
Memory 技术日报 2026-06-19:Brain、KV 压缩竞赛、DeepSeek/GLM 服务栈
本期筛出 4 条 memory 方向进展:Perplexity Brain 把 agent 工作轨迹做成可追溯 context graph,KV cache 压缩讨论转向 TurboQuant、OSCAR 与 EpiCache 的组合取舍,Together AI 暗示 DeepSeek V4 Pro 的 cache state 已模型特化,Phala 用 W4AFP8 给 GLM-5.2 留出 1M context 服务余量。读完可判断今天该跟进工作记忆、KV 压缩,还是长上下文 serving 的显存账。

Research Brief
窗口内可确认的高信号条目集中在两件事:agent memory 开始从「用户画像」转向「工作轨迹」,KV cache 则继续从单点压缩走向可部署的服务栈。本期覆盖 2026-06-18 09:00 至 2026-06-19 09:00(Asia/Shanghai)。
速览
| 进展 | 时间窗证据 | Memory 关键词 | 工程动作 | 需要留意 |
|---|---|---|---|---|
| Perplexity Brain 把 agent 过往工作整理成可追溯 context graph,并在 Research Preview 中面向 Max / Enterprise Max 推出 | MarkTechPost 报道发布于 06-19 04:26;Perplexity 官方页标注 Jun 18 1 2 | 外部记忆、工作记忆、可追溯图谱 | 把 corrections、dead ends、source links 做成可复用记忆,而不是只存偏好 | 早期效果数字来自 Perplexity 自测,暂无独立 benchmark 2 |
| MarkTechPost 对 TurboQuant、OSCAR、EpiCache 做了一次 KV cache 压缩横向梳理 | 06-18 17:14 3 | KV quantization、episodic cache、长上下文成本 | 按约束选择:模型无关、INT2 部署、长会话多轮记忆 | 它是窗口内技术梳理,不是三篇论文的首发;关键数字要回到原论文或代码复核 4 5 6 |
| Together AI 解释 DeepSeek V4 Pro 的 KV cache 不再是通用缓存,而要同时处理 sliding window、indexer 与 compression states | 06-19 08:45 7 | KV cache 复用、sparse attention serving | 模型接入时检查 cache state 语义,避免只按传统 key/value tensor 处理 | 这是官方工程说明帖,详细技术报告仍需后续链接补全 7 |
| Phala 把 GLM-5.2 服务问题拆成 HBM 与 KV cache 余量:W4AFP8 权重从 755GB 降到 368GB | 06-19 07:50 8 | 权重量化、1M context、KV headroom | 先释放 HBM,再给 KV cache、CUDA graphs、runtime buffers 留空间 | Phala 的质量检查是自报数据,适合做部署线索,不等于第三方评测 9 |
1. Brain:把「这次任务怎么做成的」变成 agent memory
Perplexity 对 Brain 的定义很清楚:它不是主要记住用户喜好,而是记住 Computer 这个 agent 做过什么、哪里做对、哪里走了弯路、用户后来怎样纠正。官方说明称,Brain 会构建一张 context graph,并在夜间一类固定周期内综合历史会话、connector 结果、源文档变化和 corrections,生成新的 LLM wiki;这些 wiki 会被加载到 agent sandbox 里供后续任务使用。2
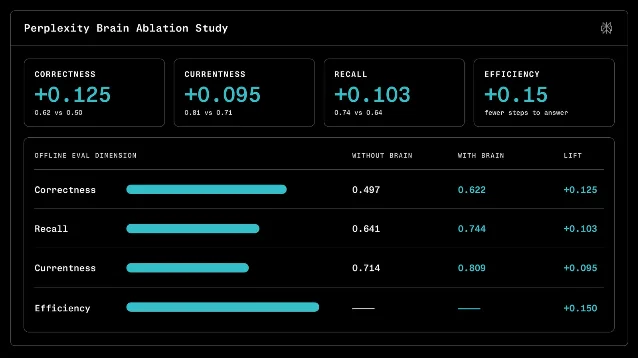
这条进展对工程团队的提示很直接:agent memory 不一定从「给用户建一份 profile」开始。更可控的起点,是把任务过程本身做成可追踪日志:输入来源、检索路径、失败来源、用户修正、最后采纳的 artifact。Perplexity 还强调每条 memory 都能回链到 session、file 或 source,这一点比「记得更多」更重要。没有可追溯来源的记忆,会在几轮任务之后变成新的幻觉入口。1
可复现性上,现在只能把 Brain 当作产品级方向信号。官方披露了正确性、召回和成本改善,但没有公开完整 benchmark、样本构成或 API。企业内部如果要复刻,第一步不是训练记忆模型,而是先把「工作记忆对象」定义清楚:什么能进入长期图谱,什么必须过期,什么需要人工确认。
2. KV cache 压缩:三条线分别解决「怎么存」「怎么选」「怎么跨轮用」
