2026. 6. 30. · 07:23
Local AI crossed the PM line
Qwen 3.6 27B has moved local AI from hobbyist setup to PM-worthy product evaluation, with clear pilot paths and real deployment limits.

Local AI now deserves a product eval, not just a hobbyist tab.
Alibaba's Qwen team released Qwen 3.6 27B in April 2026 as a 27 billion-parameter dense causal language model under Apache 2.0, with a Gated DeltaNet and Gated Attention hybrid architecture, 262,144-token native context, and a path to roughly 1,010,000 tokens. 1 The release became a PM-relevant signal on June 29, when Piotr Migdał's Quesma deep dive on local development reached about 975 Hacker News points and 637 comments. 2 3
The short version: Qwen 3.6 27B is the first local model in this cycle that a PM should evaluate as an architecture choice. It is not a blanket Claude replacement. It is a strong candidate for supervised workflows where the product benefit comes from keeping inference local.
What changed
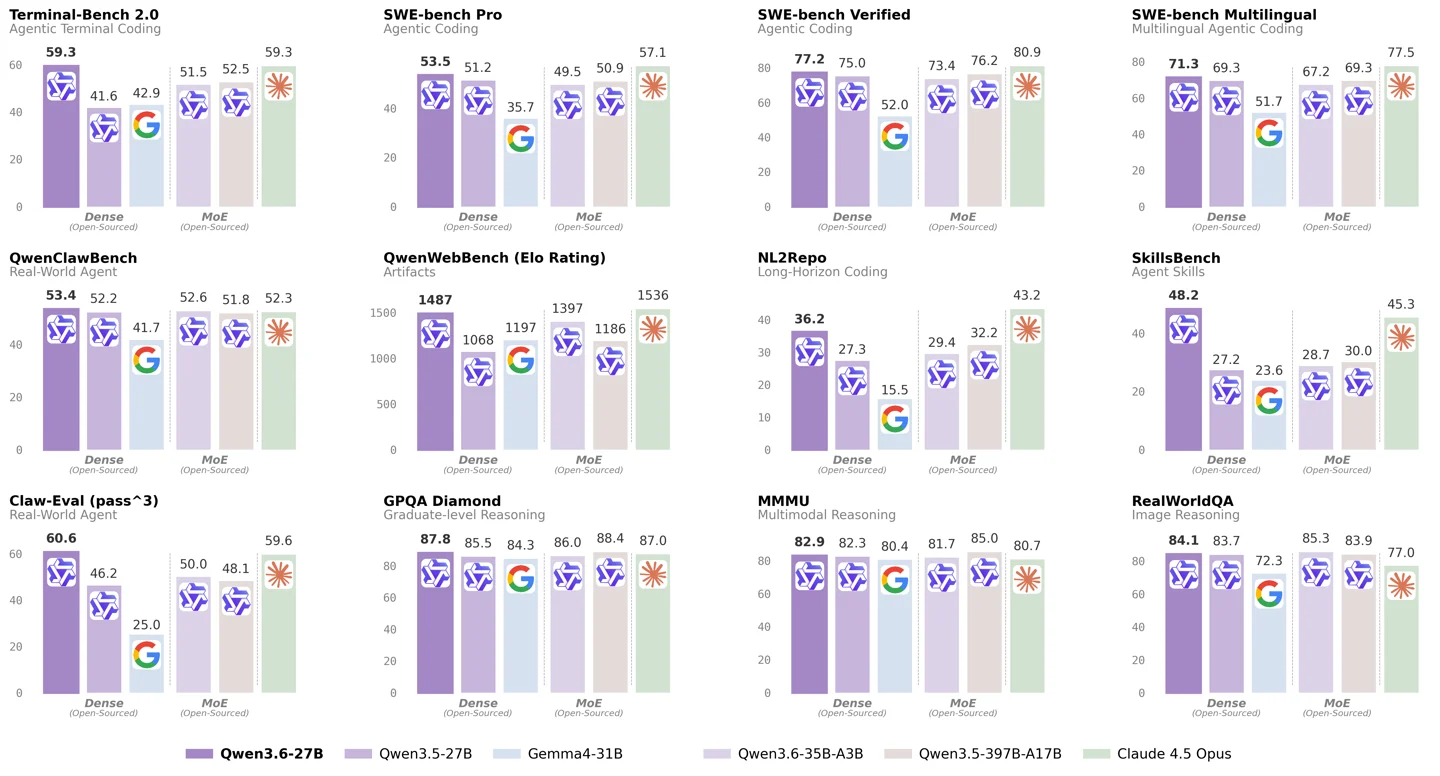
Qwen 3.6 27B is unusually strong for a model that can run on consumer hardware. The official model card reports 77.2 on SWE-bench Verified, compared with 80.9 for Claude 4.5 Opus; it also reports a tie with Claude 4.5 Opus at 59.3 on Terminal-Bench 2.0 and a higher SkillsBench Avg5 score, 48.2 versus 45.3. 1 The same model card reports more than 5.2 million monthly Hugging Face downloads, 531 community quantizations, and 257 fine-tunes. 1
The local-speed numbers are the reason this matters for product teams. Migdał reported 32 tokens per second on a MacBook Max M5 with 128GB memory using Q8 quantization, llama.cpp, and multi-token prediction; he also cited an RTX 5090 Q6_K setup producing 50 tokens per second at 123K context while using about 28GB of 32GB VRAM. 2 Simon Willison tested a 16.8GB Q4_K_M build through llama-server and measured 25.57 tokens per second, calling it an "outstanding result for a 16.8GB local model." 4
That puts local inference into a range where PMs can run real product pilots instead of treating local AI as a lab demo.
