
2026. 6. 16. · 00:14
Anthropic Negotiates in DC, GitHub's Agent Security Layer Goes GA, and Gemma 3 Ran in Orbit — Digest for June 15, 2026
Five items for builders today: Anthropic officials traveled to Washington over the weekend to reverse the Trump administration's export ban on Fable 5 and Mythos 5, with no resolution yet as of Monday morning; GitHub's automatic security scanning — CodeQL, dependency checks, and secret scanning — now covers all third-party coding agents including Claude and Codex by default; MLCommons releases the first standardized on-device LLM benchmark suite for Android in MLPerf Mobile v6.0; NASA JPL ran Google's Gemma 3 vision-language model aboard a satellite in orbit for the first time; and OpenAI launched a formal partner network with $150M committed and a target of 300,000 certified consultants by year end.

리서치 브리프
Anthropic's executives spent the weekend in Washington trying to undo a government order that cut off foreign access to Fable 5 and Mythos 5 three days ago. As of Monday morning they haven't succeeded — but the talks are moving. Here's what else happened today that builders should know about.
Anthropic is negotiating with the Trump administration to restore Fable 5 access
Anthropic officials traveled to Washington over the weekend and met with Commerce Secretary Howard Lutnick and National Cyber Director Sean Cairncross to push for the restrictions to be reversed, according to a Wall Street Journal report confirmed Monday.1
The Department of Commerce's order, issued Friday June 13, bars foreign governments, companies, and individuals from using Fable 5 and Mythos 5 — including foreign-national employees working inside the US. The stated reason is national security, tied in part to a public jailbreak demonstration by a researcher known as "Pliny the Liberator" who used a multi-agent decomposition technique to extract dangerous output from the model.2
Cybersecurity executives who signed an open letter to the administration argued that Fable 5 has no unique capabilities unavailable in other deployed frontier models — GPT-5.5 and Gemini 3.1 Pro remain accessible — and that the restriction weakens US AI leadership without meaningfully reducing risk. Anthropic has maintained that the technique demonstrated does not constitute a universal bypass and that it has not seen evidence of a harmful result from any jailbreak.
No return date for Fable 5 has been given. Teams relying on its capabilities at the API level should treat this as open-ended and audit which workflows can fall back to Opus 4.8 and which cannot.3
GitHub security validation now covers Claude, Codex, and other third-party coding agents
As of June 9, GitHub applies the same automatic security checks to pull requests created by any third-party coding agent that it already applies to its own Copilot cloud agent.4
That means: CodeQL analysis for potential vulnerabilities, dependency checks against the GitHub Advisory Database, and secret scanning for API keys and tokens. If the scan finds something, the agent attempts to fix it before finalizing the PR. Agents covered include Claude and OpenAI Codex.
The feature requires no GitHub Advanced Security license, follows your existing Copilot repository settings, and is on by default. GitHub says it has prevented hundreds of potential security leaks since rolling out the equivalent check for Copilot cloud agent in October 2025 — this extends the same net to everything else writing code in your repo.
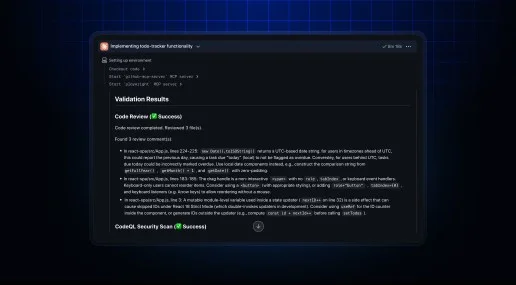
For teams already running Claude Code or Codex in their repos, this is purely additive — nothing to configure.
MLPerf Mobile v6.0 adds the first standardized on-device LLM benchmarks for Android
MLCommons released MLPerf Mobile v6.0 today, and the headline addition is a set of generative AI benchmark tests that measure LLM inference on Android phones — the first standardized benchmark for this class of workload.5
The models tested: Llama 3.2 1B Instruct, Llama 3.2 3B Instruct, and Llama 3.1 8B Instruct. Tasks draw from the TinyMMLU and IFEval datasets and measure both throughput and accuracy of on-device inference.
A few practical notes:
- The 1B and 3B tests run entirely on CPU — no specialized NPU acceleration required — which means most modern Android devices can participate.
- The 8B model gains NPU-accelerated execution on Qualcomm Snapdragon 8 Elite Gen 5 SoCs in this release; more chipsets are planned.
- New SoC support added: MediaTek Dimensity 9500 Series, with updated support for Samsung Exynos 2600.
통계 카드를 불러오는 중…
The app is available on Google Play and the App Store, with Apache 2.0 source on GitHub. If you're building on-device AI features or evaluating edge hardware, this benchmark suite is now a practical reference point rather than just a data-center scoreboard.
콘텐츠 카드를 불러오는 중…
A NASA JPL vision-language model ran on a satellite in orbit — first time this has happened
In April, NASA's Jet Propulsion Laboratory ran Google's Gemma 3 vision-language model aboard Yam-9, a satellite operated by Loft Orbital. It's the first reported deployment of a VLM in orbit, and TechCrunch published the details Monday.6

