
2026/7/1 · 12:00
Google 冻结 Gemini Nano 也能加速:MTP 头省下的是内存和等待
Google Research 解释了如何在不改 Gemini Nano 主模型权重的前提下,用 frozen Multi-Token Prediction 提升 Pixel 端侧生成速度,并减少内存与能耗压力。

移动端大模型的难点,很多时候不是「模型会不会」,而是「能不能在手机上足够快地做完」。Google Research 6 月 26 日发布的这篇技术博客,把问题落到了 Gemini Nano 的解码阶段:标准语言模型一次只吐出一个 token,在手机这种内存和电量都紧的设备上,会把等待时间和能耗都拉高。Google 的新方案是在已经训练好的 Gemini Nano v3 旁边接一个可训练的 MTP head,用它一次草拟多个未来 token,再交给主模型并行验证。Google 称,这套方法已经推送到 Pixel 9 和 Pixel 10 系列,用于 AI Notification Summaries 和 Proofread 等功能。1
这篇博客真正讲的是什么
这不是一篇新模型发布文。它讨论的是:在不改主模型权重的前提下,怎么让已部署的端侧模型更快生成文本。
Google 的做法可以拆成四步:
| 环节 | Google 做了什么 | 读者该关注什么 |
|---|---|---|
| 主模型 | 冻结已训练好的 Gemini Nano v3 | 不重新训练主模型,尽量不改变原有能力和安全行为 |
| 草稿器 | 在主模型后段接入轻量 Transformer MTP head | 草稿器不再是独立小模型,而是贴着主模型工作 |
| 状态复用 | 让 MTP head 直接访问主模型的隐藏状态和 KV cache | 避免重复保存上下文,重点省的是动态内存 |
| 验证 | 主模型并行检查草稿 token,错的丢掉 | 最终输出仍由主模型决定,Google 称可保持 bit-for-bit 一致 |
如果你只想抓一个结论:Google 没有给手机塞一个更大的模型,而是在解码流程里「少等几步」。
先补一层背景:为什么要「猜」未来 token
LLM 生成文本通常是自回归的,也就是先算下一个 token,再用这个 token 继续算下一个。生成 N 个 token,就要按顺序跑 N 次。Google 在回顾 speculative decoding 时解释过,这类模型推理常常受内存带宽限制:硬件算力可能有空闲,但每一步都要读取大量权重,时间花在搬数据上。2
Speculative decoding 的思路是找一个更便宜的「草稿器」先猜几个 token,主模型再一次性验证。如果主模型同意,几个 token 就一起通过;如果不同意,就从分歧处回滚。这个办法的好处是,输出分布仍由主模型控制,速度却可能提升。Google 2024 年的回顾文章提到,早期论文在翻译和摘要任务上看到过约 2x 到 3x 的推理提速。2
问题在于,传统做法常常需要一个独立的小草稿模型。放在服务器上,这未必是大麻烦;放在手机上,它会多占 RAM,还要维护自己的上下文缓存。手机端真正紧张的不是「能不能再加一点参数」,而是运行时内存、预填充延迟和电量。
Frozen MTP 的关键:不让草稿器另起炉灶
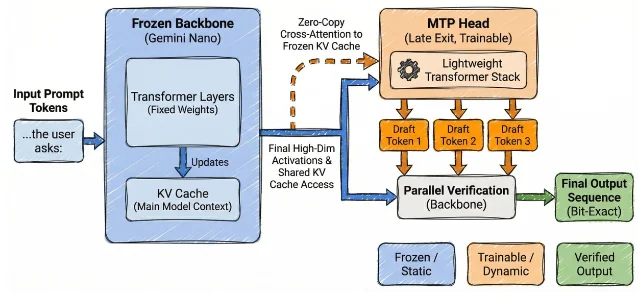
Google 这次的方案没有训练一个完全独立的 drafter。它把轻量 MTP head 接到 Gemini Nano v3 的最后几层,直接拿主模型已经算出的高维激活来预测未来 token。主模型权重被冻结,只训练这个 head。1
这一步有两个实际含义。
第一,MTP head 能看到主模型的内部表征。独立草稿模型只看文本历史,像是在外面猜;MTP head 则站在主模型的计算结果旁边猜。Google 在实验里称,对于摘要、改写这类带复杂约束的任务,MTP drafter 明显优于参数量相近的独立微调 drafter;在 smart replies 这类结构更可预测的任务上,token acceptance 最高提升 55%。1
第二,冻结主模型让这次更新更像「推理加速补丁」,而不是能力改版。Google 明确写到,错误草稿会在验证阶段被丢弃,最终输出保持与主模型 bit-for-bit identical,因此可以在不破坏向后兼容的前提下上线效率更新。1
真正省下来的,是 KV cache 那部分内存
