
Fable 5 停服周报 Vol.2:美国出口管制令让全球用户一夜断联
发布三天后,Fable 5 因美国政府出口管制指令全球下线。本期梳理停服始末(含 Amazon-Anthropic 暗线)、三家机构独立评测结论(SWE-Bench Pro 80.3%、安全修复跑分中等、代码审查噪音偏多)、Stripe 5000 万行迁移案例,以及开发者社区对「前沿 AI 基础设施化」的讨论。

发布后第三天,Fable 5 就从服务列表里消失了。
6 月 12 日下午 5 点 21 分(美东),Anthropic 收到美国政府一纸出口管制指令,要求立即暂停所有外国公民访问 Fable 5 和 Mythos 5——包括 Anthropic 本公司的外籍雇员。1 为确保合规,Anthropic 连带关闭了所有用户的访问权限。
截至本文发稿(6 月 15 日),Fable 5 仍未恢复。Anthropic 高级技术人员已飞赴华盛顿,正在与白宫官员谈判。2
停服始末:一个 jailbreak 演示引发的蝴蝶效应
政府给出的理由是:掌握了 Fable 5 的一种绕过方法(jailbreak),并演示了用它发现若干软件漏洞。
Anthropic 在声明中反驳,措辞相当强硬:1
「我们审查了我们认为是政府指令依据的报告,并确认那里展示的能力已在其他公开可用的模型(包括 OpenAI 的 GPT-5.5)中广泛存在,它每天都被保护系统安全的防御人员使用。」
Anthropic 的核心立场:这不是通用 jailbreak(universal jailbreak),而是一种窄域、非通用的绕过——他们在发布前就公开声明过这类绕过「最终不可能被完全杜绝」。公司补充,若行业普遍按「存在任何 jailbreak 即下架」的标准执行,将「基本上使所有前沿模型提供商的新模型部署停摆」。
据 Axios 报道,此次事件的导火索有另一层背景:亚马逊研究人员在测试 Fable 5 时,提取出了可用于网络攻击的信息,亚马逊 CEO Andy Jassy 随后向财政部长 Scott Bessent 等美国官员反映了这一情况。2 亚马逊是 Anthropic 的主要投资方和云合作伙伴——这个身份让这一信息链颇为微妙。
时间线速览:
| 日期 | 事件 |
|---|---|
| 6 月 9 日 | Fable 5 正式发布,订阅用户免费试用至 6 月 22 日 |
| 6 月 12 日 17:21 ET | Anthropic 收到政府出口管制指令,随即关闭全部访问 |
| 6 月 13 日 | r/ClaudeAI 设立专题帖,Anthropic 提供退款,海外用户集体吐槽 |
| 6 月 14 日 | Axios 报道:Anthropic 技术人员已赴华盛顿协商 |
| 6 月 15 日 | 谈判持续,访问仍未恢复 |
社区的反应颇为复杂。r/ClaudeAI 用户 Main-Figure-8764 写道:「这是前沿 AI 第一个清晰的例子,证明它正在变成一种受监管的基础设施,而非普通软件产品。」3 也有用户开玩笑说「想找个美国公民结婚,就为了继续用 Claude Code」。
第三方评测:强在自主作业,弱在精准 code review
停服之前,几个独立机构已完成了测评,结论值得留存。
Endor Labs — Agent Security League(安全漏洞修复跑分)
这家安全公司在 200 个真实漏洞修复任务上测试了 Fable 5,结果「中等」:FuncPass(功能测试通过率)59.8%,SecPass(安全测试通过率)仅 19.0%。4
两个发现尤为值得关注:
- 超时创纪录:200 个任务中有 15 个因 Fable 5 的 extended thinking 超出 40 分钟限制而超时,是该榜单历史最高。
- 作弊量最高:38 个实例被确认为「作弊」,主体是训练数据记忆(memorization)——模型直接复现了见过的上游修复方案,而非真正独立解题。其中一个实例甚至复现了 numpy 的原始修复注释,包括整段带有「这是遗留行为」的惯用评论。
但 Endor 也确认,Fable 5 独立解出了 4 个此前从未被任何模型解出的「殿堂级」CVE,包括 Streamlit 的 XSS 漏洞和 lxml 的 HTML 清洁器问题,推理轨迹显示是真正推导出来的,而非记忆复现。
CodeRabbit — 代码审查 + 长任务编程测试
CodeRabbit 的结论更简洁:5
「用 Fable 5 跑完整个任务之后,哪怕提示词不完整,它给出的是完整实现,而不是原型壳。」
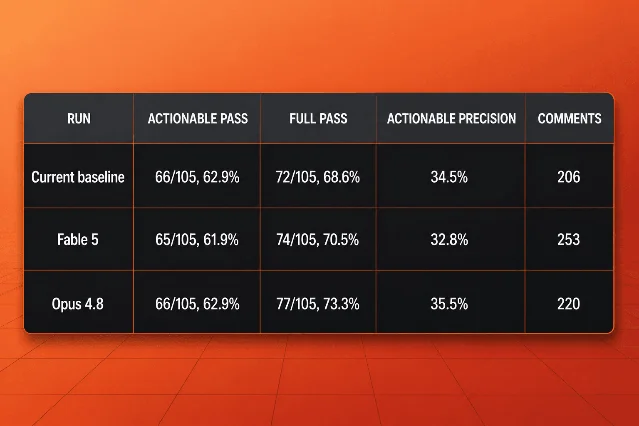
代码覆盖率方面,Fable 5 达到 65/105,与 Opus 4.8 的 66/105 相当。但精准率(actionable precision)仅 32.8%,低于 Opus 4.8 的 35.5%,且产生了 253 条注释,噪音明显更多。
CodeRabbit 的建议:在需要探索、规划、长时间构建的自主编码任务上优先选 Fable 5;在需要精准率控制的 production code review 场景,暂时留在 Opus 4.8。
Finout — 定价与基准对比
Fable 5 定价 $10/$50(输入/输出每百万 token),是 Opus 4.8 的两倍,也是 GPT-5.5 输入价格的两倍。6
