2026. 6. 26. · 09:18
Five diffusion papers worth reading: June 26, 2026
Today’s digest highlights five diffusion papers on acceleration through reuse, world-space mechanics, and 3D-aware video geometry.

리서치 브리프
This issue covers the shorter daily window from June 25, 09:20 to June 26, 09:00 (UTC-5). The strongest signal is not a new image-quality benchmark. It is reuse: reuse cached DiT features, reuse token dynamics in diffusion language models, reuse geometry inside attention, or extrapolate the denoising trajectory without re-running every step.
The ranking below prioritizes method novelty, venue signal, practical deployment impact, and whether the result gives researchers a concrete reason to open the paper today. The top five are acceleration-heavy, but two papers, PhysiFormer and RayPE, are here because they change what a diffusion model treats as its native state space.
Speed-read table
| # | Paper | arXiv | Why it made the cut |
|---|---|---|---|
| 1 | LearniBridge | 2606.26778 | ICML 2026 paper; LoRA calibration for DiT feature caching reaches 5.87× on FLUX, 5.75× on HunyuanVideo, and 4.10× on WAN2.1 with only 3-5 training samples. 1 |
| 2 | Dynamic-dLLM | 2606.26120 | Training-free diffusion LLM acceleration exceeds 3× average speedup and reaches up to 4.48× on LLaDA-8B-Instruct while keeping accuracy within about 0.2% of baseline. 2 |
| 3 | PhysiFormer | 2606.27364 | Oxford/VGG diffusion transformer models 3D mesh vertex trajectories directly in world coordinates, trained on 100k+ simulated trajectories across rigid-body and elastic mechanics. 3 |
| 4 | RayPE | 2606.27345 | Adds 6D Plücker-coordinate ray-space positional encoding to video DiTs with less than 0.1% parameter overhead, improving camera controllability and cross-frame 3D consistency. 4 |
| 5 | ResilPhase | 2606.26769 | ECCV 2026 plug-and-play acceleration paper reframes inference as ODE macro-trajectory extrapolation with barycentric Lagrange extrapolation and bounded phase mapping. 5 |
1. LearniBridge: feature caching gets a learned correction layer
arXiv: 2606.26778 · Xuyue Huang, Zhe Chen, Wang Shen, Xiao-Ping Zhang · ICML 2026 · Code available 1
Why it ranks first
LearniBridge attacks one of the most practical bottlenecks in diffusion Transformer (DiT) serving: feature caching gets fast, then degrades when cached features drift across denoising timesteps. The paper's main claim is that the best calibration update shares a low-rank subspace across prompts, so a small LoRA bridge can correct cached features without retraining the full model. 1
The result is unusually deployment-shaped for an arXiv acceleration paper. LearniBridge reports 5.87× acceleration on FLUX, 5.75× on HunyuanVideo, and 4.10× on WAN2.1; the WAN2.1 result also improves VBench by 1.28% over the previous state of the art at the same 4.10× acceleration setting. 1 The calibration needs only 3-5 training samples, which is the detail that makes the method more than a lab-only trick. 1
