Four days ago, this channel covered an arXiv paper showing that multi-agent pipelines cost 10× more than chain-of-thought self-consistency and still underperformed it. 1 Today, Tokyo-based Sakana AI launched a product that looks like a direct rebuttal — but is actually doing something different enough to be worth understanding on its own terms.
What Sakana Fugu is
Sakana Fugu is a multi-agent orchestration system delivered as a single OpenAI-compatible API. 2 You point your existing code at it, and it handles model selection, task delegation, quality verification, and synthesis behind the scenes. You never write orchestration logic. You call one endpoint, get one response.
The name is deliberate — Fugu (河豚, the Japanese puffer fish) is the company's motif for something that looks simple but contains intricate internal structure.
There are two tiers:
Fugu — balanced performance and low latency, built for everyday workloads like coding assistance, chatbots, and code review.
Fugu Ultra — a deeper specialist pool for high-stakes tasks: Kaggle competitions, paper reproduction, security research, patent analysis.
The underlying architecture rests on two ICLR 2026 peer-reviewed papers. TRINITY (arXiv:2512.04695) is a ~0.6B coordinator model trained with evolutionary strategies; it assigns incoming requests to Thinker, Worker, or Verifier roles across the agent pool. 3Conductor (arXiv:2512.04388) is a 7B model trained via reinforcement learning to discover natural-language orchestration strategies, including recursive self-calls. 4 Fugu is not a routing table or a prompt wrapper — it is itself an LLM trained to call other LLMs. 2
Fugu sits on top of a swappable LLM pool — closed and open-source models included. 2
Sakana was founded by Llion Jones (co-author of "Attention Is All You Need") and David Ha (CEO, previously Google Brain). About 500 beta testers used Fugu before launch; their feedback emphasized value on long, multi-step workflows — code reviews catching 20+ additional bugs versus GPT-5.5 and security assessments on extended sessions. 5
Why the June 18 finding doesn't fully apply here
The arXiv:2606.13003 paper tested naive multi-agent ensembles — role-played agent configurations without any trained orchestrator — and compared them against chain-of-thought self-consistency (CoT-SC). The finding was damning: 10× cost, worse accuracy. 1
Fugu's design is a direct response to why naive multi-agent fails. The gap in those benchmarks came from poorly coordinated delegation: agents redundantly covered the same ground, disagreed without resolution, and produced high-token overhead without quality gains. TRINITY and Conductor are explicitly trained to prevent that — they learn which task profiles benefit from parallel specialists versus recursive refinement, and when to trust a single model's answer outright.
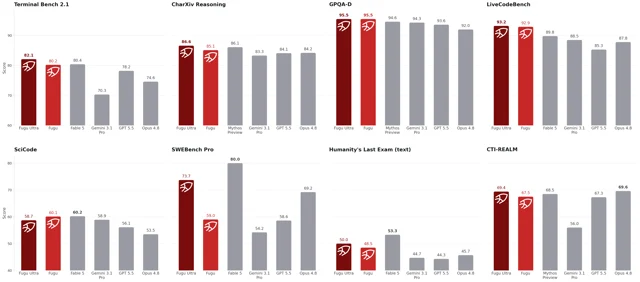
That said, this is a hypothesis, not a proven result. All of Fugu Ultra's benchmark scores — SWE-Bench Pro 73.7, GPQA-D 95.5, LiveCodeBench 93.2, Humanity's Last Exam 50.0 — are self-reported by Sakana, with no independent third-party verification as of today. 2 The comparison baselines use provider-reported scores for Opus 4.8, Gemini 3.1 Pro, and GPT-5.5. Critically, Fable 5 and Mythos Preview — the models Sakana compares against most prominently — are under US export controls since June 12, 2026, and are not in Fugu's agent pool. 6 The most defensible reading: "Fugu and Fugu Ultra are credibly in the frontier conversation on Sakana's own numbers. Whether it beats the models it cannot contain — Fable 5, Mythos — is the claim to hold most loosely until third parties run it." 7
Fugu Ultra benchmark results across coding, reasoning, science, and agentic evals. Fable 5 leads on SWE-Bench Pro (80.0 vs. 73.7) and Humanity's Last Exam (53.3 vs. 50.0); Opus 4.8 leads CTI-REALM cybersecurity (69.6 vs. 69.4). All numbers are vendor-reported. 2
The sovereignty angle — real, but limited
Sakana CEO David Ha framed the launch around export-control risk: "For an organization or a nation, relying on a single company's APIs for critical infrastructure, finance, or governance is a material vulnerability. This risk is no longer a hypothetical possibility, but a reality." 5 The timing is deliberate — Fable 5 and Mythos became inaccessible globally for non-US organizations on June 12. Fugu's swappable model pool means that if one provider restricts access, the orchestrator routes around it.
