2026. 6. 25. · 11:03
Claude 3.7 Sonnet made reasoning a runtime control, not a separate model
Anthropic's February 2025 Claude 3.7 Sonnet launch introduced hybrid reasoning, visible extended thinking, API thinking budgets, and the first Claude Code preview. This deep dive explains why the release mattered as a new control surface for latency, cost, transparency, and agentic software work.

Claude 3.7 Sonnet did not introduce reasoning as a separate side product. Anthropic's more interesting move was to make reasoning a runtime choice inside the same model: answer quickly, or spend extra tokens thinking before responding. That product decision turned "reasoning" from a benchmark label into an application parameter. Anthropic announced Claude 3.7 Sonnet on February 24, 2025 as its most intelligent model to date, described it as the first generally available hybrid reasoning model, and paired it with the first Claude Code research preview for agentic coding from the terminal.1
The release was really about control surfaces
Most model launches ask users to compare scores. Claude 3.7 Sonnet asked a different question: who decides how much cognition an answer should buy?
Anthropic's launch post said the same model could produce near-instant answers or visible, step-by-step extended thinking. It also said API users could set a thinking budget, with any value up to the model's 128K output limit.1 That is the product hinge. The developer no longer only chooses a model name, temperature, and max output. The developer also decides whether a request deserves extra latency and output-token cost.
The launch table stakes were broad availability. Anthropic made Claude 3.7 Sonnet available on Free, Pro, Team, and Enterprise Claude plans, plus the Claude Developer Platform, Amazon Bedrock, and Google Cloud Vertex AI; extended thinking was available on all of those surfaces except the free Claude tier.1 Pricing also mattered: Anthropic kept the same $3 per million input tokens and $15 per million output tokens as predecessor Sonnet models, with thinking tokens included as output tokens.1
| Surface | What changed | Why it mattered |
|---|---|---|
| Model behavior | Standard and extended-thinking modes lived inside one Claude 3.7 Sonnet model.1 | Teams could route simple and difficult tasks to one model rather than maintain a separate reasoning-model lane. |
| API control | Developers could set a thinking budget rather than accept one fixed reasoning depth.1 | Latency, cost, and answer quality became tunable per request. |
| Claude Code | Anthropic introduced Claude Code as a limited research preview that could search and read code, edit files, run tests, commit, push to GitHub, and use command-line tools.1 | The model launch was tied to a real work loop, not just chat. |
| Safety posture | Anthropic said Claude 3.7 Sonnet remained appropriate for ASL-2 safeguards, while also reporting stronger computer-use defenses against prompt injection.2 | More agency forced the release to ship with new monitoring and mitigation claims, not just capability claims. |
Visible thinking was useful, but not a safety proof
Anthropic's companion post on extended thinking was unusually candid about the trade. It said users could toggle extended thinking on or off, and developers could set a thinking budget.2 It also said extended thinking was not a switch to a different model, but the same model spending more time and effort before answering.2
콘텐츠 카드를 불러오는 중…
That matters because visible reasoning can create a false sense of auditability. Anthropic listed trust, alignment research, and user interest as benefits of showing Claude's thought process.2 But the same post warned that the visible thought process may be detached, may contain incorrect or half-baked thoughts, and may not faithfully represent the mechanisms that produced the final answer.2
The strongest sentence in that post is the safety caveat: Anthropic said current models often make decisions based on factors they do not explicitly discuss in their thinking, so monitoring visible thinking cannot support strong safety arguments by itself.2 In other words, Claude 3.7 made reasoning more inspectable to users, but it did not make chain-of-thought a ground-truth trace of cognition.
That tension explains the product design. For users, visible thinking helps debug a hard answer. For platform builders, the API needs separate mechanics for budget, display, redaction, and continuity. Anthropic's current extended-thinking documentation describes
thinking content blocks followed by normal text blocks, says budget_tokens limits the internal reasoning process, and notes that budget_tokens must be less than max_tokens except in the interleaved-thinking-with-tools case.3 The same docs say omitted display can reduce time-to-first-text-token but does not reduce billing, because the full thinking tokens are still charged.3Coding was the proof point
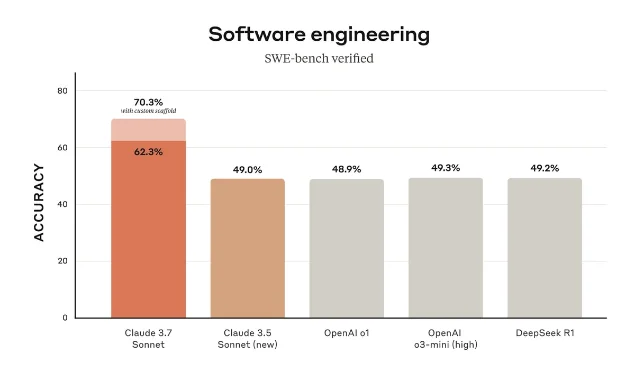
Claude 3.7 Sonnet's clearest commercial target was software work. Anthropic said the model showed strong improvements in coding and front-end web development, and it framed Claude Code as a way for developers to delegate substantial engineering tasks from the terminal.1 The appendix added an important benchmark detail: on the subset of 489 SWE-bench Verified tasks that worked on Anthropic's infrastructure, Claude 3.7 Sonnet scored 63.7% without the high-compute scaffold and 70.3% with additional parallel attempts, rejection against visible regression tests, and a scoring model.1
This is where the launch connected model design with agent design. A coding agent needs to decide what to inspect, what to edit, which tests to run, and when to stop. A visible or budgeted thinking mode is useful only if the surrounding tool loop can turn that deliberation into action. Claude Code was early, but the release made Anthropic's direction clear: the model is evaluated inside a workflow, and the workflow feeds back into model development.
Anthropic's later Economic Index update gave a useful usage-side check. In the 11 days after the Claude 3.7 Sonnet launch, Anthropic analyzed 1 million anonymized Claude.ai Free and Pro conversations, with most of the data coming from Claude 3.7 Sonnet because it was the default on Claude.ai and the mobile app.4 The same report said extended thinking was used most often in technical and creative problem-solving contexts, with tasks associated with computer and information research scientists near 10%, software developers around 8%, multimedia artists around 7%, and video game designers around 6%.4
The safety story moved closer to deployment mechanics
The release also exposed a new safety pattern. For ordinary chat, refusal quality and harmful-content handling are central. For a thinking, tool-using model, the risk surface expands to prompt injection, hidden malicious instructions, redacted thoughts, and whether the model's stated reasoning should be trusted.
Anthropic said Claude 3.7 Sonnet reduced unnecessary refusals by 45% compared with its predecessor.1 In the extended-thinking post, it also said new prompt-injection defenses for computer use prevented attacks 88% of the time, up from 74% without mitigations, with a 0.5% false-positive rate.2 And for rare cases where the thought process might contain high-risk content, Anthropic said it would encrypt the relevant portion and show users that the rest of the thought process was unavailable.2
Those claims are not just footnotes. They show why hybrid reasoning is not only a capability feature. Once a model can think longer, act through tools, and expose some internal deliberation, product governance has to decide what users see, what developers pay for, what gets redacted, and what the model must preserve across tool calls.
Claude 3.7 Sonnet's lasting contribution was not simply that it answered harder questions. It made reasoning operational. After this launch, "how much should the model think?" became a design decision that sits beside context length, tool access, latency budget, and safety policy.



이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.