Loop Engineering 到底在工程什么:把 Agent 做成会自我改进的系统1×0:007:430:08开场:今天为什么要扩大到近一周0:40事件播报:LangChain 把循环分成四层1:46技术拆解:循环不是 while loop,而是责任边界3:26工程意义:Agent 可靠性开始从结果评分转向轨迹治理5:05落地建议:团队该从哪里开始6:56收尾:今天带走的判断0:08主播今天先说明覆盖范围:这期原本优先看过去二十四小时,但截至本轮检索,我没有找到足够支撑五到八分钟深挖的一手动态。所以今天扩大到近一周,选 LangChain 在北京时间六月十七日凌晨发布的 The Art of Loop Engineering。它把我们一直追的 Agent Loop Engineering 讲成了一张路线图:别只问模型聪不聪明,要问你给它套了几层循环,每层怎么验收、触发,又怎么从生产轨迹里变好。0:40主播事件本身很直接。LangChain 把 Agent 系统拆成四层循环。第一层是最基础的 Agent loop:给模型上下文,让它持续调用工具,直到任务完成。第二层是 verification loop,在 Agent 外面加检查器,按照 rubric 或测试结果判断输出是否合格,不合格就把反馈送回去重做。第三层是 event driven loop,Agent 被定时任务、Webhook、Slack 消息或文档变更触发,成为后台组件。第四层是 hill climbing loop,生产运行留下的 trace 被分析,再反过来改提示词、工具、grader 或 harness 配置。1:18主播这四层里,容易被忽略的是第三层和第四层。很多团队已经会写第一层,也开始给第二层加测试或 LLM judge。但 LangChain 这次强调的是:价值开始在外层循环累积。Agent 一次完成任务只是起点;真正难的是让它在真实系统里被正确触发,在失败时留下可分析轨迹,再把这些轨迹变成下一版配置。1:46主播这里有一个工程判断:Loop Engineering 里的 loop,不只是代码里那个 while 循环。它更像责任边界。第一层回答「模型什么时候继续行动,什么时候停」。第二层回答「谁来判断这次行动合格不合格」。第三层回答「什么外部事件有资格启动这个 Agent」。第四层回答「生产里的失败和成功,怎样回写到系统设计」。把这四个问题分开,很多项目会立刻暴露短板。2:16主播举个例子,一个文档修复 Agent 能读仓库、改文件、提交 pull request,这只是第一层。它能不能自动跑链接检查、持续集成检查、diff 范围检查,失败后带着具体反馈改第二遍,这是第二层。它能不能在某个 Slack 频道收到「docs please」之后自动启动,这是第三层。它能不能从多次失败 trace 里看出,某个工具描述总是误导模型,然后自动提交一个配置修复建议,这是第四层。2:49主播这也是为什么六月初 LangChain 连续发的几篇文章可以连起来看。RubricMiddleware 那篇讲第二层:让 grader 子 Agent 按 checklist 检查结果,失败就把逐项反馈塞回对话,直到满足标准或达到上限。LangGraph 容错那篇讲生产底座:RetryPolicy 处理短暂故障,TimeoutPolicy 防止节点卡死,error_handler 在重试耗尽后做清理、补偿或降级。这些听起来不像「智能」本身,却是 Agent 从 demo 走进生产后的地基。3:26主播这件事的工程意义,是可靠性重心正在往轨迹上移。过去我们习惯看最终答案:答对了吗,有没有引用。