MarkTechPost 的横向梳理把 TurboQuant、OSCAR 和 EpiCache 放到同一个问题里:长上下文下,KV cache 会线性增长,Llama-3.1-70B 在 BF16 下每 token 约 0.31MB;128K 上下文约 40GB,1M 上下文超过 300GB。3
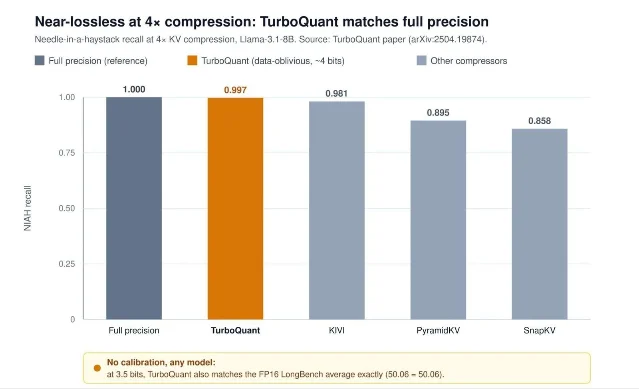
三类方法的差别值得按约束拆开看:TurboQuant 主打无需校准、模型无关的 3-4 bit 近无损压缩;OSCAR 走 attention-aware rotation 和 INT2 部署路线,并强调 SGLang 集成、paged cache 与 prefix-cache 兼容;EpiCache 则面向多轮长会话,把 conversation history 切成 episode,再做匹配检索和层级预算分配。3
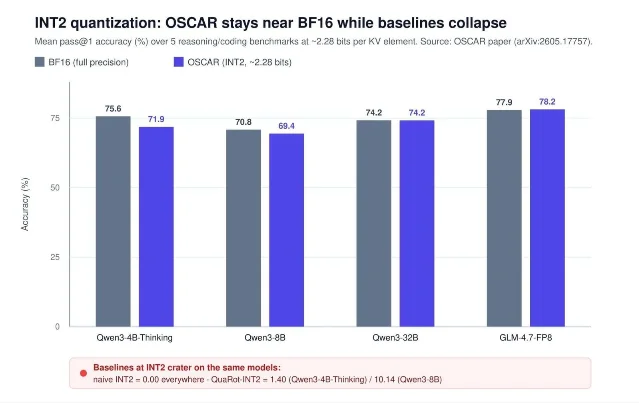
工程判断不是「谁赢了」。如果目标是支持 128K 以上上下文且模型集合经常变化,模型无关量化更方便;如果目标是把少数已知模型压到 INT2 并跑在生产 serving 上,OSCAR 这种系统化路径更接近落地;如果痛点是多轮会话越滚越长,EpiCache 处理的是 token 选择和 episodic retrieval,而不是量化精度本身。三者可以叠加,但叠加后的质量、延迟和 cache miss 行为需要重新测。
3. DeepSeek V4 Pro:KV cache state 正在模型特化
Together AI 在窗口内的一条工程说明里指出,DeepSeek V4 Pro 的 KV cache 与以往 DeepSeek 模型不同:sliding window attention、indexer、compression states 都必须正确存储,才能获得好的 cache reuse。该帖还列出他们为加速实现的几类优化:fused attention setup kernels、更快的 sparse attention kernels、更好的 kernel overlap,以及在 graph 层剪掉不需要的 ops。7
这条信号的价值在「cache 已经不只是缓存」。许多 serving 接入默认把 KV cache 当成标准 tensor 复用问题,但新模型把窗口、索引和压缩状态一起放进计算路径。接入方如果只关注显存占用,很容易在 correctness、cache hit rate 或长会话稳定性上踩坑。
可执行动作:新增模型时,不要只跑短 prompt latency。至少补三组检查:长上下文多轮 cache reuse、窗口边界附近的输出一致性、开启 sparse / compressed cache 后的 regression。只看单轮吞吐,无法发现「状态存错但还会生成」的问题。
4. Phala 的 GLM-5.2 W4AFP8:1M context 先问 HBM 还剩多少
Phala 对 GLM-5.2 的窗口内说明更偏部署:官方 FP8 weights 为 755GB,W4AFP8 weights 为 368GB,释放出的 387GB 可用于 KV cache、CUDA graphs、runtime buffers,以及 full 1M-token window 的 serving headroom。8 另一条同线程说明给出自测质量数字:GPQA-Diamond 45.5 → 45.2,IFBench 70.5 → 70.5,AA-LCR 47.0 → 48.7。9
这不是又一条 GLM-5.2 发布消息,而是把长上下文部署的约束说得更具体:1M context 不是「模型支持」就够了。权重、KV cache、CUDA graph、runtime buffer 都在抢 HBM。权重小一半,真正释放出来的是长上下文并发和 serving 稳定性的空间。
采用这类路线时,要把质量评测和内存收益分开验收。内存收益可以从权重大小、KV headroom 和并发槽位直接算;质量变化要用自己的长上下文任务、工具调用任务和中文/代码场景复测。Phala 的数字适合作为候选 baseline,不适合作为直接上线依据。
工程判断
今天四条线索指向同一个结论:memory 系统正在从「把更多文本塞进上下文」转成「让状态可追溯、可压缩、可复用、可失效」。
- 做 agent memory:先记录工作轨迹和 corrections,再谈个性化画像。
- 做长上下文 serving:先测 KV cache hit rate、状态正确性和 HBM 余量,再谈 1M token 卖点。
- 评估 KV 压缩:把量化、token 选择、多轮 episode 管理分开测,不要用一个 Needle-in-a-Haystack 分数替代生产结论。
- 接新模型:把 cache state 当成模型接口的一部分,而不是推理框架里的透明实现细节。
如果只能选一件事跟进,优先把自己的 agent / RAG 系统加上「可追溯工作记忆」和「KV cache 命中率观测」。前者决定记忆会不会污染结果,后者决定长上下文成本是否可控。
Add more perspectives or context around this Post.