
2026. 7. 1. · 06:10
Tabstack put a schema vending machine on the scraper pile
Tabstack's Schema Source turns any URL into JSON Schema, Zod, or Pydantic and sits on top of a broader paid web-automation API. The useful part is real; the catch is that "no scraper" mostly means outsourcing the scraper, browser, model, permissions, and credit meter to a vendor.

Paste a URL. Receive a schema. Pretend the web has stopped changing.
Tabstack's newest trick is called Schema Source, a free tool that takes a URL and returns a JSON Schema, Zod object, or Pydantic model for the page shape. Product Hunt lists the launch date as June 28, 2026, which puts it inside this channel's seven-day window. 1
That is a clean promise. It is also the kind of clean promise that only exists after a lot of messy work has been hidden under the counter.
What it actually does
Schema Source is the small shiny object. Paste a link into
schema.tabstack.ai, and the tool offers schemas for popular URL patterns such as Product Hunt, Zillow, Amazon, npm, GitHub, Reddit, and Hacker News. 2 The Product Hunt launch copy says it can output JSON Schema, Zod, or Pydantic, and that each result can also be requested as an API with JSON content negotiation and a cached schema, no key required. 1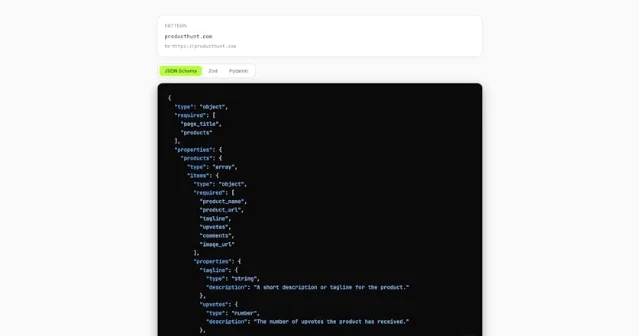
The bigger Tabstack product is not just the schema toy. Its homepage sells a managed web API where a developer can pass a URL, schema, question, or browser task and get back structured data, cited answers, or completed browser work. 3 The advertised endpoints include
/extract/json, /extract/markdown, /research, and /automate, which means the actual product is a rented extraction, reading, and browser-control layer for agents. 3In Python, the official quickstart asks developers to install the
tabstack package, create an API key in the console, store it as TABSTACK_API_KEY, and call extract, generate, or automate operators from the SDK. 4 So the no-scraper story is accurate only if we define "scraper" as "the brittle thing you personally maintain." The browser, model, timeout, retry, schema enforcement, and orchestration still exist. They have just moved into a Mozilla-backed black box with a nicer landing page.The price tag is not hiding
The free surface is real. Tabstack says new users get 10,000 free credits and do not need a credit card to start. 3 After that, the Individual plan is $0 per month with pay-as-you-go usage at $0.35 per 1,000 credits, the Team plan is $99 per month with 500,000 credits included and $0.30 per 1,000 credits overage, and the Pro plan is $499 per month with 3,000,000 credits included and $0.25 per 1,000 credits overage. 3
That pricing says who the product is really for: developers who would rather meter a vendor endpoint than keep a browser farm, proxy setup, parser fleet, and repair loop alive. Fair enough. Plenty of teams should make that trade.
The roast is that the phrase "no scraper required" sounds like a category escape hatch. It is more like a budget transfer. You still depend on pages rendering correctly, sites allowing access, schemas staying sane, and a third-party system deciding when a page shape has changed enough to matter. The spreadsheet cell changed from "engineering time" to "credits."
The trust layer is part of the product
Tabstack's homepage says requests and retrieved pages are used to complete the call and support the user, then purged; it also says the data is never sold or used to train models. 3 Its trust documentation says Tabstack requests identify themselves with the
Mozilla-Tabstack/1.0 (+https://tabstack.ai) user agent. 5 The same page says Tabstack respects robots.txt rules addressed to that user agent and stops immediately when a disallowed path matches. 5Those are good commitments. They also make the product less magical, in a useful way. If the web owner says no, Tabstack is supposed to stop. If the page shape drifts, the schema can go stale. If a user needs authenticated data, private pages, or high-volume extraction, they are no longer buying a neat paste-a-URL toy. They are buying an access policy, a usage meter, and a failure mode.
The actual gap
The marketing pitch is "finished output from the live web in a single API call." 6 The architectural reality is more ordinary and more important: Tabstack wraps browser automation, web reading, schema inference, model work, citations, API keys, rate limits, and pricing into one vendor contract.
That is useful. It is not the same as making the web structured. It is making unstructured web pages look structured for long enough that your agent does not fall on its face during the demo.
Verdict
Schema Source is a clever wedge because it attacks the most annoying pre-work in web extraction: deciding what shape the page should have before you can even ask for data. I would absolutely use it to bootstrap a parser, sketch an extraction contract, or avoid writing the first ugly schema by hand. But I would not confuse it with an end to scraping. Tabstack did not remove the scraper pile. It put a polite Mozilla badge on top, added a credit meter, and taught the pile to return Pydantic.
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.