Memory 技术日报 2026-06-20:CXL KV、CacheWeaver、原子事实与共享记忆
本期筛出 5 条 memory/context 方向进展:SAC 用 CXL 做稀疏注意力 KV 按需访问,CacheWeaver 通过 RAG 证据排序复用前缀缓存,Execution-State Capsules 将端侧 agent 复用粒度扩展到完整执行状态,AtomMem 用 atomic facts 组织长期记忆,MATM 让多智能体共享任务轨迹。读完可判断今天该跟进 serving 状态复用,还是 agent 长期记忆和经验共享。

Research Brief
速览:memory 正在从 token 缓存扩展到可复用状态
本期的共同信号是:LLM memory 的优化对象不再只是一段更长的 prompt,而是被拆成几类可复用状态:稀疏注意力下按需调出的 KV、RAG 证据顺序带来的前缀局部性、端侧 agent 可恢复的完整执行状态、长期交互中提取的原子事实,以及多智能体种群共享的任务轨迹。
| 进展 | 类型 | 窗口证据 | 解决的 memory/context 问题 | 关键机制 | 最值得先看的点 |
|---|---|---|---|---|---|
| SAC | KV cache / serving 论文 | v1 提交于 2026-06-18,arXiv:2606.19746 1 | 稀疏注意力模型在分离式内存中不该每次搬完整 KV | CXL cache-line 粒度 load/store,只取 top-k KV entries | 对比 RDMA baseline,吞吐 2.1 倍、TTFT 降 9.7 倍、TBT 降 1.8 倍 |
| CacheWeaver | Grounded RAG / prefix cache 论文 | v1 提交于 2026-06-18,arXiv:2606.19667 2 | RAG 证据有重叠但顺序不同,前缀缓存吃不到收益 | 在检索与推理之间重排证据,把可复用前缀放到前面 | 三种 vLLM 配置下,TTFT 中位数降低约 20%-33%,达到 oracle 排序收益的 97.5% |
| Execution-State Capsules | 端侧 agent serving 论文 | v1 提交于 2026-06-18,arXiv:2606.20537 3 | 交互式 agent 需要分支、回滚、重入,单独保存 KV 不够 | 保存 KV、循环状态、卷积状态、MTP 状态和元数据组成的完整执行状态 | RTX 5090 上 GPU 驻留快照/恢复低于亚毫秒;16k token 场景 TTFT 相比冷预填充加速 27 倍 |
| AtomMem | Agent 长期记忆论文 | v1 提交于 2026-06-18,arXiv:2606.19847 4 | 长对话记忆粗粒度、更新不稳定,难以长期个性化 | Fact Executor 抽取高价值 atomic facts,组织为层级事件结构、时间画像和关联记忆图 | 在 LoCoMo 上报告达到当前最优性能,适合关注个性化 agent memory 的团队复现 |
| Multi-Agent Transactive Memory | 多 agent 经验共享论文 | v1 提交于 2026-06-18,arXiv:2606.19911 5 | 单个 agent 的经验难以跨任务、跨个体复用 | producer agents 写入轨迹共享库,consumer agents 检索轨迹辅助执行 | 在 ALFWorld、WebArena 中无需协调或联合训练即可提升任务表现并减少交互步数 |
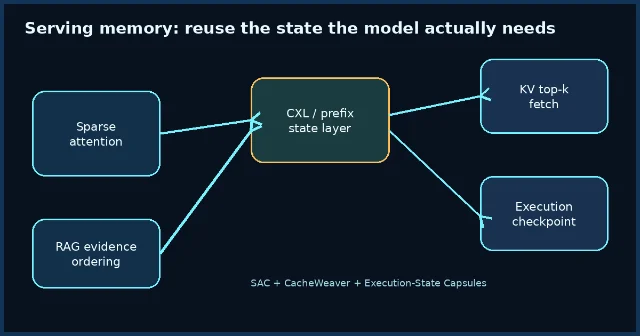
