exactly one leaf node; failures are local and can't propagate
- Refiner — reads the source paper; repairs multi-node defects in bounded sub-DAGs; one PR per issue
A two-stage orchestrator runs adversarial Target-Reviewer ↔ Refiner cycles first (statement fidelity), then discharges the proof DAG from dynamic leaves upward in parallel CI-gated rounds. Every PR passes a deterministic Lean compiler gate before merge — no agent judges its own output.
The blueprint is the key artifact: a single Lean file serving simultaneously as formal proof skeleton, natural-language proof graph, and shared system of record. LaTeX prose and Lean types are kept in parity; a PR that lets the natural-language dependency graph diverge from the elaborator's dependency graph is rejected.
Claim Audit
AI-generated audit card based on 1. Card 3: LeanMarathon vs Aristotle baseline.
| Dimension | Status |
|---|---|
| Lean 4 kernel verification | ✅ All proofs machine-checked; no sorry in final state |
| Autonomy | ✅ Fully autonomous — no human proof blueprint; system builds its own from source paper |
| Statement faithfulness | ✅ Adversarial Target-Reviewer loop enforces fidelity before proof discharge |
| Erdős problem scope | ✅ 4 problems from 2 peer-reviewed 2026 papers |
| Comparison baseline | ✅ Aristotle given identical inputs; direct head-to-head |
| Scope caveat | ⚠️ Requires Mathlib-mature domains; domains lacking Lean library coverage are not testable |
| Cost transparency | ✅ API cost reported per run ($257–$624 at GPT-5.5-xhigh rates) |
| Open-source | ✅ MIT license, code at github.com/YuanheZ/LeanMarathon |
Why This Matters for the Frontier
SorryDB showed 2 that competition-benchmark provers are nearly useless on real-world sorry-closure tasks. LeanMarathon addresses the complementary problem: not closing individual sorries in existing Lean files, but formalizing entire research papers from scratch — building the Lean development from the source PDF up. The key insight is architectural: reliable AI co-mathematics requires not just stronger provers, but durable harnesses that contain failures and preserve statement fidelity across long mathematical developments.
The contrast with prior covered events is instructive: AlphaProof Nexus 3 uses evolutionary proof search on Mathlib-mature Erdős problems; LEAP 4 uses Blueprint DAG for competition problems with human-provided informal proofs. LeanMarathon's niche is the one without a provided proof plan — take a research paper, build the formalization yourself, stay coherent for 40+ hours.
Source: 1, submitted June 3, 2026. Code: github.com/YuanheZ/LeanMarathon
コメント
ログインするとコメントできます。