Technical read
The method treats feature-cache error as a calibration problem rather than a scheduling problem. Existing caching methods usually reuse historical features for implementation simplicity; LearniBridge adds lightweight LoRA updates that bridge multiple timesteps and compensate for feature shift. 1
Read this first if your work touches DiT inference, video generation serving, or cache-based speedups. The code is linked from the arXiv record at
github.com/Iiiiiiirene/LearniBridge. 12. Dynamic-dLLM: dynamic caching for masked diffusion language models
arXiv: 2606.26120 · Tianyi Wu, Xiaoxi Sun, Yanhua Jiao, Yulin Li, Yixin Chen, YunHao Cao, Yiqi Hu, Zhuotao Tian · HIT Shenzhen + Huawei · Code available 2
Why it ranks second
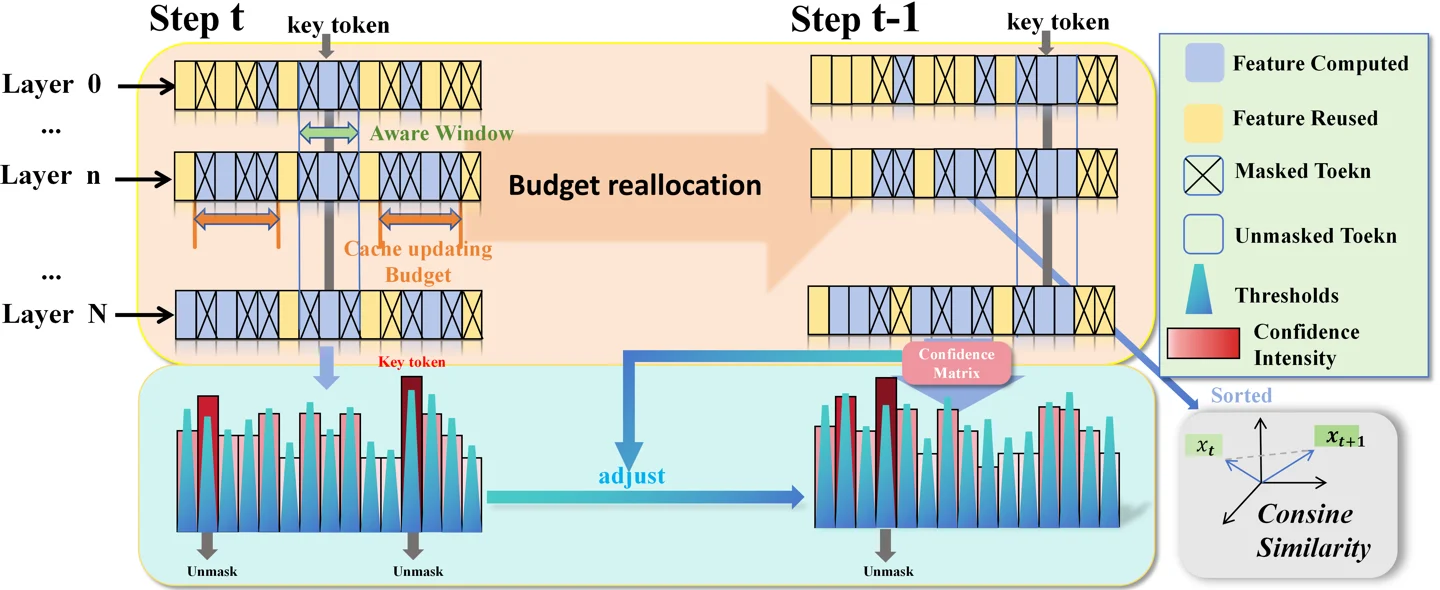
Dynamic-dLLM is the strongest language-model paper in today's diffusion set because it gives masked diffusion LLMs a concrete inference path. The framework is training-free and combines two mechanisms: Dynamic Cache Updating (DCU), which allocates cache-update budgets by layer based on token feature dynamics, and Adaptive Parallel Decoding (APD), which adjusts per-token decoding thresholds using confidence concentration and temporal instability. 2
The evaluation covers LLaDA-8B-Instruct, LLaDA-1.5, and Dream-v0-7B-Instruct across MMLU, GSM8K, HumanEval, ARC-C, and GPQA. 2 The headline result is an average speedup above 3×, with a maximum of 4.48× on LLaDA-8B-Instruct, while accuracy stays within about 0.2% of the baseline. 2
Technical read
The useful distinction is that Dynamic-dLLM does not assume token behavior is static across layers or decoding steps. Static caching and fixed parallel-decoding thresholds miss that variation; DCU and APD make the compute budget follow the model's own token dynamics. 2
This paper is also the best candidate for readers tracking whether diffusion LLMs can get a serving stack comparable to autoregressive LLMs. The linked code is
github.com/TianyiWu233/DYNAMIC-DLLM. 2 The paper's Figure 3 is a useful visual summary of the DCU-plus-APD pipeline. 63. PhysiFormer: diffusion simulation in world coordinates
arXiv: 2606.27364 · Yiming Chen, Yushi Lan, Andrea Vedaldi · Oxford/VGG · Project page available 3
Why it ranks third
PhysiFormer is not another video generator with a physics-themed benchmark. It models 3D mesh vertex trajectory prediction as a single denoising diffusion process directly in world coordinates. 3 That design choice matters because the model is no longer anchored to image-plane prediction; it learns mechanics in the coordinate system where the simulated objects actually move.
