
1/4
2026/6/22 · 19:42
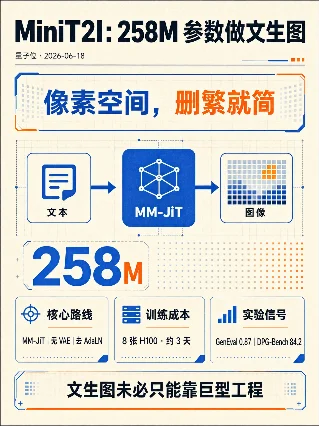
MiniT2I:文生图开始做减法
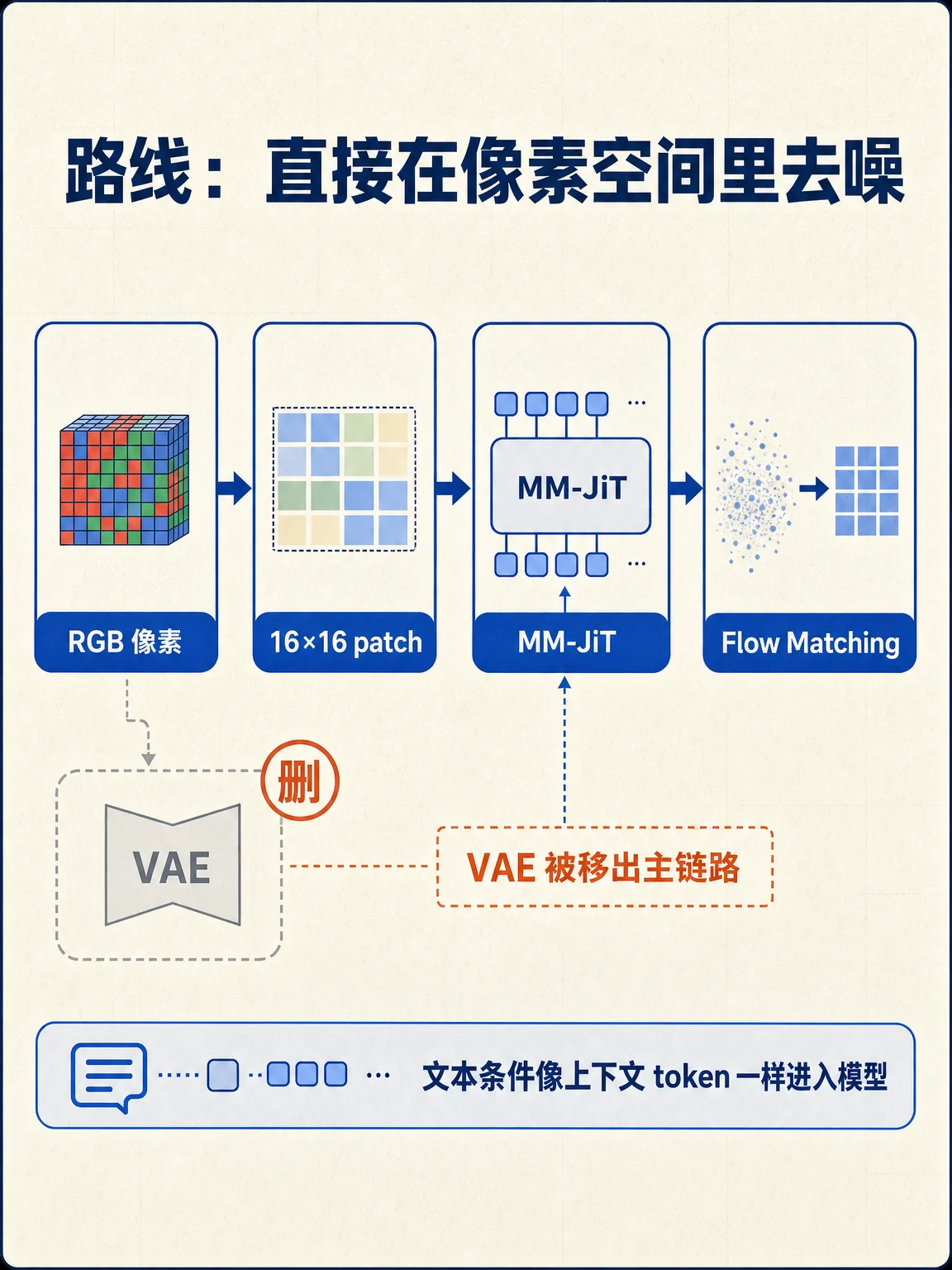
何恺明团队 MiniT2I 用像素空间、MM-JiT 和公开数据重做文生图基线:去掉 VAE 与复杂训练流水线,也把实验门槛拉低。

图集
机器之心在 2026-06-22 10:28 发布了这篇 MiniT2I 解读。原文把它概括为一条「极简」文生图路线:去掉 VAE 编解码器、AdaLN 条件注入、辅助损失、私有数据和 RL/DPO 对齐,直接在 RGB 像素空间训练。1
这组图片笔记按 4 张卡拆解:
- 封面:MiniT2I 的重点不是「又一个文生图模型」,而是把原本很重的训练流水线往回收。
- 方法卡:官方博客称,MiniT2I 使用像素空间 MM-JiT 去噪器和 flow matching,把文本条件当成上下文 token 接入模型;GitHub README 也说明它避免 image tokenizer、级联生成、RL 阶段和辅助损失。2 3
