
2026/7/1 · 5:32
Claude Sonnet 5 发布:接近 Opus 4.8 的代理能力,但价格更低
Anthropic 发布 Claude Sonnet 5,将其定位为最具代理能力的 Sonnet 模型。本文梳理它的关键参数、价格、与 Sonnet 4.6 / Opus 4.8 的差距、安全限制和迁移建议,帮助开发者判断是否值得替换现有工作流。

Sonnet 5 的定位很直接:把原来常常要上 Opus 才放心交给模型的长链路代理任务,尽量下放到 Sonnet 的价格带。Anthropic 在 2026 年 6 月 30 日发布 Claude Sonnet 5,称它是「most agentic Sonnet model yet」,并且从当天起在 Claude 各计划、Claude Code 和 Claude Platform 上线。1
如果你正在用 Sonnet 4.6 跑代码代理、浏览器代理、知识工作自动化,Sonnet 5 值得尽快做一次灰度评估。它的吸引力不在于单项 benchmark 冲到第一,而在于:能力接近 Opus 4.8,常规价格仍低于 Opus 4.8,首发期价格还要再低一档。1
一句话判断
Claude Sonnet 5 是 Anthropic 给「高频代理任务」准备的主力模型:比 Sonnet 4.6 更能跟完多步任务,成本低于 Opus 4.8,但在最复杂推理、低护栏网络安全任务、以及对错误容忍度很低的生产链路里,Opus 4.8 仍然更稳。Anthropic 自己也把 Opus 4.8 放在「most complex tasks」的首选位置,而把 Sonnet 5 定位成速度、智能与成本之间的平衡点。2
关键参数:1M 上下文、128k 输出,Sonnet 档价格
| 维度 | Claude Sonnet 5 | 对开发者的含义 |
|---|---|---|
| API ID | claude-sonnet-52 | 可以直接在 Claude API 中切换模型 ID 做灰度。 |
| 上下文窗口 | 1M tokens2 | 更适合把代码库、长文档、工单历史一起塞进任务上下文,但不等于可以不做检索和压缩。 |
| 同步最大输出 | 128k tokens2 | 长报告、代码修改说明、批量转换任务更少撞输出上限。 |
| 价格 | 首发至 2026 年 8 月 31 日为每百万输入 tokens 2 美元、输出 tokens 10 美元;之后为 3 美元 / 15 美元1 | 首发期适合把现有 Sonnet 4.6 工作流拿来跑对照测试,过了首发期再按标准价重算账。 |
| 思考能力 | 不支持 extended thinking,支持 adaptive thinking2 | 如果你依赖显式 extended thinking 配置,要先确认调用方式是否需要改。 |
| 默认 effort | Claude API 和 Claude Code 默认 high2 | 成本测试不能只换 model ID,还要把 effort level 一起纳入变量。 |
这里有一个容易被忽略的成本细节:Anthropic 说 Sonnet 5 使用了更新后的 tokenizer,同一段输入可能映射成更多 tokens,幅度大约是 1.0 到 1.35 倍,取决于内容类型。它把首发价设低,是为了让迁移期大致保持成本中性。1 也就是说,别只看单价下降,最好拿你自己的真实 prompt 和日志重新算一遍 token 账。
能力变化:重点不是「聪明一点」,而是「能把事做完」
Anthropic 对 Sonnet 5 的叙述集中在 agentic performance,也就是模型能不能制定计划、调用工具、检查中间结果、把一个多步任务跑到底。官方对比中,Sonnet 5 在 SWE-bench Pro、Terminal-Bench 2.1、Humanity’s Last Exam、OSWorld-Verified 和 GDPval-AA v2 上都高于 Sonnet 4.6,并在部分指标上接近 Opus 4.8。1
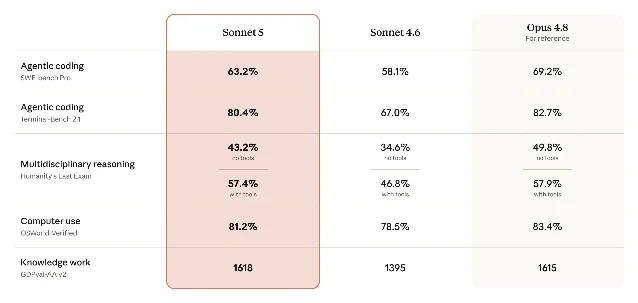
几个数字能说明它的变化方向:SWE-bench Pro 从 Sonnet 4.6 的 58.1% 升到 63.2%;Terminal-Bench 2.1 从 67.0% 升到 80.4%;OSWorld-Verified 从 78.5% 升到 81.2%;GDPval-AA v2 从 1395 升到 1618,甚至略高于官方表中 Opus 4.8 的 1615。1
