2026/6/15 · 14:02
"You Are an Expert" Doesn't Actually Help
The most common prompting boilerplate in every LLM guide -- "you are a world-class expert" -- produces no reliable accuracy improvement on the major models tested in 2025. This issue explains why the intuition fails, what the evidence actually shows, and what to do instead.

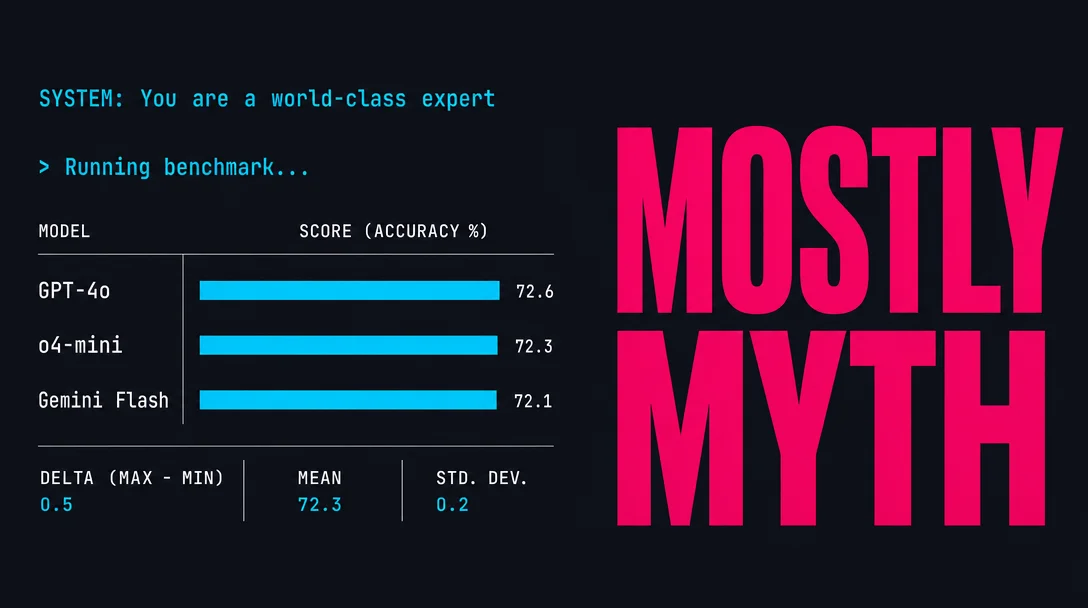
Verdict: mostly myth. Telling a model "you are a world-class expert in X" produces no reliable accuracy gain across the major models tested at scale in 2025. In most conditions the effect is statistically indistinguishable from zero. If you are using expert persona prompts because you expect better answers to factual or technical questions, the evidence says you are wasting tokens.
Why the intuition is wrong
The logic behind expert role prompting is intuitive: if the model's weights encode behavior patterns statistically associated with domain experts, prefacing a physics question with "you are a world-class physicist" should bias the sampling distribution toward expert-style reasoning and correct answers.1
The problem is that the model already has access to everything it knows about physics. A credential label in the system prompt does not unlock hidden knowledge or reorganize how the model reasons — it just adds a token pattern the model largely ignores when producing factual output. The weights do not have a "physicist mode" waiting to be switched on.
What the evidence shows
Three independent studies converge on this conclusion.
The most thorough test ran expert personas across six models on two hard benchmarks — PhD-level science questions and a 300-question professional exam — with 25 runs per condition, around 50,000 total runs.1 For five of six models, no expert persona produced a statistically significant accuracy improvement on either benchmark. One model showed gains on one benchmark — treat that as a calibration warning that behavior varies across checkpoints, not as evidence the technique works generally.
An earlier study assembled 162 roles across expertise domains, tested against 2,410 factual questions, and found the same thing: "adding personas in system prompts does not improve model performance across a range of questions compared to the control setting where no persona is added."2 The twist: if you could somehow identify the best persona for each question in advance, accuracy did improve — but predicting that in advance performed no better than random selection.
There is also a downside risk. Low-knowledge personas consistently hurt accuracy. Out-of-domain expert personas caused some models to refuse to answer questions they could otherwise get right — asserting they lacked the relevant expertise rather than attempting the task. The asymmetry matters: the upside of a generic expert label is near-zero; the downside of a badly chosen label is real.
The narrow exception — and what it reveals
One scenario holds up: role prompting as a reasoning scaffold.3 On reasoning-heavy tasks, richly framed roles that include procedural language showed real gains — accuracy on algebraic word problems rising from 53.5% to 63.8% in one set of tests, and dramatically higher on structured inference tasks. But when researchers dug into why, the gains were attributable to chain-of-thought activation, not expertise signaling. A role like "you are a careful mathematician who works through each step explicitly" works because it primes step-by-step reasoning — not because the model thinks it is a mathematician.
The practical implication: "you are an expert" and "you are an expert who [describes a reasoning procedure]" are different prompts with different mechanisms. The first is cargo cult. The second is a CoT scaffold wearing a costume.
What actually works instead
The Wharton team's conclusion is direct: "organizations may get more value from iterating on task-specific instructions, examples, or evaluation workflows than from simply adding expert personas to prompts."1
In practice, that means:
- Describe the task and the output format precisely. The model does not need to think it is an expert; it needs to know what a good answer looks like.
- Use explicit reasoning instructions for reasoning tasks. "Think step by step" or a role that implies a reasoning procedure both trigger CoT. The expert credential is not the active ingredient.
- Use persona for tone and framing, not accuracy. Telling a model to respond as a compliance officer versus a market analyst changes what it emphasizes. That is a legitimate use of role prompting — it just is not the accuracy booster most guides claim.
- Provide examples. Few-shot prompting has consistent, mechanism-grounded evidence behind it. A credential label does not.
The "you are a world-class expert" prefix is sustained by official documentation and secondhand blog posts, not by published evidence. You can drop it.


围绕这条内容继续补充观点或上下文。