2026/7/1 · 12:33
Claude Sonnet 5:官方 Benchmark 横向对比
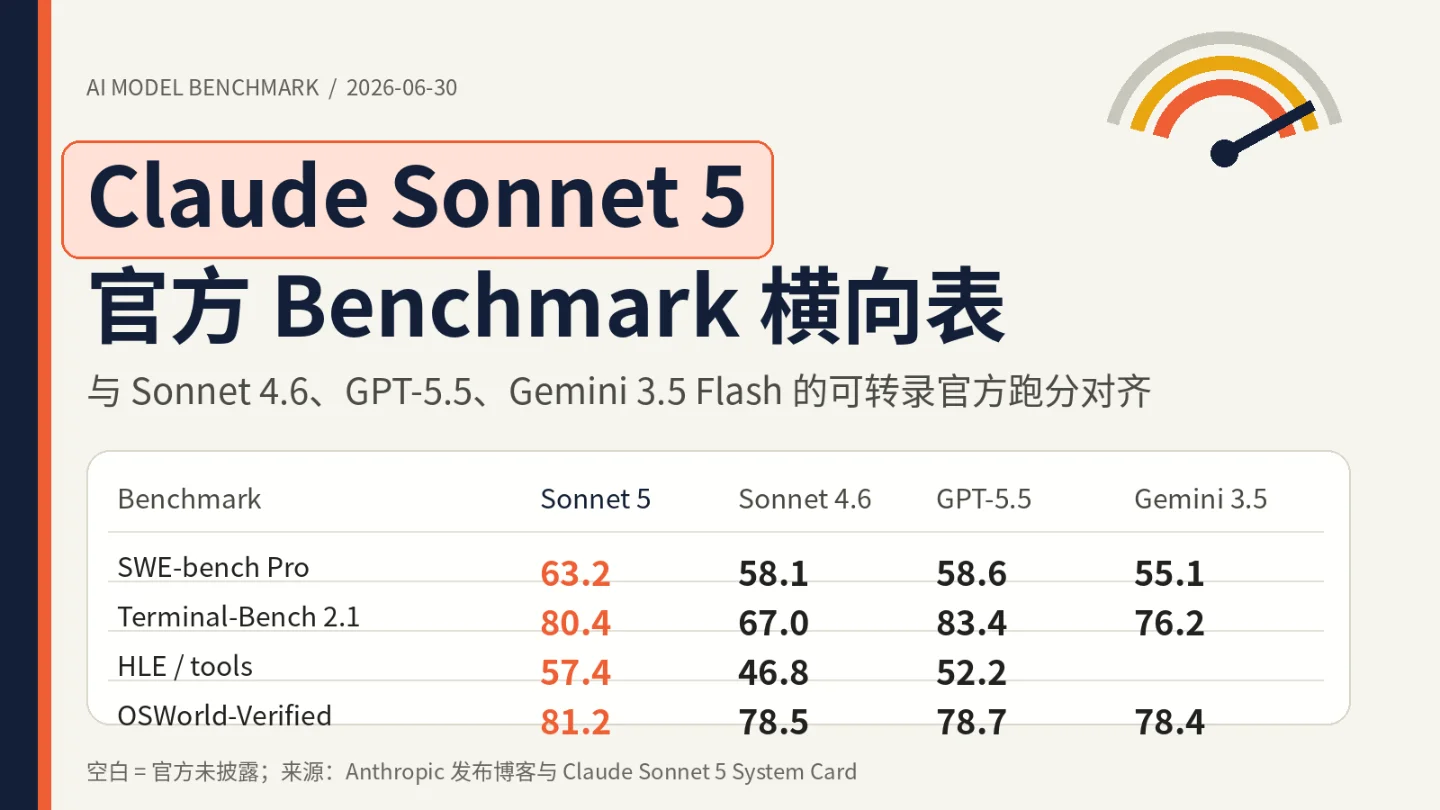
Anthropic 发布 Claude Sonnet 5 后,官方系统卡给出了与 Sonnet 4.6、GPT-5.5、Gemini 3.5 Flash 在 SWE-bench Pro、Terminal-Bench、HLE、OSWorld 等 benchmark 上的可比结果。

Claude Sonnet 5 的核心变化很清楚:Anthropic 把 Sonnet 线往 Opus 的能力区间推了一步,但仍按 Sonnet 的价格和默认可用性来卖。它在 2026 年 6 月 30 日发布,已成为 Free 和 Pro 计划的默认模型,并通过 Claude Code 与 Claude API 提供,API 名称为
claude-sonnet-5;发布期价格为每百万输入 token 2 美元、每百万输出 token 10 美元,2026 年 8 月 31 日后回到 3 美元 / 15 美元。1下面只转录官方发布博客和系统卡里能核到的数值。表格里的空白表示发布方没有披露该模型在该项上的可比数字;它不是 0,也不是落后。
全量 Benchmark 对照表
以下数据来自 Anthropic 发布博客与 Sonnet 5 System Card,已将原文三张表合并为一张。空白表示发布方未披露该模型在该项上的可比数字。各行最高值加粗;⚠️ 标注表示同一项在两份官方来源中数值有出入。21
| Benchmark / 口径 | Claude Sonnet 5 | Claude Sonnet 4.6 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.5 Flash | 其他模型 | 来源 |
|---|---|---|---|---|---|---|---|
| SWE-bench Pro | 63.2% | 58.1% | 69.2% | 58.6% | 55.1% | 21 | |
| SWE-bench Verified | 85.2% | 2 | |||||
| SWE-bench Multilingual | 78.3% | 2 | |||||
| SWE-bench Multimodal | 28.1% | 2 | |||||
| Terminal-Bench 2.1 | 80.4% | 67.0% | 82.7% | 83.4%(Codex CLI harness) | 76.2% | 21 | |
| CursorBench | 61.2% | 49.0% | 63.8% | 2 | |||
| FrontierCode v1 | 38.8% | 15.1% | 25.5% | 2 | |||
| ProgramBench(hidden test pass rate,区间) | 76–86% | 52–74% | 80–90% | Mythos 5:84–93% | 2 | ||
| BrowseComp(single agent) | 84.7% | 76.2% | 84.4% | 2 | |||
| BrowseComp(multi agent) | 86.6% | 2 | |||||
| BrowseComp(10M-token,max effort) | 84.7% | 2 | |||||
