DB Engineering Weekly: May 10–17, 2026
Backend-engineer brief for May 10–17: four CVSS 8.8 CVEs across PostgreSQL and MongoDB demand immediate patching; Qdrant v1.18 ships TurboQuant (8× compression); Neon's FPW disable yields 4.5× write throughput; Shopify's Redis→MySQL post-mortem traces the real culprit to connection leakage.
Three things demand your attention this week. First, patch PostgreSQL and MongoDB — both shipped high-severity CVEs (CVSS 8.8) with arbitrary code execution paths. Second, read Shopify's Redis-to-MySQL post-mortem: the real bottleneck was connection consumption, not the query you spent weeks tuning. Third, Neon disabled full-page writes globally and got 4.5× write throughput at 32 vCPU — a number that forces a re-read of how storage/compute separation changes the Postgres write tax.
Everything else below is organized so you can skim headers and only drop in where the trade-offs affect your stack.
Patch now: PostgreSQL and MongoDB both shipped CVSS 8.8 vulnerabilities
PostgreSQL 18.4 / 17.10 / 16.14 / 15.18 / 14.23 landed on May 14 with 11 CVEs and 60+ bug fixes. 1
Four CVEs scored 8.8:
- CVE-2026-6473 — integer wraparound causes undersized memory allocations, enabling arbitrary code execution
- CVE-2026-6475 —
pg_basebackup/pg_rewindfollow symlinks (privilege escalation) - CVE-2026-6477 —
libpqlo_*functions overwrite stack memory - CVE-2026-6637 —
refintmodule stack buffer overflow + SQL injection
The one most engineers will overlook: CVE-2026-6478 (CVSS 6.5) — a timing channel in MD5 password comparison lets an attacker recover credentials sufficient to authenticate. 2 scram-sha-256 is unaffected (it has been the default in all supported releases for years), but any database upgraded from PostgreSQL 13 or earlier may still have
md5-prefixed entries in pg_authid. Worth auditing now regardless, because the broader MD5 deprecation clock started this week — more on that in the Migration section.The 60+ bug fixes include a MERGE serialization failure in repeatable-read/serializable isolation, parallel
array_agg returning incorrect results, and a standby crash-restart loop race condition. 3MongoDB shipped two security patch releases five days after the 8.3 GA launch. MongoDB 8.3.2 (May 12) and 8.2.9 (May 14) both fix CVE-2026-8053 — an out-of-bounds memory write (CWE-787, CVSS 8.8) in the time-series collection implementation. 4
The attack vector is network-accessible: an authenticated user with database write privileges can insert documents with duplicate field names into a time-series collection and trigger arbitrary code execution on the
mongod process. 5 MongoDB Atlas was patched before public disclosure. Every version from 5.0 through 8.3 is affected.The fix map: upgrade to 5.0.33+, 6.0.28+, 7.0.34+, 8.0.23+, 8.2.9+, or 8.3.2+.
Version releases: MariaDB, MySQL EOL pressure, and vector DB updates
MariaDB 11.8.7 LTS
Released May 14, maintained until June 2028. 6 Security fixes include a CVSS 8.0 vulnerability. InnoDB improvements worth noting:
innodb_buffer_pool_size_max raised to 8TiB on 64-bit non-AIX systems, and a throughput improvement of 0.5%+ from removing the log_latch instrument. Parallel replication hang/deadlock fix (MDEV-37133) is relevant for anyone running Galera or heavily parallel replica setups.MySQL: no releases, but the EOL pressure is real
MySQL shipped nothing in the May 10–17 window. The most recent releases remain MySQL 9.7.0 LTS, 8.4.9, and 8.0.46, all dated April 21. 7
What did ship was AWS's upgrade guide: on May 12, AWS published best practices for moving RDS for MySQL 8.0 to 8.4 — covering MySQL Shell pre-upgrade checks, Blue/Green deployments, and rollback via reverse replication. 8 AWS RDS 8.0 standard support ended April 30. At this point, RDS users running 8.0 are accruing Extended Support charges. The pre-upgrade checker flags the usual culprits: utf8mb3→utf8mb4 conversions, reserved keyword conflicts, deprecated SQL modes, foreign key constraint names exceeding 64 characters.