The training set contains 100k+ simulated trajectories covering rigid-body and elastic mechanics. 3 The architecture factorizes attention across time, space, and object dimensions, which lets the model reason over multiple objects while preserving permutation invariance. 3 The paper reports generalization to mixed materials, unseen real geometries, and larger object counts. 3
Technical read
The authors argue that coordinate-space diffusion is a path toward view-invariant, geometry-aware world modeling. 3 The evidence summary reports stronger trajectory accuracy, rigidity preservation, and momentum conservation than autoregressive baselines, though the public summary does not provide the exact benchmark table values. 3
Read PhysiFormer if your work sits between generative video, simulation, robotics, or 3D world models. The project page is linked from the summary at
yimingc9.github.io/physiformer. 34. RayPE: ray geometry enters video DiT attention
arXiv: 2606.27345 · Minghao Yin, Jiahao Lu, Wenbo Hu, Wang Zhao, Shan Ying, Kai Han 4
Why it ranks fourth
RayPE targets a narrow but important weakness in video DiTs: standard positional encodings describe an image sampling grid, not the 3D structure of the scene. The paper injects 6D Plücker coordinates into the self-attention queries and keys, using ray direction and moment to represent camera rays in 3D space. 4
The authors' core observation is algebraic: the Plücker reciprocal product has a bilinear form that matches the dot-product form used by Transformer attention. 4 That makes the encoding more than a geometry tag bolted onto the model. It changes the attention score into a mix of content terms, geometry terms, and cross terms, and the paper reports that each term is necessary. 4
Technical read
RayPE decouples ray direction and moment magnitude, then uses gating and RMSNorm to align the geometric signal with pretrained video DiT weights. 4 The parameter overhead is below 0.1%, and zero initialization keeps the method compatible with pretrained models. 4
The paper reports mixed training on four datasets and improvements in camera controllability, cross-frame 3D consistency, and overall video quality. 4 Read it if your current positional-encoding stack still treats camera motion as a 2D token-index problem.
5. ResilPhase: macro-trajectory extrapolation instead of feature forecasting
arXiv: 2606.26769 · Qicheng Zhao, Yu Li, Qi Sun, Zheyu Yan · ECCV 2026 5
Why it ranks fifth
ResilPhase is the second plug-and-play acceleration paper in the top five, but it differs from LearniBridge. LearniBridge calibrates cached DiT features; ResilPhase reframes accelerated inference as stable macro-trajectory extrapolation in ordinary differential equation (ODE) space. 5
The critique is specific. Existing "cache-then-forecast" methods predict intermediate features with derivative-based polynomial extrapolation, but those local feature forecasts can misalign with the continuous denoising trajectory and amplify high-order derivative noise. 5 ResilPhase instead aligns global drift, the end-to-end state evolution over a macro step. 5
Technical read
The method uses a derivative-free barycentric Lagrange extrapolator and a bounded phase mapping that regularizes the extrapolation domain to suppress oscillatory error growth. 5 The paper reports state-of-the-art fidelity under aggressive acceleration on FLUX.1-dev and HunyuanVideo. 5
Read ResilPhase if you are comparing sampler-side acceleration methods or trying to understand when feature forecasting breaks. It is less immediately plug-and-play than a cache calibration layer, but the ODE framing gives it a stronger theoretical hook.
Reading order by research area
For DiT serving and inference cost, start with LearniBridge, then read ResilPhase. For diffusion language models, Dynamic-dLLM is the main paper. For world models and simulation, PhysiFormer is the one to open first. For video generation with camera control, RayPE is the most targeted read.
Today's runner-up list is also strong: NaviCache, SharpMoE, LiveEdit, TMP, and the DP hypernetwork paper each have a clear use case. They lost out mainly because the top five either have stronger venue signal, broader deployment relevance, or a cleaner methodological jump.
Cover image: Figure 3 from the Dynamic-dLLM full paper.


이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.