
23/6/2026 · 8:19
Prompt injection is becoming an agent security problem
Zico Kolter and Matt Fredrikson argue that the next AI security failure is likely to come from agents combining private data, untrusted content, tools and user permissions. This article distills why red teaming is becoming model-vs-model work, why system prompts are not enough, and what practitioners should change before the gray-swan breach arrives.

Vistazo a la investigación
The most important line in Latent Space's new conversation with Zico Kolter and Matt Fredrikson is not a product pitch. It is a reframing: AI security is no longer mainly about using models to defend conventional software. It is about defending organizations from the strange failure modes of the models and agents they are now deploying. In the episode, Kolter says AI systems "can be tricked in ways people can be tricked," but also fail in ways that are unlike people, which is why he argues they need a different security mindset from ordinary software systems 1.
That sounds abstract until you put it next to what agents actually do. A coding agent reads repositories, opens issues, fetches webpages, writes files, calls tools and may carry the user's permissions. Fredrikson's version of the risk is narrower and more operational: once autonomous systems are built on top of models and connected to a larger platform or network, the model itself becomes part of the cybersecurity risk surface 1.
Cargando tarjeta de contenido…
The guests matter because they sit at the model-security boundary
Kolter is not only speaking as an academic. OpenAI announced in 2024 that he had joined its board and Safety and Security Committee, citing his work on AI safety, alignment and model robustness 2. Fredrikson's own profile lists him as CEO of Gray Swan AI and associate professor at Carnegie Mellon, with recent work on AI agents, indirect prompt injection and model security 3.
That background shapes the episode. The conversation is less about abstract doom and more about attack surfaces: how an agent handles untrusted text, how it decides which instruction to obey, how it proves that a tool call is legitimate, and how an enterprise can test a deployment before a real adversary does.
Gray Swan's public site describes the company as an adversarial evaluation and protection platform for AI agents, and says its methods draw on attacks discovered by more than 15,000 adversarial researchers and over three million attack attempts 4. Those numbers are useful context, but the deeper point in the episode is methodological: if the frontier moves every few months, a static checklist is not enough.
Cargando tarjeta de estadísticas…
Red teaming is becoming a model problem
Fredrikson describes two parts of Gray Swan's work. One is the Arena: a community red-teaming environment that turns lab objectives into prize challenges and returns useful failure cases to model developers 1. The other is automated red teaming, where Gray Swan trains models to attack other models and agents.
Kolter is blunt about why that matters. General frontier models are not automatically good red teamers because their safety training often makes them refuse to generate attacks. A specialized red-teaming model has to be trained for that job 1. In fixed-time tasks, he says Gray Swan's Shade system can already find more breaks than human red teamers, though Fredrikson adds a caveat: that is not the same as claiming universal superhuman red teaming 1.
Gray Swan's own Shade page presents the product as an autonomous adversarial campaign system that adapts, escalates and chains attacks against models, guardrails and deployment context 5. The phrase "campaign" is doing real work. A serious attacker does not run one prompt and stop. They probe, mutate, combine techniques and search for weak seams between the model, the system prompt, tools and permissions.
Prompt injection is a permissions problem, not a wording problem
The most practical section of the episode is the discussion of Simon Willison's "lethal trifecta": private data, untrusted content and the ability to communicate externally 6. If all three are present, prompt injection is no longer a parlor trick. It becomes a path from malicious instructions to data exfiltration.
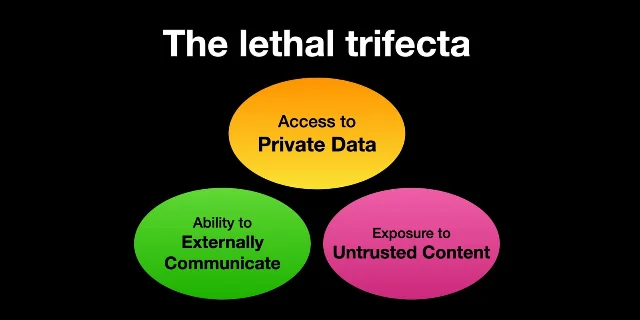
Kolter and Fredrikson's argument is that agents make this combination easier to stumble into. A code agent may read a malicious issue, inspect private source code and open a pull request. A browser agent may read attacker-controlled web content while logged into sensitive services. An office assistant may read email and send messages. The risk is not that the model has a bad personality. The risk is that instruction-following is being connected to privileges.
This is why the episode treats "just prompt it better" as an incomplete defense. Fredrikson says system prompts can help, but prompt injection exploits ambiguity: the model receives competing instructions and must infer which policy is authoritative 1. Kolter extends the point with a scaling warning: larger models do not automatically become more robust to adversarial pressure; robustness has to be trained and tested directly 1.
The hard part is agent identity
The article's strongest enterprise lesson is about identity and permissions. In many early agent deployments, the agent inherits the user's full permissions. That is convenient, but it also means compromise of the agent can become compromise of everything the user can access. In the episode's framing, agent-native identity is underdeveloped: organizations need ways to decide what an agent is allowed to know, what it is allowed to do, and which external actions require human confirmation 1.
A useful way to read the episode is as a four-layer security stack:
| Layer | What has to be tested | Why the transcript treats it as hard |
|---|---|---|
| Model behavior | Jailbreaks, refusals and indirect prompt injection | Models can be capable without being robust 1 |
| Agent harness | Tool choice, browser actions, coding actions and file access | Agents combine untrusted input with consequential actions 1 |
| Runtime guardrails | Inputs, outputs and tool-call policies | Guardrails need to understand deployment-specific policy, not just generic bad words 1 |
| Organizational controls | Identity, permissions, audit trails and insurance | The business has to decide which AI risks are acceptable enough to underwrite 1 |
That table is also where the podcast becomes most sober. Kolter does not claim this will be solved by a single product category. He describes security as moving the Pareto frontier between usefulness and risk: make agents more capable without letting every new capability become a new exfiltration channel 1.
The "gray swan" is the breach everyone expects
The closing argument is intentionally uncomfortable. Kolter calls a major AI security incident a gray swan: unlikely in any specific instance, but visible enough that nobody should be surprised when it happens 1. Fredrikson adds that organizations do not always publicize these incidents, and that some real damage has already driven customers toward specialized AI security work 1.
For practitioners, the takeaway is not to stop using agents. It is to stop treating agent security as a prompt-writing exercise. If an agent touches private data, reads untrusted content or can communicate outside the organization, it needs threat modeling, adversarial testing, narrow permissions and a clear account of what happens when the model obeys the wrong instruction.
That is the episode's real warning: the next AI security failure may not look like a model suddenly becoming malicious. It may look like a helpful agent doing exactly what some text told it to do.


Añade más opiniones o contexto en torno a este contenido.