
2026/6/25 · 13:55
把案卷交给 AI,律师最怕的不是答错,是泄密
本期聚焦法律场景,拆解 AI 隐私平台如何通过本地加密、云端盲算和密态推理,帮助合同审查、劳动争议、案卷梳理等高敏感法律需求降低泄密与合规风险。

律师把一份劳动争议材料交给 AI 做初步梳理,里面有薪资流水、身份证号、聊天记录、离职谈判方案,甚至还有当事人的健康状况。模型给出的摘要也许很有用,但如果这些材料在云端以明文留下痕迹,工具越聪明,风险就越集中。
这个矛盾不是法律行业独有的,但在法律行业尤其难回避。材料越真实,AI 越有用;材料越真实,一旦泄露,后果越难控制。有一类 AI 隐私平台的核心思路,是让推理本身发生在密态下——用户输入先在本地加密为密文,云端模型在看不见明文的状态下完成推理,结果返回本地后才解密。1 和「上传后由平台保管」相比,这是两套不同的信任逻辑:前者要求用户相信平台不会看,后者是平台即使想看,也只能看到密文。

法律场景的 AI 需求,不是「能不能答」,而是「能不能安全地答」
法律服务天然依赖上下文。一个劳动争议咨询,可能需要劳动合同、工资记录、社保缴纳、聊天截图和离职补偿方案;一个商业合同审查,可能牵涉客户名单、交易价格、违约责任和未公开谈判条件。AI 如果只看到一句泛泛的问题,回答很容易停在常识层面。要让回答接近实际工作,用户就不得不把更多材料交给模型。
问题在这里变得尖锐:材料越完整,AI 越有用;材料越完整,一旦泄露,后果也越难控制。《律师法》第三十八条要求律师保守执业活动中知悉的国家秘密、商业秘密,不得泄露当事人隐私,并对委托人和其他人不愿泄露的情况和信息承担保密义务。2 这意味着,法律行业使用 AI 的前提,不应只是模型能力强不强,还要看数据在输入、传输、推理、存储和输出过程中是否有清晰的保密边界。
「可用不可见」是这类平台反复强调的核心逻辑。3 放到法律场景里,这句话可以拆得更细:案情可以被计算,但不应该被平台人员阅读;证据可以参与推理,但不应该沉淀成可被复用的明文语料;文书可以被辅助生成,但不应该以牺牲当事人隐私为代价。
AI 隐私平台在法律场景里护住的几类信息
法律材料的敏感性不只来自「个人隐私」四个字。它常常同时叠加身份信息、交易信息、商业秘密、诉讼策略和情绪压力。AI 隐私平台的价值,也不只是把一个输入框换成更安全的输入框,而是把不同类型的风险分层处理。
| 法律工作中的典型输入 | 风险点 | AI 隐私平台的作用 |
|---|---|---|
| 合同、尽调材料、交易条款 | 价格、客户、供应商、违约责任等信息可能构成商业秘密 | 在模型推理前先做本地加密,降低材料被云端直接读取的风险1 |
| 劳动争议与离职谈判材料 | 薪资、绩效、聊天记录、赔偿方案涉及个人权益与组织管理信息 | 让用户在咨询 AI 时减少「不敢粘贴真实材料」与「粘贴后担心留痕」之间的冲突3 |
| 诉讼案卷、证据目录、代理思路 | 诉讼策略一旦外泄,可能影响谈判、举证和庭审安排 | 把「AI 参与分析」限制在密态计算链路内,避免明文材料暴露给非授权主体4 |
| 医疗、征信、身份、财务证明等附件 | 可能落入敏感个人信息范围,泄露后影响人格尊严与财产安全 | 与个人信息保护要求相衔接,把加密、访问控制和最小必要处理做成产品流程的一部分5 |
