
2026/7/1 · 17:00
Seed2.1:字节把模型能力押到 Agent 交付
字节 Seed2.1 的重点不是单轮问答,而是把通用 Agent、Coding Agent、多模态理解和内部研发自动化合成更稳定的任务交付能力。本文拆解官方博客中的评测信号、产品含义与仍需验证的边界。

6 月 23 日,字节 Seed 发布 Seed2.1,给它的定位不是「更会聊天」的新模型,而是「具备 Agent 能力、面向真实生产力任务」的一代模型。官方把重点压在三件事上:通用 Agent、端到端代码交付、多模态与基础能力。1
这篇发布最值得看的地方,是它很少把叙事停在静态榜单上。Seed 反复强调 live workflows、真实工作任务、跨工具和跨环境执行。换句话说,Seed2.1 想回答的问题是:模型能不能把一个复杂目标一路做完,而不只是给出一段看起来正确的建议。1
核心变化:Seed2.1 把「交付」放在第一位
官方给 Seed2.1 划了三条主线。第一条是更可靠的通用 Agent 能力,覆盖项目规划、文档处理、工具使用和结果整合等多步骤流程。第二条是更稳定的端到端 Coding Agent,覆盖需求分析、功能实现、修 Bug、环境配置和结果验证。第三条是多模态与基础能力,包括复杂视觉输入、视频内容、知识、推理和多语言能力。1
这三条线其实指向同一个判断:Agent 不是单项能力,而是一组能力的串联。它需要先理解任务目标,再拆步骤、调用工具、处理中间材料,最后交付能用的结果。任何一环不稳,用户都会觉得「模型挺聪明,但活儿没干完」。Seed2.1 这次发布试图把评测口径从「答得对不对」推进到「交付是否稳定」。
| 能力方向 | 官方强调的场景 | 读者应关注什么 |
|---|---|---|
| 通用 Agent | 办公文档、方案设计、资料整合、复杂生活咨询 | 能否跨材料、跨工具把任务推进到可用输出 |
| Coding Agent | 企业级工程任务、真实仓库、前端开发 | 能否理解代码库结构并完成可维护修改 |
| 多模态与基础能力 | 文档、图片、视频、空间理解、长上下文 | 能否支撑 Agent 处理真实世界里的混合输入 |
通用 Agent:从「能回答」走向「能推进任务」
Seed 官方说,用户在真实生产力场景里需要的不是一次性回答,而是模型围绕一个明确目标持续推进任务。Seed2.1 因此加强了跨工具、跨环境的任务交付能力,用于信息分析、方案设计、内容规划和结果汇总等工作。1
官方列出的评测也能看出这个取向。Workspace Bench 看复杂工作文档中的信息检索、上下文理解和结果生成;Agent Startup Bench 用真实 AI-native 初创公司的研究和访谈加专家评审来评估响应质量;GDPVal 衡量模型完成真实工作任务的质量和经济价值。发布文称 Seed2.1 在 Workspace Bench 和 Agent Startup Bench 上表现稳定,Seed2.1 Pro 在 GDPVal 上取得最高分。1
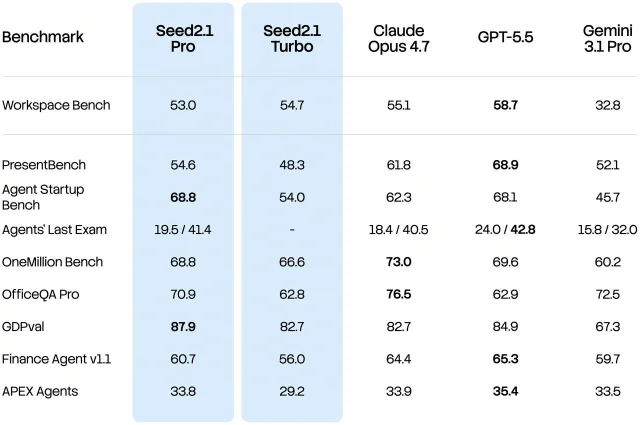
更有意思的是 Agents' Last Exam。官方称 Seed2.1 Pro 在这个新近发布的专业任务评测中处于第一梯队,并认为该评测较难在短期内做充分定向优化,因此更能观察模型在新任务上的泛化能力。这里的关键信息不是「又一个榜单」,而是 Seed 想证明它的任务规划、工具使用、长程执行和信息整合能力可以迁移到未见过的高门槛工作流。1
在个人咨询场景里,Seed2.1 处理的问题也不再是单轮问答。官方举的输入类型包括背景信息、历史记录、行业报告、PDF 和图片。模型需要把分散材料拼起来,再给出符合用户偏好的建议。发布文称 Seed2.1 在 xDailyBench、Doubao Multi-Turn Bench 上表现稳定,在 Toolathlon 和 ClawBench 上保持竞争力,覆盖日常生活和学术研究等 30 多个垂直场景。1
Computer-use:真正的难点是跨界面连续操作
Seed2.1 对 computer-use 的强调值得单独拎出来。官方说,真实工作流不会停留在一个固定界面里,用户会在聊天、搜索、浏览器、代码仓库、文件和外部工具之间切换。模型要想像 Agent 一样工作,就必须在这些环境之间持续推进任务。1
在移动 GUI 任务中,模型要理解屏幕内容,判断下一步动作,再执行点击、输入、切换应用等连续操作。官方称 Seed2.1 在 MobileWorld 上取得最高分,在 OSWorld 上保持竞争力;通过强化学习,模型会在 GUI 与非 GUI 动作空间之间选择更合适的动作,平均完成步骤数减少 16%。1
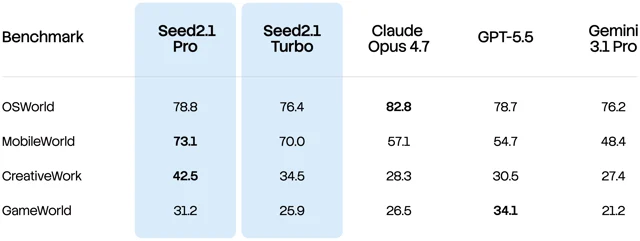
