

1/4
2026/6/28 · 14:19
训练数据如何长出能力?MDA 溯源模型电路
机器之心文章图片笔记:用四张卡看懂 MDA 如何把训练数据、归纳头等内部机制与 ICL 行为变化连成一条可干预的因果链。

这套图片笔记提炼自机器之心 2026-06-28 12:58 发布的文章:北大与智源团队提出「机理数据归因」MDA,把问题从「模型内部有什么机制」推进到「这些机制由哪些训练数据塑造」。1
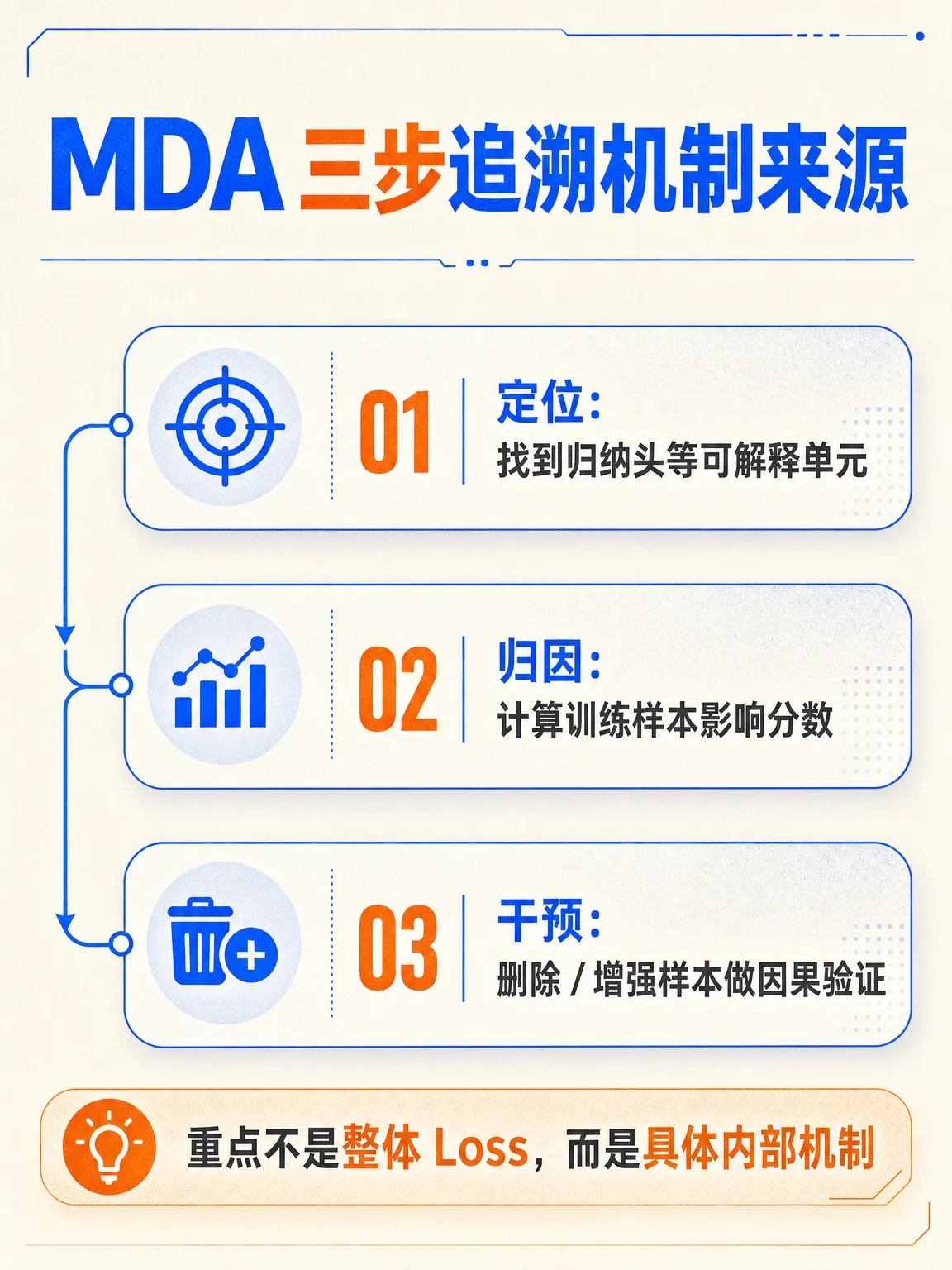
论文摘要称,MDA 用影响函数把可解释单元追溯到具体训练样本,并通过删除或增强高影响样本来验证机制形成的因果来源;arXiv 页面显示该论文题为「Mechanistic Data Attribution: Tracing the Training Origins of Interpretable LLM Units」,备注为 ICML2026 Oral。2
图集顺序:
- 问题入口:训练数据如何塑造模型能力。
- 三步框架:定位可解释单元、计算影响分数、做删除/增强干预。
- 反直觉发现:原文称 XML/HTML、LaTeX、UUID/日志、Base64 等重复结构数据,对归纳头形成更像「训练题」;文章还称约 10% 样本贡献了 50% 累计影响力。1
- 为什么重要:论文摘要称,机理数据增强可在不同模型规模上加速电路收敛,为更主动地引导大模型训练提供方法线索;项目仓库也给出了 MDA 的环境配置、影响分数计算与样本检查脚本。23
一句话带走:MDA 的价值不是把所有训练数据重新打分,而是把「某个内部机制」和「塑造它的训练样本」连成可干预的因果链。
评论
登录后可发表评论。