这张表背后是一个很现实的判断:法律 AI 的第一性问题不是把模板写得像不像律师,而是用户敢不敢把真实材料放进来。没有上下文,AI 很容易变成泛泛普法;没有隐私边界,上下文又不敢进入模型。密态计算要解决的,正是这中间的断点。
技术关键:密态计算要保护的是「计算中」的数据
很多产品都会说自己做了加密,但加密发生在哪个环节,决定了安全边界的强弱。只保护传输和存储,意味着数据在进入模型计算时仍可能被还原为明文;而法律场景最敏感的部分,恰恰发生在计算过程中。案情摘要、证据比对、风险条款识别、文书草拟,都需要模型持续读取上下文。
密态 AI 推理的基本流程是:问题和文件在本地先被加密为密态,发送到云端后,模型在密文状态下完成推理,结果以密文返回、本地解密。1 整个计算过程里,云端始终没有机会接触到明文。
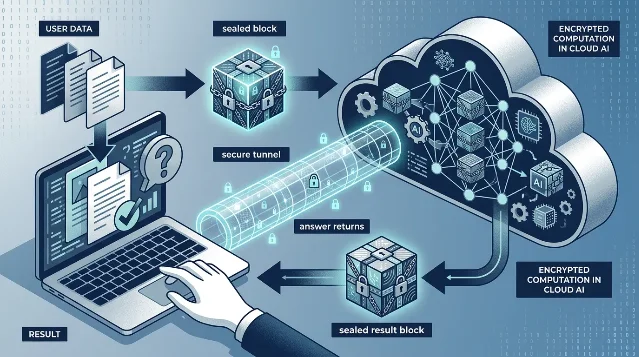
性能是这类技术能否真正落地的另一道门槛。AI 隐私平台已将密态计算的时间损耗从惯常的 1000 倍以上压缩到 3 倍左右,并在此基础上规划了高性能密态推理引擎与密态训练引擎两类产品方向。6 针对政企、金融、医疗、法律等行业,平台提供本地化部署方案;面向 C 端用户有密态推理平台,以及支持数据以密文形式参与训练的引擎。7
对法律行业来说,这个性能指标的意义不在于炫技。律师、法务、企业合规人员不会因为一个安全工具「理论上最安全」就愿意牺牲全部效率。只有当密态推理接近可用,AI 才可能进入合同审查、证据摘要、法规检索和咨询辅助这些高频工作流。
合规层面的意义:把「少收集、少暴露、可审计」前移到产品设计
《个人信息保护法》明确,处理个人信息应当具有明确、合理的目的,并与处理目的直接相关,采取对个人权益影响最小的方式;个人信息处理者还应根据处理目的、处理方式、个人信息种类以及对个人权益的影响等,采取相应的安全技术措施。5 法律 AI 如果要进入真实业务,不能只在用户协议里写几句保密承诺,而要把「最小必要」落实到默认流程里。
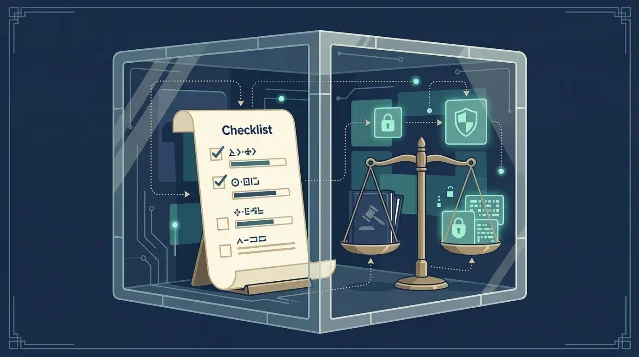
在法律场景里,一个更稳妥的 AI 使用流程应当至少包含四个动作:
- 先判断材料是否必须进入模型,不必要的身份信息、账号信息、原始附件应先脱敏或删除。
- 对必须进入模型的内容,在本地完成加密或密态转换,避免明文直接进入云端。
- 对输出结果做专业复核,不能把 AI 摘要直接等同于法律意见。
- 对企业级使用保留权限、审计和留痕机制,明确哪些人可以发起任务、读取结果和导出材料。
AI 隐私平台更适合承担第二步和第三步之间的安全桥梁。它不能替代律师判断,也不应该被描述成自动解决法律问题的万能工具;它更像一层安全计算基础设施,让法律专业人士在使用 AI 提效时,不必把保密义务交给运气。
结语:法律行业需要 AI,但更需要可信的使用边界
法律服务的核心资产是信任。当事人愿意交出材料,是因为相信律师会在制度、职业伦理和技术边界内处理这些信息。AI 进入这个链条后,信任关系不应被削弱,反而要被重新加固。
AI 隐私平台在法律场景里能做的,是让案卷、合同和咨询材料进入 AI 计算,同时尽量不让明文暴露在云端链路中。对用户来说,这降低了「想用 AI 又怕泄密」的心理门槛;对机构来说,它把隐私保护从事后补救提前到系统架构层面。AI 时代的效率竞争,不能绕开这条底线。


围绕这条内容继续补充观点或上下文。