The PM translation
The product value is not "free Claude." The value is a different operating envelope: no per-query cloud API bill, no remote network round trip, and no user data leaving the device or private environment when the model runs locally. The Quesma deployment path uses local weights, llama.cpp, and an OpenAI-compatible API endpoint at
http://127.0.0.1:8080/v1, which means existing LLM tools can point at the local server rather than a hosted model. 2For a PM, that changes the feature backlog. Local AI becomes a plausible option for offline developer assistants, privacy-sensitive enterprise workflows, on-device code review, internal knowledge tools, and latency-sensitive copilots. The feature does not need to expose "Qwen" to the user. It can expose a capability: local draft, local triage, local repair suggestion, or local first pass before a cloud model handles the final answer.
The boundary matters. Codersera's analysis says Qwen 3.6 27B still has tool-calling JSON format errors around 12%, compared with 0.5% for Claude, and it reports long-context drift after roughly 14K tokens. 5 That makes Qwen 3.6 a fit for supervised workflows before it is a fit for fully autonomous production agents.
Where to try it first
Start with a narrow pilot where local inference has a product reason to exist. The strongest candidate is coding assistance, because Qwen 3.6 27B's public evidence is concentrated in coding and agentic benchmarks. The model card says Qwen 3.6 27B beats the previous open-source Qwen 3.5-397B-A17B flagship across major coding benchmarks. 1 Migdał used OpenCode and Qwen 3.6 27B to generate a complete Hex Minesweeper project from a single prompt, while Codersera frames the model as useful for engineers who understand the application they are building. 2 5
| Product workload | Local Qwen fit |
|---|---|
| Code review drafts | A good pilot if engineers review outputs before merge; the model has strong coding benchmark results and practical OpenCode examples. 1 2 |
| Security triage | A possible pilot, not an unsupervised gate; Will It Mythos reported that Qwen 3.6 27B found more bugs with fewer false positives than several commercial models across 9 real CVEs. 6 |
| Long internal-doc assistance | A cautious pilot; the model supports long context, but Codersera reports drift after roughly 14K tokens in local Claude Code-style usage. 1 5 |
| Fully autonomous agents | Too early for most products; tool-use reliability still trails Claude by a wide margin in Codersera's reported numbers. 5 |
The implementation path
The basic path is simple enough for a product prototype: pull a GGUF quantization, run
llama-server, expose an OpenAI-compatible local endpoint, then point an existing tool at that endpoint. Migdał recommends llama.cpp and gives a launch pattern using -hf unsloth/Qwen3.6-27B-MTP-GGUF:Q8_0, --spec-type draft-mtp, -ngl 999, -fa on, and -c 65536. 2 Codersera reports that runtime choice is a common failure source and argues that llama.cpp plus Q8 weights gives a more reliable experience than default Ollama 4-bit pulls for serious agentic work. 5The hardware floor is the catch. Codersera reports that Q8 weights need roughly 30GB of VRAM before KV cache, while a 48GB unified-memory Mac can fit Q8 plus context but may leave little room for the rest of a developer's environment. 5 A PM should treat this as a deployment-design constraint, not a reason to ignore the model. The first product version can run on a dedicated local box, a managed workstation class, or a private inference node before the team decides whether on-device support is broad enough.
The next-sprint eval
Do not start with a migration memo. Start with 30 real tasks from one workflow: code-review comments, test generation, security triage, PRD-to-plan conversion, or internal-document Q&A. Score Qwen 3.6 27B against the current cloud default on task completion, human edit distance, latency, tool-call validity, privacy benefit, and cost per accepted output.
The pass condition should be workload-specific. Qwen 3.6 27B does not need to beat the best cloud model on every task. It needs to be good enough on a bounded workflow where local execution changes the product promise. If that condition holds, the PM move is a router: local Qwen for private or high-volume first passes, cloud frontier models for final answers, unsupported modalities, and high-risk autonomous actions.
Cover image: image from Qwen Team / Alibaba.
참고 출처
- 1Qwen3.6-27B · Hugging Face Model Card
- 2Qwen 3.6 27B is the sweet spot for local development
- 3Qwen 3.6 27B is the sweet spot for local development (HN Discussion)
- 4Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model
- 5Qwen 3.6 27B: Local Claude Code Replacement?
- 6Will It Mythos? — Security Bug Finding Benchmark
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.