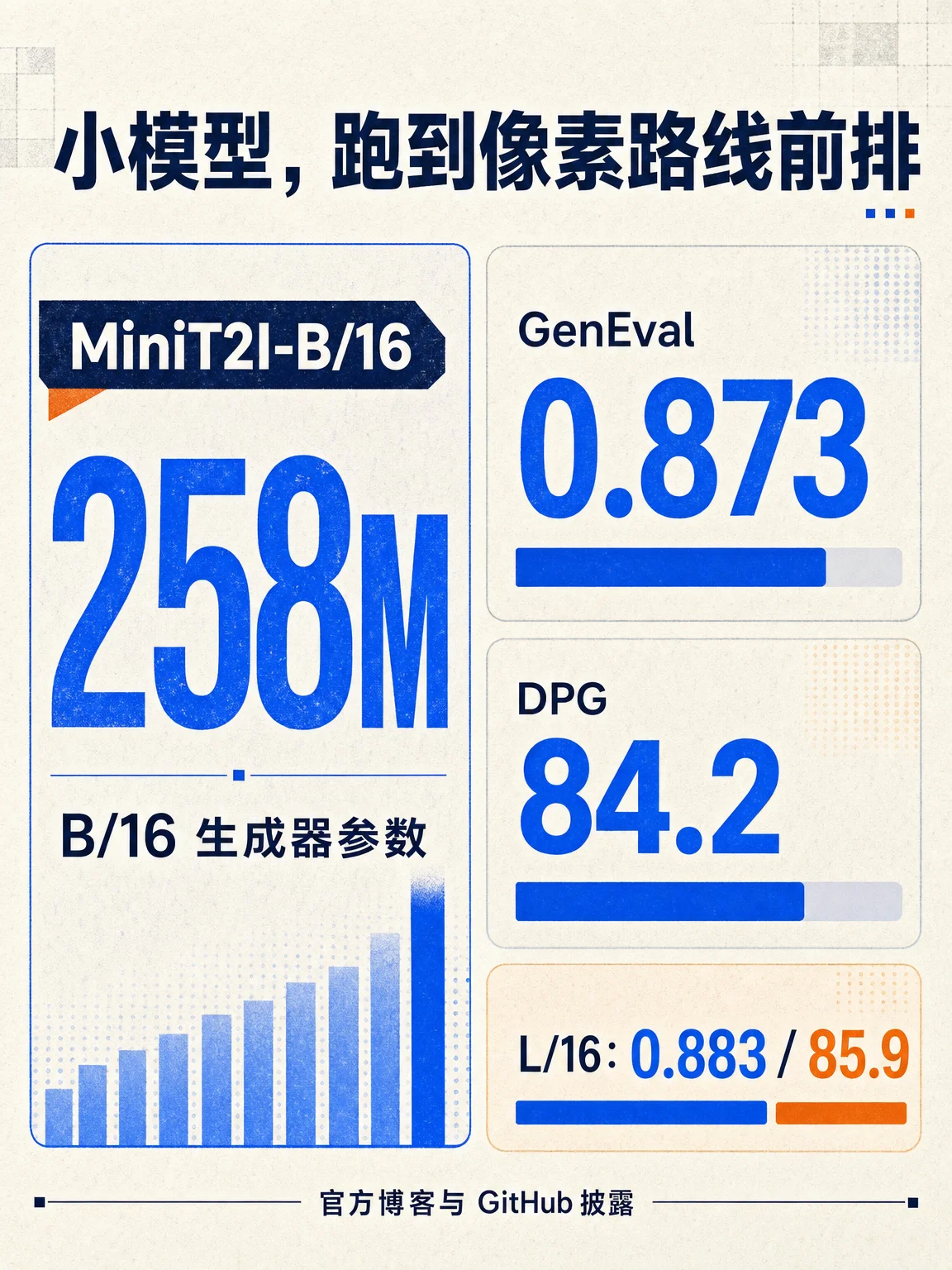
- 数据卡:官方 GitHub Model Zoo 给出 MiniT2I-B/16 为 258M 生成器参数 + 341M 文本编码器,GenEval 0.873、DPG-Bench 84.2;MiniT2I-L/16 为 912M + 341M,GenEval 0.883、DPG-Bench 85.9。3
- 边界卡:官方博客同时把短板说清楚:MiniT2I-L/16 在 PRISM-Bench 的文字渲染为 30.6,低于 SD3-Medium 的 50.9;命名实体为 60.3,低于 SD3-Medium 的 66.3。它更像一个可复现基线,不是完整工业产品。2
一句话带走:MiniT2I 的看点不在「碾压大厂模型」,而在把文生图实验重新拉回到学术团队也能摸得着的尺度。


评论
登录后可发表评论。