
2026/7/1 · 17:10
TTT-VLA:只优化潜在提示,VLA 能在部署时自我校准吗?
ByteDance Seed 参与的 TTT-VLA 论文把机器人 VLA 的部署适应压缩到一个小接口:测试时只优化 latent prompt,不改 policy 主体。本文拆解它的 state grounding 代理任务、SimplerEnv 实验结果、critical decision steering 现象,以及真实部署前仍没解决的成本与稳定性问题。

VLA 机器人模型的部署难点,很少是「完全不会做」这么简单。更常见的情况是,模型大体知道该抓什么、往哪放,却在某个很短的阶段判断错了:东西已经夹住了,它还继续往下压;方块还没对齐,它就急着松手。ByteDance Seed 参与的 TTT-VLA 论文把这个问题收束到一个很小的接口上:测试时不改模型主体,只优化一段可学习的 latent prompt。论文于 2026 年 6 月 2 日提交到 arXiv,标题为 TTT-VLA: Test-Time Latent Prompt Optimization for Vision-Language-Action Models,作者包括 Wenbo Zhang、Jianxiong Li、Shuai Yang、Sijin Chen、Jiajun Liu、Lingqiao Liu 和 Xiao Ma,论文页标注工作在 ByteDance Seed 完成。1
这篇论文的核心判断是:VLA 的部署适应不一定非要走 RL 后训练,也不一定要人类不断给新提示。TTT-VLA 试图让模型从当前环境里的交互数据中拿到自监督信号,然后只把这个信号写进 latent prompt,policy backbone、action expert 和 state expert 都保持冻结。2 这个方向如果成立,价值不在于多一个 prompt 技巧,而在于给机器人基础模型留出一个较低风险的「现场校准旋钮」。
它想解决的问题:部署时的分布漂移
视觉语言行动模型把图像、语言指令和动作生成放进同一个策略里。训练时它可能见过很多机器人轨迹,到了部署时却会遇到新的光照、物体姿态、相机视角、桌面布局,甚至不同机器人的本体差异。论文把这种差异称为 deployment-time distribution shift,并把 TTT-VLA 放在「部署时改进」这个问题上讨论。2
现有路线大致有三类。人类辅助 steering 可以用任务分解、metadata、轨迹提示去引导模型,但它依赖外部指导;RL post-training 能从交互中继续优化策略,但通常需要 reward,成本也高;测试时训练使用自监督 loss,在部署环境里更新模型的一部分。TTT-VLA 属于第三类,但它把更新范围压到 latent prompt 上。2
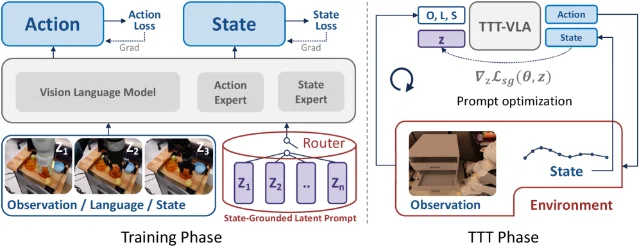
方法:给 VLA 加一个能在测试时学习的暗提示
latent prompt 可以理解为一组不可读的向量 token。它不像自然语言提示那样写着「把胡萝卜放进盘子」,也不是人类手动指定的 trace,而是训练出来的一段条件变量。论文把 VLA policy 写成根据 observation 和 conditioning context 预测 action chunk 的条件策略,其中 conditioning context 可以包含语言、状态、图像,也可以包含这个可学习的 latent prompt。2
训练时,TTT-VLA 不替换原本的动作学习目标,而是在动作 loss 之外加一个 proxy objective。当前实现里的 proxy task 叫 state grounding:模型要根据当前观测、显式 prompt 和 latent prompt,预测机器人末端执行器位置与夹爪状态。论文选择这个任务有两个理由:这些状态目标在训练和部署时都能拿到,不需要额外人工标注;准确预测状态又需要空间理解和机器人本体相关信息,和控制决策有关。2
测试时,流程变成三步:先在当前环境收集交互数据,放进 buffer;再用 state grounding loss 更新 latent prompt;最后用更新后的 prompt 继续控制机器人。关键约束是,只更新 prompt,不更新 policy backbone。论文还试了 online prompt update,但发现 batch size 很小时容易不稳定,prompt representation 会坍缩,所以主方法采用 offline buffer 优化。2