| Humanity's Last Exam(no tools) | 43.2% | 34.6% | 49.8% | 41.4% | 40.2% | 21 | |
| Humanity's Last Exam(with tools) | 57.4% | 46.8% | 57.9% | 52.2% | 21 | ||
| USAMO 2026 | 79.5% | 55.0% | 96.7% | Mythos 5:99.8% | 2 | ||
| ArxivMath(no tools) | 65.7% | 2 | |||||
| ArxivMath(with tools) | 72.2% | 2 | |||||
| OSWorld-Verified | 81.2% | 78.5% | 83.4% | 78.7% | 78.4% | 21 | |
| AutomationBench | 13.5% | 5.3% | 12.9% | 14.5% | 2 | ||
| GDPval-AA v2(Elo) | 1618 | 1395 | 1615 | 1509 | 1357 | 21 | |
| GDP.pdf(no tools,mean criteria pass rate) | 67.5% | 66.9% | 2 | ||||
| GDP.pdf(with tools,mean criteria pass rate) | 81.6% | 78.6% | 2 | ||||
| Real-World Finance v2(Elo) | 1219 | 低 219 Elo | 1222 | Fable 5 胜 Sonnet 5:69% | 2 | ||
| ChartMuseum(no tools) | 70.1% | 59.3% | 75.8% | 2 | |||
| ChartMuseum(with tools) | 86.7% | 80.9% | 89.7% | 2 | |||
| CharXiv Reasoning(no tools) | 77.0% | 71.6% | 80.5% | 2 | |||
| CharXiv Reasoning(with tools) | 88.3% | 85.3% | 89.9% | 2 | |||
| BenchCAD Vision2Code(no tools,voxel IoU) | 0.266 | 0.267 | 2 | ||||
| BenchCAD Vision2Code(with tools,voxel IoU) | 0.373 | 0.327 | 2 | ||||
| OfficeQA | 73.3% | 68.7% | 2 | ||||
| OfficeQA Pro | 59.4% | 53.4% | 2 | ||||
| HealthBench Professional | 57.8% | 44.2% | 51.8% | 2 | |||
| Legal Agent Benchmark(Full Public Set,全通过率) | ⚠️ 8.9(System Card 摘要表)/ 8.92%(System Card 细分表) | 8.0% | 2 | ||||
| Legal Agent Benchmark(Full Public Set,mean criterion-pass) | 88.26% | 88.48% | 2 | ||||