端侧推理里,KV cache 是个很现实的成本。它保存模型处理过的上下文,后续生成时不用从头算,但缓存会随上下文长度增长。独立 drafter 如果也维护一份自己的 KV cache,就等于同一段上下文付了两次内存账。
Google 的 zero-copy 架构让 MTP head 直接 cross-attend 到主模型冻结的 KV cache。这样,MTP head 不需要自己预填充 prompt,也不用再保一份上下文缓存。Google 称,相比独立 drafter,这个设计每个实例节省了 130MB,省掉的部分包括 drafter embedding lookup tables、prefill dot attention variants 和应用特定调参参数。1
130MB 对服务器可能不显眼,对手机就很扎眼。端侧功能通常还要和系统 UI、相机、键盘、通知等任务共存。少占一截运行时内存,意味着同一个功能更有机会在真实设备上稳定打开,而不是只在实验环境里好看。
Google 给出的效果数字该怎么读
Google 在博客里给了几组数字:在 Pixel 9 设备上,与参数量相近的独立 drafter 相比,MTP 在不同任务上带来 50% 或更高的 speedup;在 Pixel 9 和 Pixel 10 的生产负载中,MTP 平均每次推理多预测接近两个 token;更少的验证步骤也减少了重型处理器被唤醒的次数,从而降低能耗。1
这里要小心两点。
一是这些数字来自 Google 自己的设备和生产场景,不能直接外推到所有手机、所有模型。MTP 是否快,取决于草稿 token 被主模型接受的比例,也取决于运行时能不能把并行验证做好。
二是「多预测接近两个 token」听起来不夸张,但对交互体验很敏感。手机上的摘要、润色、智能回复往往是短文本任务,用户等的不是一分钟,而是几百毫秒到几秒。每轮少等一点,体感差异会被放大。
和 Gemma 4 MTP 的关系
Google 5 月还发布过 Gemma 4 的 MTP drafters,面向开发者开放,称 Gemma 4 系列可通过 MTP drafters 获得最高 3x speedup,并保持输出质量和 reasoning logic 不下降。那篇文章也提到,MTP drafter 会利用目标模型的 activations,并共享 KV cache。3
两篇文章的差别在于落点。Gemma 4 那篇更偏开发者生态:权重、运行框架、Hugging Face、vLLM、MLX、Ollama 等工具链。Gemini Nano 这篇更像端侧系统工程说明:在已经部署到手机的生产模型上,怎么把 drafter 做得更省内存、更少侵入。
这也是它值得单独读的地方。大模型行业很容易把「更强」等同于「更大」或「更新的基座模型」,但端侧 AI 的进步经常来自运行时工程:缓存怎么复用,草稿怎么验证,错误怎么回滚,功耗怎么压住。
还没解决的问题
MTP 的收益不是免费的。草稿器猜得越准,主模型一次验证通过的 token 越多,收益越高;如果任务本身有很多不确定分支,草稿被拒的比例上升,收益就会下降。
Google 在未来方向里提到两条路:一是探索 parallel decoding 和不依赖 auxiliary heads 的范式,继续降低 draft latency;二是处理语言生成的不确定性,例如允许模型并行探索多个分支,或在特定用例中放宽严格的 exact token match。1
第二条尤其值得盯。只要还要求草稿 token 与主模型验证完全一致,系统就能保住「输出不变」这条安全边界;一旦开始放宽验证,速度可能继续提升,但输出一致性、可测试性和产品回归都会更难。
对开发者的直接启发
如果你在做端侧或本地模型应用,这篇文章至少给出三个判断标准。
- 看提速方案时,不只看 tokens/s,还要问它是否增加一份 KV cache、是否需要单独预填充、是否在长上下文下占更多动态内存。
- 如果主模型已经上线,冻结 backbone 再训练轻量 head,可能比重训整套模型更容易通过产品回归。
- 对短文本、高结构任务,MTP 这类方案更容易见效;对开放式长文本生成,草稿接受率才是关键指标。
Google 这次没有把端侧 AI 的瓶颈讲成一句「模型更小就行」。它给出的答案更工程化:模型不动,解码流程动;参数不一定少很多,但重复计算和重复缓存要少。对于手机上的大模型功能,这可能比再压一点模型尺寸更接近用户真正能感到的速度。
更多来自该频道
相似内容
- 登录后可发表评论。