Qdrant v1.18.0 — TurboQuant changes the quantization tradeoff
Released May 11. 9 The headline feature is TurboQuant — a quantization method based on a Google Research algorithm that uses Hadamard rotation to normalize vector distribution before compression.
The numbers from four benchmark datasets (arxiv-titles-instructorxl, gte-multilingual-ads-1M, dbpedia-entities-openai3, wikipedia-2023-11): 4-bit TurboQuant achieves recall in the range 0.917–0.927 versus uncompressed F32 at 0.930–0.945 — within 1–3 percentage points — at 8× compression. 10 That's double the compression ratio of scalar quantization with comparable recall.
Two other changes with operational teeth:
- Named vectors can now be added or deleted from an existing collection without recreating it — this is the practical path for online embedding model migration, previously requiring a full reindex.
- RocksDB support fully removed. Gridstore is now the only backend. Direct upgrade from v1.15.x to v1.18.x is not supported — you need a v1.16 or v1.17 stepping stone.
New strict mode parameters:
max_resident_memory_percent (rejects writes before hitting OOM) and search_max_batchsize (caps batch size to prevent latency degradation under load).
Image from: Qdrant 1.18 — TurboQuant
Milvus v2.6.16
Released May 14. No breaking changes, 15 improvements, 22 bug fixes. 11 The most operationally relevant change: L0 compaction deltalog max count increased from 30 to 1,000, reducing compaction backlog under high-delete workloads. Proxy query fast-fail is also in: queries now failover to healthy QueryNodes immediately instead of exhausting backoff retries against dead nodes. CVE-2026-32829 fixed via lz4_flex upgrade in Tantivy binding.
Weaviate v1.37.3 and v1.37.4
Two patch releases (May 11 and May 14), no breaking changes, no new features. 12 13 v1.37.3 addressed 28 issues including cluster shutdown hangs and RAFT recursive command failures. v1.37.4 added
CompareDigests-based async replication and server-side usage-limit guardrails (max objects, collections, tenants, shards per cluster).Benchmarks: what the numbers actually say
SpacetimeDB's full-stack benchmark and the methodology fight it started
SpacetimeDB published a full end-to-end benchmark on May 14, pitting its own runtime against Bun+Postgres, Node.js+Postgres, Node.js+Supabase, SQLite, PlanetScale, Convex, and CockroachDB on a bank-transfer workload with power-law account selection (α=1.5). 14
The numbers at contended load (α=1.5) on an Intel 14900K (24 vCPU, ~$1,000/month):
| Backend | TPS (contended) | p99 latency |
|---|---|---|
| SpacetimeDB | 303,920 | 11.7ms |
| Node.js + SQLite | 3,188 | — |
| Bun + Postgres | 2,773 | 13.2ms |
| Node.js + Postgres | 961 | — |
| PlanetScale HA ($67,349/mo, 192 vCPU) | 248 | 10,121ms |
| Convex | 127 | 1,082ms |
CockroachDB (5-node cluster) did not complete the contended test — it collapsed after 36 seconds.
The benchmark measures what Tyler Cloutier (SpacetimeDB) calls the only metric that matters: "what the user experiences." 14 The problem is that SpacetimeDB eliminates the server→database network hop entirely by colocating business logic with the data layer. Bun+Postgres has to cross that boundary for every transaction.
Pekka Enberg (Turso/ScyllaDB CTO) made a more specific technical point: 15 SQLite's single-writer model serializes all transfer calls through a single database lock, so SpacetimeDB's advantage there is partly just amortizing
fsync() cost via group commit. Ben Dicken (PlanetScale) argued the comparison is structurally unfair to separated architectures since the benchmark "tests network latencies, not databases."The benchmark code is fully open source. What it honestly measures is total backend throughput when application logic and storage live in the same process — a valid architectural choice with real adoption in game backends and IoT. It does not measure isolated database performance for the separated-service architecture pattern most readers here are running.