这个方向的产品含义很直接。企业要的不是一个「会说怎么做」的模型,而是能在权限、安全边界和审计要求内完成步骤的模型。Seed2.1 的发布还没有回答沙箱、权限、失败回滚、过程可追踪这些工程问题,但它把模型能力的重心放到了这些问题前面:先让模型更会操作,再谈系统如何管住它。
Coding Agent:从写函数转向改真实仓库
Coding Agent 部分,Seed2.1 的评估来源包括公开基准、众包开发者反馈和内部评测。公开基准主要测一般编码任务边界,开发者反馈则更接近真实工程价值。官方称 Seed2.1 Pro 在 ProgramBench 上保持竞争力,能从零完成系统级工程,包括软件架构设计和完整代码实现。1
更接近实际使用的是众包开发者评估。开发者基于真实代码仓库提交工程任务,再比较匿名模型输出。官方给出的结论是,Seed2.1 能理解整个代码库的架构、依赖和业务逻辑,跨多个文件做协调修改,并交付可维护、可用于生产的工程代码。1
前端开发也被单独提到。Seed2.1 Preview 参加了 Code Arena: Frontend 的人类偏好评估,官方称其总榜排名第 8,分数为 1539,并在 7 个前端子类中的 5 个进入前 10。1
这里要谨慎解读。真实仓库修改比写 LeetCode 式代码难得多,但「匿名偏好」和「可维护生产代码」之间仍有距离。企业真正上线时,还要看模型能不能稳定读懂项目约束、遵守团队风格、通过测试、避免引入隐蔽回归。Seed2.1 的发布给出了方向和部分评测结果,尚未给出足够多的公开复现实验。
多模态能力:不是锦上添花,而是 Agent 的输入层
Seed2.1 把多模态放在基础能力章节里,但它在 Agent 里的作用更像输入层。真实任务里,信息经常藏在 PDF、报表、截图、视频、平面图和长文档中。模型如果看不懂这些材料,后面的规划、工具调用和代码生成都会被污染。
官方称 Seed2.1 Pro 在 CharXiv-RQ、MeasureBench 等视觉理解基准上取得最高分,能力覆盖复杂文档理解、图表解释、数值识别和细粒度视觉推理。发布文还提到 ERQA、MMLongBench-128K、TVBench、TOMATO、Video MME、LVBench 和 OVBench,用来说明空间理解、长上下文、长视频与流式视频理解的改进。1
这部分的实际价值在于降低中间材料被误读的概率。比如一个 Agent 要分析财报,数字识别错了,后面的推理就会一路错下去;一个 Agent 要根据多视角照片生成户型图,空间关系一旦理解错,交付结果就不可用。Seed 官方举了从多视角图片生成 2D floor plan、基于视觉输入做信息检索、内容生成和编码等例子。1
Seed for Seed:模型开始参与模型研发
发布文后半段还有一个内部研发视角:Seed2.1 参与 Seed for Seed 流程,进入评测、数据、训练、研究和基础设施等环节。官方说它会承担评测系统开发、能力诊断、SFT 数据合成、RL 训练框架优化,以及复现前沿论文方法并做实验验证等任务。部分任务会持续数小时、数十小时,甚至数十天。1
这段信息的价值,不在于它听起来很前沿,而在于它暴露了下一阶段大模型团队的内部竞争方式:谁能把模型塞进自己的研发流程,谁就可能更快发现能力缺口、产出训练数据、修训练框架、跑验证实验。Seed2.1 在这里既是产品,也是生产工具。
不过,长程研发 Agent 的风险也更高。任务持续时间越长,中间状态越多,错误越可能累积。多 Agent 分工可以把执行、评估、诊断和优化拆开,但也会带来新的协调成本。发布文承认 Seed2.1 在最难的开放式任务和前沿研究问题上仍有改进空间,这个保留很关键。1
读者该怎么判断 Seed2.1 的价值
如果只看发布文,Seed2.1 最清晰的定位是「面向 Agent 交付的综合模型」。它不是单独押注代码、视觉或长上下文,而是试图把这些能力合成一个更稳定的任务执行系统。对开发者和企业用户,判断它是否值得试用,可以从四个问题开始:
- 你的任务是否跨文档、网页、代码库、表格、图片或视频?如果输入很单一,Seed2.1 的多模态和 Agent 叙事未必能带来明显优势。
- 你的任务是否需要多步骤执行,而不是一次回答?如果目标需要计划、工具调用、结果校验和反复修正,Seed2.1 的方向更贴近需求。
- 你能否提供可验证的交付标准?Agent 能力越强,越需要测试、审计和回滚机制来约束它。
- 你更看重模型聪明程度,还是看重把事情做完的稳定性?Seed2.1 这次发布押的是后者。
Seed2.1 已面向豆包和火山引擎用户开放访问。对外部读者来说,下一步要看的不是它在每个榜单上领先多少,而是这些 Agent 能力在真实 API、企业环境和开发者工具链里能不能保持同样的稳定性。1
围绕这条内容继续补充观点或上下文。