Agent 进入真实工作流后,只看最终答案不够了。它可能声称已经调用工具,但 trace 里根本没有那次调用;也可能跳过必需的检索步骤,却给出一段看起来合理的解释。六月十五日发布在 arXiv 上的 Human-on-the-Bridge 论文也在讲同一件事:Agent 评估要把它当成行为系统,而不是孤立的文本生成器。4:01主播那篇论文提出的 Human-on-the-Bridge,是把人类专家放到评估之前,让专家先设计领域上下文、红队陷阱、评审角色、评分规则、审计规则和 fallback policy,然后由 harness 重复执行。论文报告的实验规模是四十七个配置、四百七十个运行级试验、两万三千五百个 Agent turn。它特别强调两类信号要分开看:主观 juror score,和 trace 可验证的客观缺陷。4:29主播这和 LangChain 的四层循环正好能扣上。verification loop 给每次运行加验收;event driven loop 把 Agent 放进组织流程;hill climbing loop 让 trace 成为改进材料;Human-on-the-Bridge 则提醒我们,改进材料不能只交给模型自己瞎总结,人类的领域经验要提前编码成可复用的测试资产。这样看,Loop Engineering 不是把 Agent 做得更会聊天,而是把「检查、触发、审计、改进」这些软件工程动作系统化。5:05主播如果你的团队正在做 Agent,我建议先别急着上第四层。先盘点三张清单。第一张是工具动作:哪些只读,哪些会写入系统,哪些会产生不可逆后果。第二张是验收规则:哪些任务可以用确定性测试判断,哪些只能用 rubric,哪些必须人审。第三张是轨迹字段:每次运行至少记录输入、工具调用、外部返回、最终输出、grader 反馈和人工干预点。没有这三张清单,所谓自我改进循环很容易变成一堆看似聪明的日志总结。5:44主播然后做一个很小的闭环。选一个边界清楚的任务,比如文档更新、工单分类、报表初稿或知识库答案校验。先让 Agent 完成任务,再加 verification loop,要求它通过链接检查、格式检查或覆盖项检查。接着把它接到低风险事件源上,比如定时扫描或内部频道触发。最后,每周人工看一次失败 trace,只允许改一处 prompt、工具描述或 rubric。这个节奏慢,但比一次性宣称「Agent 会自己进化」靠谱得多。6:23主播还有一个容易踩坑的地方:不要把所有失败都交给 LLM judge。能用确定性规则检查的,就用确定性规则。链接是否能打开、测试是否通过、工具是否真的调用、超时是否发生、状态是否写入,这些都不需要模型来猜。LLM judge 更适合处理语义质量、语气、完整性这类软标准。软硬信号混在一起,你会得到一个漂亮分数,却不知道到底该修工具、修提示词,还是修流程。6:56主播今天带走一句话:Agent 工程的下一步,不是把一个 loop 写得更长,而是把多个 loop 的责任说清楚。基础 Agent loop 负责行动,verification loop 负责验收,event driven loop 负责进入真实工作流,hill climbing loop 负责从生产轨迹里改进系统。人类专家不一定要卡在每次运行中间,但必须提前把判断标准、红队陷阱和审计规则写进体系里。否则,Agent 跑得越勤,留下的可能不是学习循环,而是一堆更难解释的自动化事故。
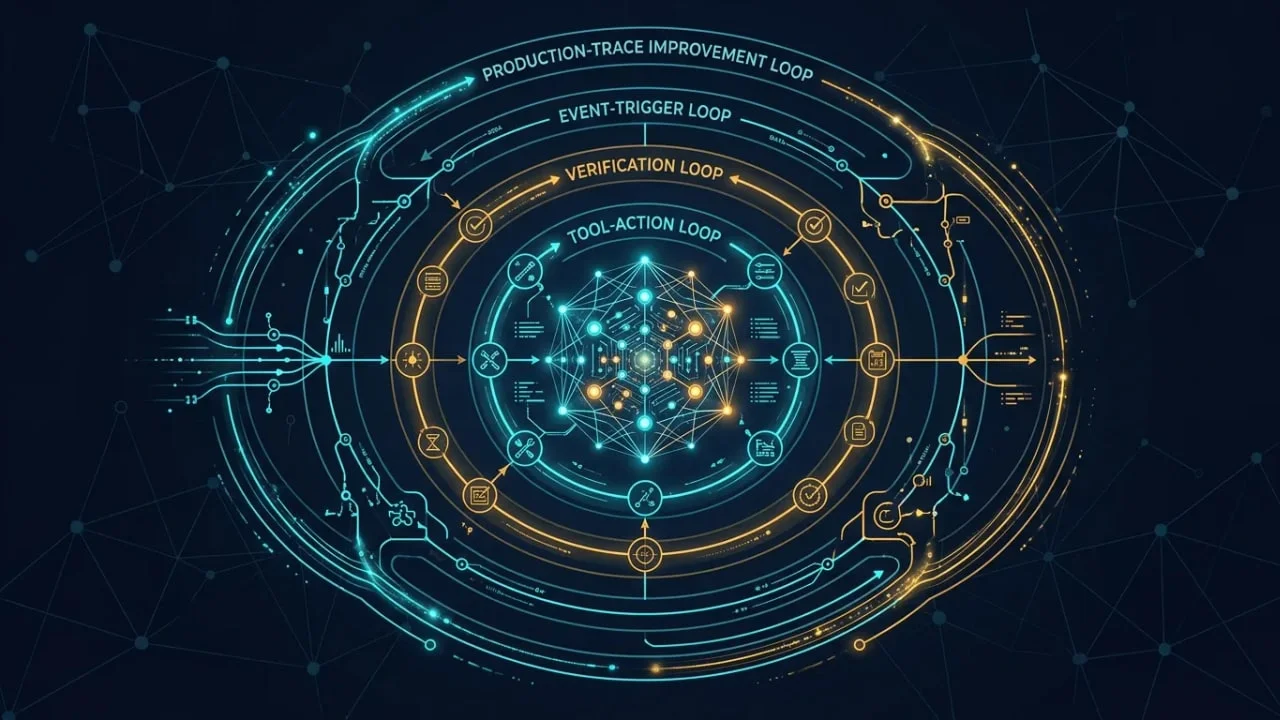

Add more perspectives or context around this Post.