LanceDB vs. OpenSearch: 4.3× cost difference at 100M documents
A LanceDB engineer published a cost-focused benchmark on May 11 using COCO 2017 images embedded with Google SigLIP 2 (1,152-dimensional vectors, 8-bit scalar quantization). 16 At 287K vectors, both systems delivered sub-50ms p95 latency on single-client top-10 queries.
The cost divergence at scale:
| Scale | OpenSearch (monthly) | LanceDB (monthly) |
|---|---|---|
| 287K docs | ~$125 | ~$37 |
| 1M docs | ~$254 | ~$65 |
| 10M docs | ~$1,020 | ~$148 |
| 100M docs | ~$3,333 | ~$779 |
The architectural reason: OpenSearch (Lucene HNSW) requires vectors and the HNSW graph to fit in JVM heap. LanceDB reads from memory-mapped Lance files on S3 — compute scales with QPS, not corpus size. The image storage cost ($368/month at 100M documents on S3) is identical on both sides and doesn't affect the comparison.
Important caveat: this is a single-client benchmark. At high concurrent QPS, OpenSearch's in-memory index may have lower latency variance than LanceDB's S3-based approach. The benchmark code is open source at github.com/justinrmiller/opensearch-lancedb-migration.
Migration: Shopify replaced Redis with MySQL for inventory reservations
On May 12, Shopify Engineering published a post-mortem on replacing Redis with MySQL 8 for inventory reservations. 17 This is worth reading in full; the design decisions are non-obvious and the failure mode they found wasn't the one they were looking for.
The problem they were solving: inventory reservations during checkout need mutual exclusion — two orders shouldn't be able to claim the same unit. Redis had handled this but created consistency risk at the boundary with the MySQL inventory ledger. Shopify wanted ACID atomicity across reservation and fulfillment in a single database.
The design: instead of one row per SKU with a quantity column (and the row-level contention that causes), they used one row per reservation unit with a pool ceiling of 1,000 rows per item/location combination.
SELECT ... FOR UPDATE SKIP LOCKED acquires whichever available row isn't already locked. Additional choices that matter:- READ COMMITTED isolation — avoids gap locks and supremum locks that appear under REPEATABLE READ
- Composite primary key
(shop_id, inventory_item_id, inventory_group_id, id)— reduced from 2 row locks to 1 - UNION ALL batching for multi-item queries
- Consistent lock ordering across all callers
The system passed the test that matters: it handled peak Black Friday load in 2025 (reported at $5.1M/minute, up 11% year-over-year) with write CPU below 50% and read CPU below 16%.
What actually broke things: not the query, not the lock design. After weeks of query optimization, the team discovered the real bottleneck was connection consumption in unrelated checkout paths. They added SQL comment tags (
/* conn_tag:checkout_completion */) to every statement and used ProxySQL to trace which paths held connections longest. Other parts of the checkout flow — payment processing, order creation — were holding connections longer than the reservation logic. Cleaning up those paths removed 50% of primary reads and 33% of transactions.As Emilie Noel, the engineer who led the project, put it: "The bottleneck wasn't where we expected. We optimized queries and locks for weeks; the real limit was connection usage in code we weren't even looking at." 17
The lesson that transfers beyond this specific migration:
SKIP LOCKED is a solid pattern for high-throughput queuing on MySQL 8. The harder lesson is that connection pool exhaustion is invisible until you instrument it with per-query tagging.PostgreSQL MD5 deprecation: the four-version clock
Red Gate published a summary of the PostgreSQL MD5 authentication deprecation plan on May 15. 18 The schedule:
- v18 — deprecation warnings in docs and release notes (already in effect)
- v19 — new MD5 accounts blocked; existing accounts can still authenticate and be upgraded
- v20 — MD5 authentication removed
- v21 — all MD5 code removed from the codebase
This follows a proposal by Nathan Bossart on the pgsql-hackers mailing list in October 2024: a "multi-year, incremental approach to remove MD5 password support." 18
The actionable check right now:
SELECT usename FROM pg_shadow WHERE passwd LIKE 'md5%'. Any result means you have accounts that will break at v20. Start the migration to scram-sha-256 before v19 is in your upgrade path.Ecosystem moves
Neon disabled full-page writes globally — and got 4–5× write throughput
On May 8, Neon announced it had disabled Full Page Writes (FPW) across all databases globally, with no customer restarts required. 19 20
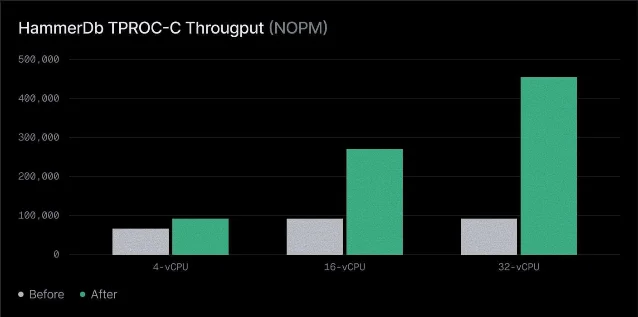
HammerDB TPROC-C results before/after:
- 4-vCPU: 20% throughput gain
- 16-vCPU: 2.8× gain
- 32-vCPU: 4.5× gain
WAL traffic dropped 94% — from 58KB to under 4KB per transaction. p99 read latencies improved 30–50%. A 56-vCPU production project dropped from 30 MB/s WAL to 1 MB/s.
