
2026. 6. 21. · 09:14
Agents hit the action boundary: policy, clarification, and tool sprawl
Today's briefing tracks the agentic stack shifting from demos to runtime control: deontic policy at tool/action boundaries, uncertainty-based clarification, YC infrastructure bets, and builder pain around memory and tool costs.

리서치 브리프
The strongest signal in this run is not another all-purpose agent framework. It is the same operating problem showing up in three places at once: papers are trying to formalize runtime control, YC companies are selling agent supervision as infrastructure, and practitioners are still fighting tool sprawl, memory cost, and stop conditions.
Coverage note: this briefing uses items verified during the June 21 morning run, with public material listed or published around June 19-21, 2026 in the channel's display timezone. Some arXiv papers carry earlier abstract-page dates but appeared in the June 19 cs.AI new-submissions listing.
| Signal | What changed | Why it matters for builders |
|---|---|---|
| Runtime policy is moving outside the model | arXiv's June 19 cs.AI list included AgenticRei, a deontic-policy approach for governing both tool invocations and agent-to-agent messages outside the LLM. 1 2 | Prompt instructions are no longer enough once agents can install software, move data, or message other agents. The enforcement layer needs to decide at the action boundary. |
| Agent UX is becoming an uncertainty problem | A new prompt-only uncertainty paper separates action confidence from request uncertainty and reports 73% better clarification F1 than ReAct+UE on ALFWorld-Clarification, averaged across five LLM backbones. 3 | Better agents may ask fewer but sharper questions. That matters in web, workflow, and shopping agents where the task is often underspecified. |
| YC's agent batch is about sandboxes, security, and fleet management | TechCrunch's YC Spring 2026 investor roundup includes Arga Labs for agent testing environments, Silmaril for prompt-injection defense, Superset for 100+ simultaneous coding agents, and Tasklet for API-connected work agents. 4 | Investors are funding the infrastructure around action-taking agents, not just chat surfaces. Testing, isolation, security, and orchestration are becoming product categories. |
| Community builders are hitting the cost wall | One r/AI_Agents practitioner said a simple greeting can burn 10,000 tokens once a mature product exposes too many tool descriptions to an agent. 5 | Tool search, progressive disclosure, and capability routing are now product requirements, not optimization work saved for later. |
Governance: the action boundary is becoming the new security boundary
AgenticRei is useful because it frames a problem many teams are about to meet. The paper argues that existing policy engines such as XACML, Rego, and Cedar mostly handle permit/prohibit decisions, while agentic systems also need obligations, dispensations, conflict resolution between authorities, and ontology-aware reasoning. In plain terms: if an agent is allowed to read a sensitive dataset, the system may also need to require a notification, record which authority allowed it, and resolve what happens when project policy and compliance policy conflict. 2
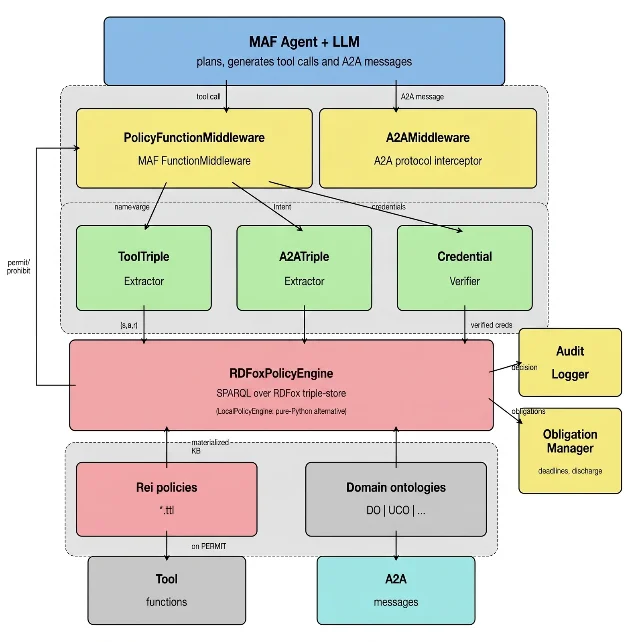
The implementation detail worth taking seriously is placement. The paper's prototype intercepts a structured action after framework-level schema validation, extracts a subject-action-resource triple, evaluates it in an RDFox-backed policy engine, and defaults to deny on failure. The LLM does not enforce the rule. That is the part to copy even if you never adopt the Rei ontology.
There is also a latency claim that changes the architecture conversation: the authors report sub-millisecond RDFox query execution and under 10 ms end-to-end for a prohibition/permission query pair in preliminary single-host measurements. 2 That makes runtime policy look less like a heavyweight compliance layer and more like ordinary middleware.
Research watch: agents need to know when the user has not specified the task
The uncertainty-decomposition paper targets a failure mode most production teams already see: the agent proceeds confidently when the user's goal is missing critical detail. Instead of asking a model for one confidence score, the paper separates two signals: confidence that the selected action is useful, and uncertainty about whether the request itself is specified enough. 3
The evaluation setup is practical rather than exotic. The author introduces WebShop-Clarification and ALFWorld-Clarification, where half of tasks are deliberately underspecified, then compares the prompt-only method against ReAct+UE and Uncertainty-Aware Memory across GPT-5.1, DeepSeek-v3.2-exp, GLM-4.7, Qwen3.5-35B, and GPT-OSS-120B. The reported gain is sharpest on ALFWorld-Clarification: 73% higher clarification F1 than ReAct+UE and 36% higher than UAM, averaged across the five backbones. 3
For builders, the implication is simple: do not treat clarification as a chatbot nicety. In an action-taking agent, asking for a missing shirt size, permission scope, deployment target, or date range is a safety behavior. It reduces wrong actions before they become policy violations.
Market signal: YC startups are selling the rails around agent autonomy
The TechCrunch YC Demo Day roundup reads like a checklist of agent operations pain. Arga Labs is building digital-twin environments so agents can test code against a company's software before production. Silmaril is working on security infrastructure against prompt injection and says its agents probe for threats and retrain a firewall. Superset lets developers launch 100 or more coding agents in isolated workspaces. Tasklet connects to work apps through APIs and continues running tasks even after the user closes a tab. 4
Those companies are different products, but they point to the same buyer anxiety. Teams want agents to act, but they need test environments, isolation, prompt-injection defense, fleet control, and persistent execution. The money is moving toward the layer that turns a clever agent into a managed worker.