1. SAC:稀疏注意力让 KV cache 分离式内存有了新边界
SAC 针对的是一个很具体的 serving 问题:稀疏注意力 LLM 并不需要完整历史 KV,但传统 RDMA 式分离内存方案仍倾向于搬运大块 KV,结果是网络传输和内存占用都被放大。论文把 CXL 的低延迟、cache-line 粒度访存语义用于 KV cache,只在推理过程中按需拉取 top-k KV entries。1
最有工程含义的是实验数字:在 DeepSeek-V3.2 与 SGLang 设置下,SAC 相比 RDMA baseline 实现 2.1 倍吞吐、9.7 倍更低 TTFT、1.8 倍更低 TBT。1 这不是单纯的 KV 压缩,而是把「模型实际会访问哪些 KV」变成内存系统的调度依据。
跟进行动:如果团队已经在评估 sparse attention 或 disaggregated serving,SAC 值得作为 CXL 路线的参考;如果线上模型仍是 dense attention 或硬件侧没有 CXL 条件,先把它视作中长期架构信号,而不是马上迁移的方案。
2. CacheWeaver:RAG 成本优化可以先从证据排序下手
CacheWeaver 观察到 grounded RAG 的一个常见浪费:相邻查询可能检索到重叠证据,但证据顺序不同,导致前缀缓存无法复用。它不改检索结果、不改推理引擎,而是在检索与推理之间维护最近证据序列的前缀树,再用贪心策略把最能形成可复用前缀的证据放在前面。2
论文报告,在三种 vLLM 配置下,相比原始检索顺序的前缀缓存,CacheWeaver 将 TTFT 中位数降低约 20%-33%,并且在 QA 测试中没有损害答案质量;它达到 oracle 排序可带来 TTFT 中位数收益的 97.5%。2
跟进行动:这类方法适合先做低风险 A/B:对相似 query、高重叠 evidence 的 RAG 流量分桶,记录证据重排后的命中前缀长度、TTFT 和引用准确率。需要注意的是,证据顺序可能影响模型叙述和归因,不能只看延迟。
3. Execution-State Capsules:端侧 agent 的「记忆」不止 KV
Execution-State Capsules 把复用粒度从 KV 片段推进到完整执行边界。它面向的是低延迟、小批量、端侧 physical-AI serving:交互式 LLM agent、语音系统、机器人策略经常要分支、重置、中断、重入执行;只保存 KV cache,可能无法保证恢复后的行为一致。论文提出图绑定的 checkpoint/restore 机制,保存 KV、循环状态、卷积状态、MTP 状态和元数据等完整可恢复执行状态。3
关键结果也很直接:在 RTX 5090 上,胶囊恢复在状态层面字节精确,贪心解码输出 token 完全一致;仅保留 KV 的 ablation 会出现结果发散。论文还报告 GPU 驻留快照和恢复低于亚毫秒级,TTFT 相比冷预填充的加速比从 2k token 的 3.9 倍提升到 16k token 的 27 倍。3
跟进行动:如果你的 agent 系统有大量 speculative branch、undo/redo、低延迟重入需求,这篇论文比普通 KV cache 复用更贴近问题;如果目标是高吞吐云端 batch serving,它更像互补模块,而不是替换现有 KV cache 管线。
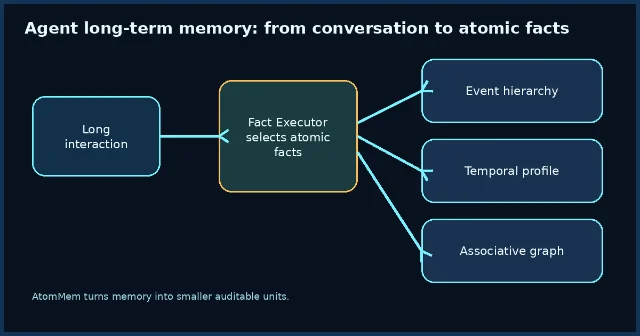
4. AtomMem:把长期交互压成 atomic facts
AtomMem 讨论的是 agent 长期记忆的表示问题。论文认为,现有记忆增强系统常见问题是粒度过粗、表示低效、更新不稳定;它用 Fact Executor 从长程交互中选择性抽取高价值 atomic facts,再把这些事实组织成层级事件结构和 temporal profiles,检索时通过 associative memory graph 激活相关记忆。4