| Legal Agent Benchmark(Harvey held-out,全通过率) | ⚠️ 5.8%(System Card 摘要表有)/ 细分表无数据 | 5.4%(摘要表) | 2.1% | 0.8% | 2 | ||
| Legal Agent Benchmark(Harvey held-out,mean criterion-pass) | 91.2% | 2 | |||||
| Toolathlon(Pass@1) | 54.3% | 49.4% | 59.9% | Fable 5:61.7%;Mythos 5:61.7% | 2 | ||
| Toolathlon(Pass@3) | 63.0% | 60.2% | 67.6% | Fable 5:68.5%;Mythos 5:66.7% | 2 | ||
| Toolathlon(Pass³) | 40.7% | 38.0% | 48.1% | Fable 5:55.6%;Mythos 5:58.3% | 2 | ||
| Toolathlon(平均轮次,越少越好) | 26.0 | 16.5 | 24.5 | Fable 5:19.8;Mythos 5:19.0 | 2 | ||
| AA-Briefcase(Elo) | 1393 | 1352 | Fable 5:1586 | 2 |
只在图里披露、未完全转录的项目
系统卡还列出了 HealthBench、GMMLU、MILU、INCLUDE,以及一组生命科学评估:BioMysteryBench、LatchBio SpatialBench Verified、LatchBio SingleCellBench、结构生物学开放题、ProteinGym Hard、有机化学、protocol troubleshooting。它们在系统卡中以图形或任务组形式出现,本轮只把名称纳入覆盖清单,没有把图上所有柱形或分面数值硬读成精确小数。2
这类处理比把肉眼估算的柱状图数值写进表格更安全。下次如果发布方同时给出 CSV、排行榜 API 或表格化附录,应优先用可机读数据补齐这些空白。
读表结论
Sonnet 5 最强的卖点不是「每一项都第一」,而是把 Sonnet 线的价格带推到接近 Opus 的能力区间:GDPval-AA v2、HLE with tools、OSWorld-Verified 三项已经贴近 Opus 4.8;SWE-bench Pro、CursorBench、USAMO 仍能看到 Opus 的优势。1
和外部模型比,Sonnet 5 在 SWE-bench Pro、BrowseComp、HLE with tools、FrontierCode、GDPval-AA v2、Legal Agent Benchmark 与 HealthBench Professional 上高于表内 GPT-5.5;Terminal-Bench 2.1 上 GPT-5.5 更高,AutomationBench 上 Gemini 3.5 Flash 更高。2
真正需要谨慎的是口径。Terminal-Bench 2.1 的 GPT-5.5 用 Codex CLI harness;OSWorld-Verified 的 Sonnet 4.6 分数因 Anthropic 修改 zoom tool 和 per-turn token limit 后被更新;GDPval-AA v2 是 2026 年 6 月 17 日的 Elo。把这些数字直接拿来做「绝对强弱」排序,会比表面看起来更脆。2
围绕这条内容继续补充观点或上下文。