架构上,TTT-VLA 基于 Mixture-of-Transformers,包含 action expert 和 state-grounding expert。训练从预训练的 π0.5 checkpoint 初始化。多本体场景下,它为不同 embodiment 关联不同 state-grounded latent prompts;单一本体场景下,它采用两阶段训练,并用随机 drop 机制控制 latent prompt 到 action expert 的连接,避免 prompt 一开始就破坏基础策略。2
结果:提升存在,但不是免费午餐
论文在 SimplerEnv 上做评测,覆盖单一本体和多本体两种设定。单一本体里包括 WidowX 和 Google Robot 任务;多本体里用 OXE-Aug BridgeData V2 的九种 embodiment 训练,再在 WidowX 上评测。2
几个关键数字值得单独看:
- WidowX benchmark 上,内部 π0.5 baseline 的平均成功率是 51.1%;加入 state-grounded latent prompt 后升到 63.5%;再做 TTT 后升到 67.4%。2
- Google Robot visual matching split 上,平均成功率从 67.5% 到 68.9%,再到 72.4%;variant aggregation split 上,从 58.1% 到 58.6%,再到 60.1%。2
- 多本体 WidowX 设定下,平均成功率从 22.8% 到 28.5%,再到 31.6%;论文特别指出 Cube 任务仍然很难,因为它需要更精细的抓取和放置对齐。2
这些数字说明两件事。第一,latent prompt 本身就带来不少收益,尤其是 WidowX 的 51.1% 到 63.5%。第二,测试时训练继续增加收益,但幅度更小。它更像是在基础策略已经接近可用时,修正一部分现场错判,而不是把一个弱策略重新训练成强策略。
成本也要算进去。论文披露,训练单一本体模型用 20,000 steps,多本体模型用 40,000 steps,AdamW 学习率 1×10^-4,batch size 1024;训练在 32 张 NVIDIA H100 上进行,每次约 20 小时。测试时训练只更新 latent prompt,但仍使用 8 张 H100,WidowX 做 500 步、Google Robot 做 1000 步,通常需要 15 到 30 分钟。2 这不是一个能直接塞进低成本边缘设备的方案,至少论文当前实验形态还不是。
增益来自哪里:少数关键决策点
论文最有意思的分析,不是平均成功率,而是「critical decision steering」。作者对齐 baseline 和 TTT 后的 rollout,发现 TTT 往往没有全程改写轨迹,而是在少数关键决策点上改变动作。胡萝卜例子里,夹爪真正抓住物体之前,有无 TTT 的动作输出很接近;差异出现在抓取之后,未做 TTT 的模型继续往下走,像是没有意识到物体已被夹住、机械臂受桌面阻挡,而 TTT 版本选择向上抬起。2
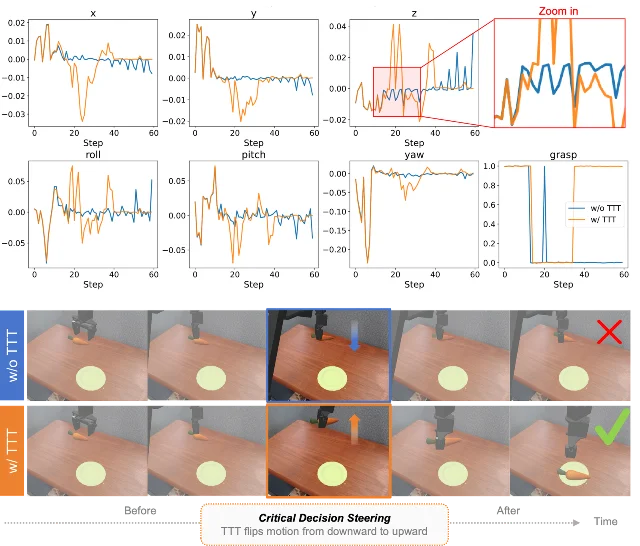
这和机器人任务的结构很吻合。很多操作不是连续均匀难,而是卡在阶段切换:是否已经抓住、是否已经对齐、是否该释放。latent prompt 如果能吸收当前环境里的状态线索,就可能在这些节点上把动作推向更合适的一边。
附录里的 episode-aligned 对比也支持这个判断。单一本体 WidowX 的 800 个 episode 中,baseline 成功 508 个,TTT 后成功 539 个,净增 31 个;同时有 145 个从失败变成功,也有 114 个从成功变失败。2 这不是单向魔法。prompt 优化会纠错,也会引入回退,只是净效应为正。
局限:它还没证明能进真实机器人现场
论文把限制写得比较清楚。第一,TTT-VLA 没有做完全真实世界部署评测。作者解释说,真实世界测试时训练要在目标环境中采集新交互数据,这会带来交互成本、系统稳定性和评测协议问题。2
第二,当前只验证了 state grounding 这一种 proxy task。未来状态预测、未来图像预测、表征预测、逆动力学预测都可能作为候选,但论文没有系统比较。2 第三,online TTT 仍不稳定,小 batch 更新会导致 prompt collapse;作者把 proximal constraints、trust-region objectives、prompt-norm regularization、micro-batch accumulation 列为后续方向。2
读这篇论文时,最好把 TTT-VLA 看成一个接口实验:能否把部署时学习限制在一个小而可控的条件变量里。它没有解决机器人现场适应的全部问题,也没有证明 prompt-only 更新能替代 RL 或真实世界再训练。但它给出了一个清晰信号:对 VLA 来说,部署时最值得优化的未必是整套策略参数,可能是那个承载环境上下文的小接口。
围绕这条内容继续补充观点或上下文。