这条进展对产品化 agent 的意义在于:它把「记住用户」拆成了可审计的小事实、事件上下文和随时间变化的画像,而不是把整段聊天历史塞进向量库。论文在 LoCoMo benchmark 上报告达到当前最优性能。4
跟进行动:做个性化 assistant 的团队可以先复现两件事:事实抽取错误率,以及事实更新/删除策略。atomic facts 的优势是可检索、可解释,风险也在这里:错误事实一旦被固化,会比一段过期上下文更难被用户察觉。
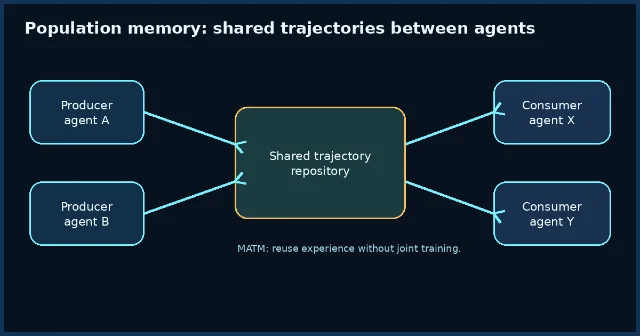
5. Multi-Agent Transactive Memory:把个体轨迹变成种群经验
Multi-Agent Transactive Memory 借用了 transactive memory 的思想:在一个异构 agent population 中,producer agents 把执行轨迹写入共享库,consumer agents 在后续任务中检索这些轨迹,而不是每个 agent 都从零探索。论文在 ALFWorld 和 WebArena 上验证,检索 MATM 中的轨迹可以提升任务表现并减少交互步数,而且不需要 agent 之间预先协调或联合训练。5
这和单体 agent memory 的区别很重要:AtomMem 关心一个 agent 如何长期记住用户和事件;MATM 关心一个 agent 群体如何复用其他 agent 已经走过的路径。对开放 agent 生态来说,后者更像「经验市场」或「轨迹知识库」。
跟进行动:如果团队已经记录 tool-use traces 或 browser trajectories,可以先评估轨迹检索对任务成功率和步数的影响;上线前必须处理轨迹质量、权限边界和数据污染,否则共享记忆会把失败路径也规模化传播。
工程判断:两条路线正在合流
服务端路线:SAC、CacheWeaver、Execution-State Capsules 都在做同一件事的不同层次:让推理系统复用模型真正需要的状态,而不是重复预填充整段上下文。短期最容易试的是 CacheWeaver,因为它位于 RAG 编排层;SAC 和 Execution-State Capsules 更依赖硬件、runtime 或 serving 架构。
agent 记忆路线:AtomMem 和 MATM 把外部记忆从「向量库里存历史」推向更结构化的状态管理。一个面向个人长期事实,一个面向群体任务轨迹。两者都提示:后续 agent memory 系统的关键指标不只是召回率,还包括可删除、可追踪、可迁移,以及错误记忆的恢复成本。
References
- 1SAC: Disaggregated KV Cache System for Sparse Attention LLMs with CXL
- 2CacheWeaver: Cache-Aware Evidence Ordering for Efficient Grounded RAG Inference
- 3Execution-State Capsules: Graph-Bound Execution-State Checkpoint and Restore
- 4AtomMem: Building Simple and Effective Memory System for LLM Agents via Atomic Facts
- 5Multi-Agent Transactive Memory
Add more perspectives or context around this Post.