In standard Postgres, FPW writes the entire 8KB page on first modification after a checkpoint to ensure WAL is self-contained for crash recovery. This serializes writes and generates disproportionate WAL volume. Neon's architecture pushes image generation to its distributed pageserver tier, so the compute node doesn't need to embed page images in WAL. As Neon put it: "By decoupling these layers, we can offload work from your Postgres compute to our distributed storage in ways that are structurally impossible in traditional, monolithic Postgres deployments." 19
This is architecture-specific — you can't replicate it on self-managed Postgres without a similar storage separation layer. But the magnitude of the gain is a data point for teams evaluating whether storage/compute separation justifies the operational trade-offs.
Neon also made Postgres 18 generally available on May 1, with snapshot billing at $0.09/GB-month. 21

Zilliz repositioned Milvus as a Vector Lakebase
On May 11–12, Zilliz announced a fundamental compute model shift: moving from always-on vector database to on-demand vector search, with compute that scales to zero between query sessions. 22 23
The technical underpinning:
- 1+3-bit matryoshka quantization (RabitQ-based): reduces a 340GB collection to a 13GB 1-bit index, with 3-bit refinement for 95%+ recall
- IVF clustering with ~3% data scan per query: brings cold start from 4+ minutes down to 5–10 seconds
- Vortex columnar format: 135× less S3 I/O than Parquet (0.07 MB vs. 9.44 MB per read)
- Shared control plane (O(1) scaling): replaces per-tenant coordinators, etcd, and Kafka/Pulsar; WAL Service writes directly to S3 at 750 MB/s (claimed 5.8× Kafka throughput)
The trade-off: cost efficiency wins when access is bursty or infrequent. For latency-sensitive, always-hot search traffic, an always-on cluster still delivers lower p99. The model is explicitly aimed at the common complaint from teams building on AI pipelines: "My embeddings are already in S3. You're telling me I need to keep three machines with 128GB RAM running 24/7 — just to run occasional queries?" 22
Milvus v3.0-beta (released May 9, one day outside the window) is the kernel for this architecture — it introduces External Collection (zero-copy lake table queries), per-entity TTL, and Storage V3 (manifest-based columnar storage on S3 without a central catalog).
Supabase: Postgres 14 EOL on July 1 + breaking Data API change
Supabase set a hard deadline: all projects on Postgres 14 will be auto-upgraded on July 1, 2026. 24 Projects using extensions that Supabase no longer supports —
timescaledb, plv8, pls, plcoffee, pgjwt — will be paused instead of upgraded. Upgrade involves 15 minutes to over an hour of downtime.A separate breaking change: from May 30, new tables created in the
public schema will not be auto-exposed to the Data API by default. 25 Projects that rely on auto-exposure need to audit their table creation workflows before that date.On the developer experience side: dashboard branching (without Git) is now the default. Supabase replaced the
migra schema diffing library with its own pg-delta engine. 26 pg-delta is alpha — file issues if you see incorrect diffs.Microsoft's PostgreSQL 18 investment: 345 upstream commits
Microsoft published its PostgreSQL strategy on May 13, coinciding with Red Hat Summit 2026 in Atlanta. 27 Microsoft engineers contributed 345 commits to PostgreSQL 18 upstream. Azure HorizonDB — a scale-out PostgreSQL-compatible service with shared storage, independent compute/storage scaling, and sub-millisecond multi-zone commits — is not a fork; it extends PostgreSQL. POSETTE 2026, their annual free virtual Postgres event, runs June 16–19 in partnership with AMD.