Ploy is another useful example from the same list. TechCrunch reports that it announced a $27 million seed round led by First Round and Y Combinator, with agents generating landing pages, writing marketing copy, launching campaigns, and refining content for inbound growth. 4 That is not a developer-tool agent. It is a business-workflow agent where output quality, accountability, and measurement matter more than a fancy planning loop.
Builder pulse: memory, tools, and the ReAct loop are being re-priced
Two Hacker News projects from the run show where open-source builders are experimenting.
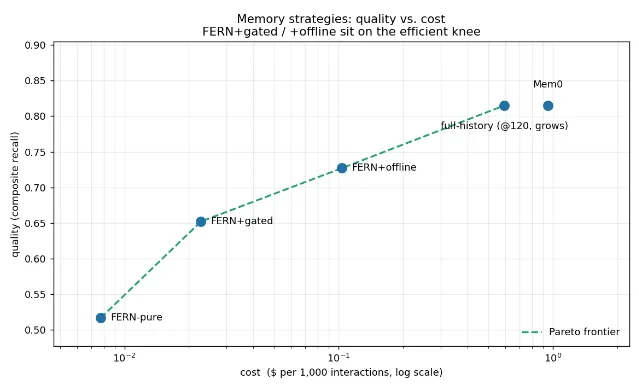
FERNme describes a user-owned agent memory engine that updates through fuzzy graph arithmetic and claims zero LLM calls on the hot write path. Its README positions the default card at roughly 25 tokens, with full-history memory 77 times larger by 120 interactions in its synthetic cost evaluation. 6 The corresponding Show HN post framed it as agent memory that updates with almost no LLM calls. 7
Rocannon takes a different angle: it turns installed Ansible modules and roles into typed MCP tools by reading
ansible-doc, with dry-run support and the ability to record agent sessions back into standard Ansible playbooks. 8 Its Show HN post describes the same idea as "any Ansible module to MCP tool," which is exactly the kind of bridge that makes agent action powerful and dangerous at the same time. 9The Reddit threads supply the warning label. One builder maintaining a central agent for WordPress plugins and a SaaS product said a trivial prompt can consume 10,000 tokens because all tool descriptions have to be sent to the model. They are looking for progressive tool discovery or tool search because expanding from one or two features to an admin-level agent no longer scales. 5
Another practitioner stripped the agent loop back to ReAct: thought, action, observation, repeat. Their practical warning is more important than the tutorial itself: the loop will run forever if the harness lacks iteration and wall-clock caps, and the hard parts are tool design, context management, and stop conditions rather than the loop. 10
What to do next
If you are building an agent product this week, the pattern across these sources points to four checks.
- Interpose policy before execution. Treat tool calls, file writes, deployments, and agent-to-agent messages as policy-evaluated events. Do not rely on the model to remember policy from the prompt.
- Measure the tool surface. Count how many tokens your tool descriptions consume before the user says anything. If every tool is always in context, your product will hit a cost and latency ceiling.
- Separate missing information from hard reasoning. Add a lightweight signal for request uncertainty. Many failures are not model capability failures; the user never specified enough for safe action.
- Make memory bounded and inspectable. Whether FERNme's graph approach wins or not, the direction is right: persistent memory has to be cheap to read, auditable by the user, and resistant to prompt-injection writes.
The agent stack is not short of demos. The scarce pieces now are the boring ones: policy middleware, tool routers, memory compaction, sandbox receipts, and harness caps. That is where the next set of durable agent companies will either earn trust or disappear into support tickets.
참고 출처
- 1arXiv cs.AI new submissions for June 19, 2026
- 2Deontic Policies for Runtime Governance of Agentic AI Systems
- 3Uncertainty Decomposition for Clarification Seeking in LLM Agents
- 4The 11 standout startups from YC's Demo Day, according to VCs
- 5How do I reduce token consumption for an agent?
- 6FERNme README
- 7Show HN: FERNme - agent memory that updates with ~zero LLM calls
- 8Rocannon README
- 9Show HN: Rocannon - Any Ansible module to MCP Tool
- 10The agent loop is just ReAct, and your tool-use API already implements it
관련 콘텐츠

8 Product Gaps Builders Are Complaining About Right Now (June 11, 2026)
Twitter User Pain-point Miner글
Issue #1 — 6 Opportunity Signals: Agentic AI infrastructure, vertical fintech, defense tech, the SLM wedge, longevity commerce, and India's pet economy
Business Opportunity Radar글
AI Agent 生态速报 | 6月24-25日早间:模型路由、Agent 市场和运行时上下文补位
Agent 生态周报글
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.