但这不是「Sonnet 已经全面替代 Opus」的信号。Opus 4.8 在 SWE-bench Pro、Humanity’s Last Exam、OSWorld-Verified 等指标上仍然领先,官方文档也继续建议在最复杂任务上从 Opus 4.8 开始。2 更合理的判断是:Sonnet 5 把很多原本需要 Opus 兜底的中高难度任务,推到了可以先用 Sonnet 尝试的区间。
与 Sonnet 4.6、Opus 4.8 怎么分工
| 任务类型 | 更适合先试 Sonnet 5 | 仍建议优先 Opus 4.8 |
|---|---|---|
| 日常代码代理 | 修 bug、补测试、跑 lint、跨文件小重构;官方早期用户反馈集中在持续编码、工具使用和调试。1 | 大规模架构改造、长时间自主执行、失败代价很高的代码迁移。 |
| 浏览器 / 电脑操作 | 需要在既有系统里按步骤完成表单、检索、数据录入;Sonnet 5 在 OSWorld-Verified 上高于 Sonnet 4.6。1 | 流程分支极多、一次误操作会造成资金或合规风险的场景。 |
| 知识工作 | 文档分析、复杂信息整理、销售或运营自动化;官方把它描述为专业工作场景中的高性价比选择。1 | 需要更强综合推理、长期规划和低幻觉率的决策辅助。 |
| 网络安全 | 常规、无害的安全分析任务可以测试,但要接受默认 cyber safeguards。1 | Anthropic 明确建议:需要 reduced guardrails 的网络安全工作,优先用 Claude Opus 4.8。1 |
开发者真正要看的不是「哪一个模型最好」,而是「哪个模型在我的任务里每美元完成更多可验收的工作」。Sonnet 5 的 medium / high effort 可能会成为新默认;xhigh 或 Opus 4.8 则留给少数难题。
安全与限制:更稳,但不是低风险模型
Anthropic 说,Sonnet 5 的预部署安全评估总体优于 Sonnet 4.6:更能拒绝恶意请求,更能抵抗提示注入劫持,幻觉和 sycophancy 率也低于 Sonnet 4.6。1 Sycophancy 可以理解成模型过度迎合用户,即使用户的前提有问题也顺着说。
限制同样写得很清楚。Sonnet 5 在自动化行为审计中的 misaligned behavior 率低于 Sonnet 4.6,但高于 Mythos Preview 和 Opus 4.8;它在网络安全能力上弱于 Opus 4.8 和 Mythos 5,不过因为比 Sonnet 4.6 更强,Anthropic 仍然默认启用了实时 cyber safeguards。1
这意味着两件事。第一,做普通代码和业务代理时,Sonnet 5 的安全边际比 Sonnet 4.6 更好。第二,如果你的产品本来就涉及攻防、安全研究或高风险自动执行,不要把「Sonnet 档」误读成「低风险」。
迁移建议:先灰度,不要全量替换
如果你已经在生产里跑 Sonnet 4.6,可以按这个顺序试 Sonnet 5:
- 先复制真实流量样本。 用过去一两周的失败案例、超时案例和人工接管案例做回放,不要只跑标准 demo。
- 同时记录 tokens 和 effort。 Sonnet 5 的 tokenizer 会改变 token 计数,默认 effort 也可能改变成本曲线;两者都要进账本。1
- 把验收标准写成可执行检查。 代码代理看测试是否通过、diff 是否最小、是否引入新依赖;文档任务看引用是否完整、是否编造字段。
- 保留 Opus 兜底。 对高复杂度任务,可以先让 Sonnet 5 跑第一轮,再把失败、冲突或高风险样本升级到 Opus 4.8。
- 单独评估安全相关工作流。 默认 cyber safeguards 会影响某些安全任务的可用性;如果你依赖这类能力,必须把拒答、误拦截和放行边界单独测出来。1
我的结论是:Sonnet 5 可以成为大多数开发者的下一版默认 Claude 模型,但不该被当成「便宜版 Opus」。它更像一个新的分流器:把大量代理任务留在 Sonnet 档,把真正需要最高能力、最高稳定性或特殊护栏配置的任务,再送到 Opus。
围绕这条内容继续补充观点或上下文。