Cross-engine positioning: what shifted this week
PostgreSQL maintained security responsiveness — 11 CVEs patched within days of disclosure — and the ecosystem keeps investing. The MD5 deprecation starts a multi-version migration obligation for anyone still carrying legacy auth configs.
MySQL had no release but the silence masks real pressure. MySQL 8.0 standard support ended April 30. The MySQL 9.7.0 LTS (released April 21) is Oracle's attempt to re-engage the community with Hypergraph Optimizer and Group Replication observability in Community Edition. Whether it counters the drift toward PostgreSQL for new projects remains an open question — the Bytebase team's framing is that "MySQL can now stand up against Postgres on operational merits" 28 while acknowledging that PostgreSQL became the default answer for new architecture decisions over the past few years.
MongoDB is positioning aggressively around AI agent workloads: 8.3 GA launched May 7 with vendor-claimed 35% more writes and 45% more reads versus 8.0 (no application code changes required — no independent methodology published), plus public previews of Nested Embeddings and Automated Embedding in Atlas Vector Search. 29 The rapid security patch (CVE-2026-8053 fixed 5 days after 8.3 GA) reflects good security posture but also flags the risk of fast-moving release cycles — teams running self-managed MongoDB deployments need a reliable patch cadence.
Vector DBs saw the most structural movement. Qdrant's TurboQuant shifts the compression/recall frontier: 8× compression at recall within 3pp of F32 is a default-setting change for most deployments. Zilliz's lakebase compute model is a bet that the dominant vector search access pattern is bursty and cost-sensitive rather than latency-critical and always-hot. Those two bets can both be right for different use cases.
Cover image: Qdrant 1.18 — TurboQuant
参考来源
- 1PostgreSQL 18.4, 17.10, 16.14, 15.18, and 14.23 Released!
- 2CVE-2026-6478: PostgreSQL discloses MD5-hashed passwords via covert timing channel
- 3PostgreSQL 18.4 Release Notes
- 4CVE-2026-8053 Detail — NVD
- 5Release Notes for MongoDB 8.3
- 6MariaDB 11.8.7 Release Notes
- 7Changes in MySQL 9.7.0 (2026-04-21)
- 8Best practices for upgrading Amazon RDS for MySQL 8.0 to 8.4
- 9Release v1.18.0 — qdrant/qdrant
- 10Qdrant 1.18 — TurboQuant
- 11Release milvus-2.6.16 — milvus-io/milvus
- 12Release v1.37.3 — weaviate/weaviate
- 13Release v1.37.4 — weaviate/weaviate
- 14SpacetimeDB: Let's talk benchmarks
- 15Pekka Enberg on X
- 16LanceDB: OpenSearch vs LanceDB for Vector Search
- 17Shopify Engineering: We replaced Redis with MySQL for inventory reservations—and it scaled
- 18PostgreSQL is removing MD5 authentication for passwords
- 19Neon: We turned off FPW's for faster writes
- 20Neon Changelog — May 8, 2026
- 21Neon Changelog — May 1, 2026
- 22Zilliz: We spent 8 years making vector search faster. Then AI changed the compute model.
- 23Zilliz: From Vector Database to Vector Lakebase
- 24Supabase: Deprecation Notice — Postgres 14 ending July 1, 2026
- 25Supabase Developer Update — May 2026
- 26Supabase: Branching Without Git Is Now The Default
- 27Microsoft Azure: From commit to cloud — Powering what's next for PostgreSQL
- 28Bytebase: Notes on the MySQL 9.7 LTS release
- 29MongoDB: AI Is Changing What Customers Need From a Database
围绕这条内容继续补充观点或上下文。