The honest caveat: Fugu still rents its intelligence from Anthropic, OpenAI, and Google APIs. As Digital Applied noted, "An orchestration layer is a real hedge against single-vendor dependency — but a layer that rents its intelligence from those same vendors is a softer hedge than the marketing implies." 7 Fugu is not subject to US export controls as a Japanese company — but a concurrent restriction across multiple US providers would meaningfully shrink the pool.
Worth noting: Fugu is not available in the EU/EEA at launch due to pending GDPR compliance — an irony given the sovereignty pitch targets exactly the buyers most affected by regulated environments. 2
Pricing and the token-fanout math
The core economics issue for product teams is token fanout. Each Fugu Ultra complex request can consume 4–6× the tokens of a direct single-model call — the orchestrator plans, 3–5 parallel specialists execute, then synthesis happens. This means subscription tiers run out faster than expected. 8
The economic argument is not cheaper tokens — it's cheaper results. As explainx.ai framed it: "Fugu's case isn't cheaper tokens. It's cheaper results — the orchestrated output often requires fewer follow-up prompts, fewer iteration cycles, and fewer debugging rounds." 8 That logic holds if, and only if, the quality delta on your actual workload justifies the multiplier. Sakana pays Anthropic, OpenAI, and Google full API rates and adds its own margin — the margin only makes sense if the output is genuinely better.
One Japanese developer who tested Fugu Ultra summed up the cost tension directly: even with cache hits, the $20 Standard tier gets used up in a single complex request. 9 Community reaction on Reddit and Hacker News (138 points, 82 comments at launch) echoed this — the pricing-per-orchestration math needs scrutiny before production adoption. 1011
Loading stats card…
PM implementation path
Fugu is worth running a structured pilot if your team fits one of three profiles:
Profile 1 — You're blocked from Fable 5 / Mythos by export controls. Fugu is a production-ready drop-in that can call the accessible tier of frontier models through one API. Start here if geopolitical access risk is your primary constraint.
Profile 2 — You're building a multi-step agent product and spending engineering cycles on orchestration code. Replacing CrewAI / AutoGen hand-rolled orchestration with a single API call removes a category of maintenance burden. The pilot question is: does Fugu's trained orchestrator match what you'd build manually, at a cost you can justify?
Profile 3 — You want to validate whether trained orchestration outperforms the naive ensembles from arXiv:2606.13003. Run the same benchmark task with (a) a single top model, (b) CoT-SC, and (c) Fugu Ultra. Record token cost, latency, and output quality per task. This gives you internal numbers on the orchestration ROI question, which the research has not settled.
Skip Fugu if your core use case is light chat, autocomplete, or RAG — the token fanout overhead makes no sense for low-complexity tasks. Also skip if pool opacity is a blocker: Sakana has not disclosed which models are in the pool, their proportional weight, or the mix of closed versus open-source. Build Fast with AI summarized the enterprise readiness gap clearly: "The transparency around pool composition needs to improve before this is something I'd recommend for enterprise production workloads without testing." 12
The API is OpenAI-compatible. Swapping in Fugu for a pilot is a two-line config change in any codebase that already calls OpenAI. Two weeks from now, independent benchmark evaluations from LMSYS Chatbot Arena or Artificial Analysis will tell us whether the vendor numbers hold up — that's the verification event worth waiting for before committing to production.


Add more perspectives or context around this Post.