Researchers queried the model in natural language — classify sensor data at the border between natural environment and human development, identify infrastructure around railway hubs — and the model processed the imagery onboard without downlinking raw data first. The hardware running it: an Nvidia Jetson Orin AGX GPU, the same edge compute module used in a lot of robotics and embedded AI projects.
Why Gemma 3 specifically: it's designed for edge deployment, meaning it runs on limited hardware without a data center nearby. JPL's team, led by Juan Delfa Victoria, had to strip libraries and reduce memory footprint to make it fit the onboard environment.
The practical implication isn't "AI in space" as a novelty — it's that satellites can now do first-pass data triage in orbit, reducing the volume of raw imagery ground analysts have to process. Planet Labs already flies Jetson Orin processors and says it's researching VLM applications. Kepler Communications, which operates the largest orbital GPU cluster currently in service, declined to discuss specific deployments but confirmed "several undisclosed use cases" are already running.
Loft's head of AI, Paul Lasserre, put it plainly to TechCrunch: "If you have a VLM, you can have logic — like 'monitor this border for me, and let me know when something is suspicious.'" Getting there at full Earth-coverage scale would take 50–100 satellites like Yam-9; Loft currently has 12.
OpenAI launched a formal partner program with $150M committed
On June 14, OpenAI announced the OpenAI Partner Network — a tiered program for firms that build, sell, and deploy solutions on OpenAI technology.7
The structure:
- Three tiers: Select, Advanced, and Elite — differentiated by sales performance, technical certification, and deployment track record.
- Specializations: planned around Codex, cybersecurity, and agents, letting customers identify partners with specific expertise.
- Forward Deployed Experts: a pilot program where qualifying partner practitioners work alongside OpenAI's own forward-deployed engineering teams on complex enterprise deployments.
- Certification target: 300,000 certified consultants by end of 2026.
- Investment: $150 million committed to building the ecosystem.
Launch partners include Accenture, Bain, BCG, McKinsey's QuantumBlack, and PwC. The quoted outcomes from joint deployments: an 80% reduction in wait time for a Paychex payroll process (with Bain), and a "next-generation AI customer service platform" for eBay (with Artium).
For builders, the more relevant signal is the Codex and agents specialization track — that's where OpenAI is pointing partner expertise toward agentic coding workflows rather than just chat interfaces.
참고 출처
- 1Anthropic in talks with Trump administration to reverse AI model restrictions
- 2Anthropic blocks all public access to Claude Fable 5 and Mythos 5 following US government order
- 3Fable 5 suspended: developer action plan
- 4Security validation for third-party coding agents — GitHub Changelog
- 5MLPerf Mobile v6.0: New GenAI Benchmarks for On-Device LLMs
- 6A satellite just learned to find things on its own — here's what that means
- 7Introducing the OpenAI Partner Network



이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.