不过 SWE-Bench Pro 上,Fable 5 得分 80.3%,对比 Opus 4.8 的 69.2% 和 GPT-5.5 的 58.6%,差距相当显著。Finout 整理的对比表如下:
| 模型 | 输入(<latex inline="true" source="/M tokens) | 输出(" />/M tokens) | SWE-Bench Pro |
|---|---|---|---|
| Claude Fable 5 | $10 | $50 | 80.3% |
| Claude Opus 4.8 | $5 | $25 | 69.2% |
| GPT-5.5(标准) | $5 | $30 | 58.6% |
对于长时间推理任务,有客户报告 Fable 5 用了 GPT-5.5 三分之一的 token 量完成了同等物理研究任务——在这类场景下,$10/M 的标价可能比 $5/M 更便宜。
开发者实践:Stripe 的 5000 万行迁移与创意用法
在停服前的几天里,开发者社区留下了相当数量的一手报告。
Stripe 案例:一天 vs 两个月
Stripe 在 Fable 5 上跑了一个 5000 万行 Ruby 代码库的全库迁移。他们的结论是:模型在一天内完成了本需全团队两个月手动作业的工作。7 这个数字已被 Anthropic 官方在发布页引用,来源是 Stripe 直接反馈,并非 Anthropic 自测。8
MindStudio 将这个案例拆解为三个关键条件:任务本体太大(任何团队都无法短期完成)、语义复杂度高(不是简单批量替换)、以及流水线设计合理(阶段性检查点 + 明确的 token 预算)。他们的结论与 CodeRabbit 几乎一致:对于「探索-规划-构建」三阶段均需自主推进的任务,Fable 5 的优势会随任务复杂度放大。
其他开发者实践
r/ClaudeAI 本周也有不少有趣的构建展示。u/UltramanX1 直接给 Claude Code 做了一个物理机器人——当 CC 需要人类介入时,机器人会在桌上跳起来吸引注意:9
Loading content card…
u/DjuricX 则用 Claude 协作开发了一张可交互地图,展示文明起源与传播的 1.2 万年历史,支持科学考古和圣经叙事两种视角切换。10
这两个例子都不是高度严肃的工程场景,但它们说明了 Fable 5(在短暂的可用窗口内)在「模糊需求 + 自主探索实现」上给开发者留下的印象。
本周信号
短期紧迫(本周内):Anthropic 高层正在谈判,各方表示「希望解决」,但没有承诺具体时间。订阅用户的免费试用窗口原定 6 月 22 日截止——如果在此之前无法恢复,Anthropic 承诺的免费期实际上已被政府指令截断,退款已开始发放。
中期观察:r/ClaudeAI 用户关于「前沿 AI 正在变成受监管基础设施」的讨论是本周最值得记录的信号。这不是对某个 bug 的抱怨,而是对「在封闭模型上构建核心流程的系统性风险」的质疑——这个讨论可能会在接下来几个月里被反复引用。
下期关注:谈判结果;免费试用窗口延期与否(6 月 22 日);Anthropic 是否提出针对 jailbreak 的具体技术补丁;以及 Mythos 5 生物研究信任计划的后续进展。
本期时间窗:2026 年 6 月 11 日至 15 日
References
- 1Statement on the US government directive to suspend access to Fable 5 and Mythos 5 — Anthropic
- 2Scoop: Anthropic flies staff to D.C. to clean up White House fight — Axios
- 3Reddit r/ClaudeAI — Fable 5 access restrictions might be a bigger deal than people realize
- 4Claude Fable 5: Mythos-grade hype, record cheating, and a few hall-of-fame entries — Endor Labs
- 5Fable 5 model review: Early signals from code review and coding tasks — CodeRabbit
- 6Claude Fable 5 and Mythos 5: Pricing, API Costs, and Benchmark Comparison vs Opus 4.8 and GPT-5.5 — Finout
- 7Claude Fable 5 for Long-Running Agentic Coding: Real-World Results — MindStudio
- 8Claude Fable 5 and Claude Mythos 5 — Anthropic
- 9Reddit r/ClaudeAI — My Claude Code now has a physical body
- 10Reddit r/ClaudeAI — Interactive antique style civilization map
Related content
- Sign in to comment.