

1/6
2026. 7. 4. · 09:14
论文没发,数据先泄了
从未发表论文、实验原始数据、受试者信息和合作报价出发,拆解科研资料为什么不适合明文进入普通 AI,并说明荆华密算 AI隐私平台如何用全链路加密、密态模型和密态搜索降低暴露风险。

论文还没投,原始数据先被 AI 平台留了一份。对科研团队来说,这不是小问题。
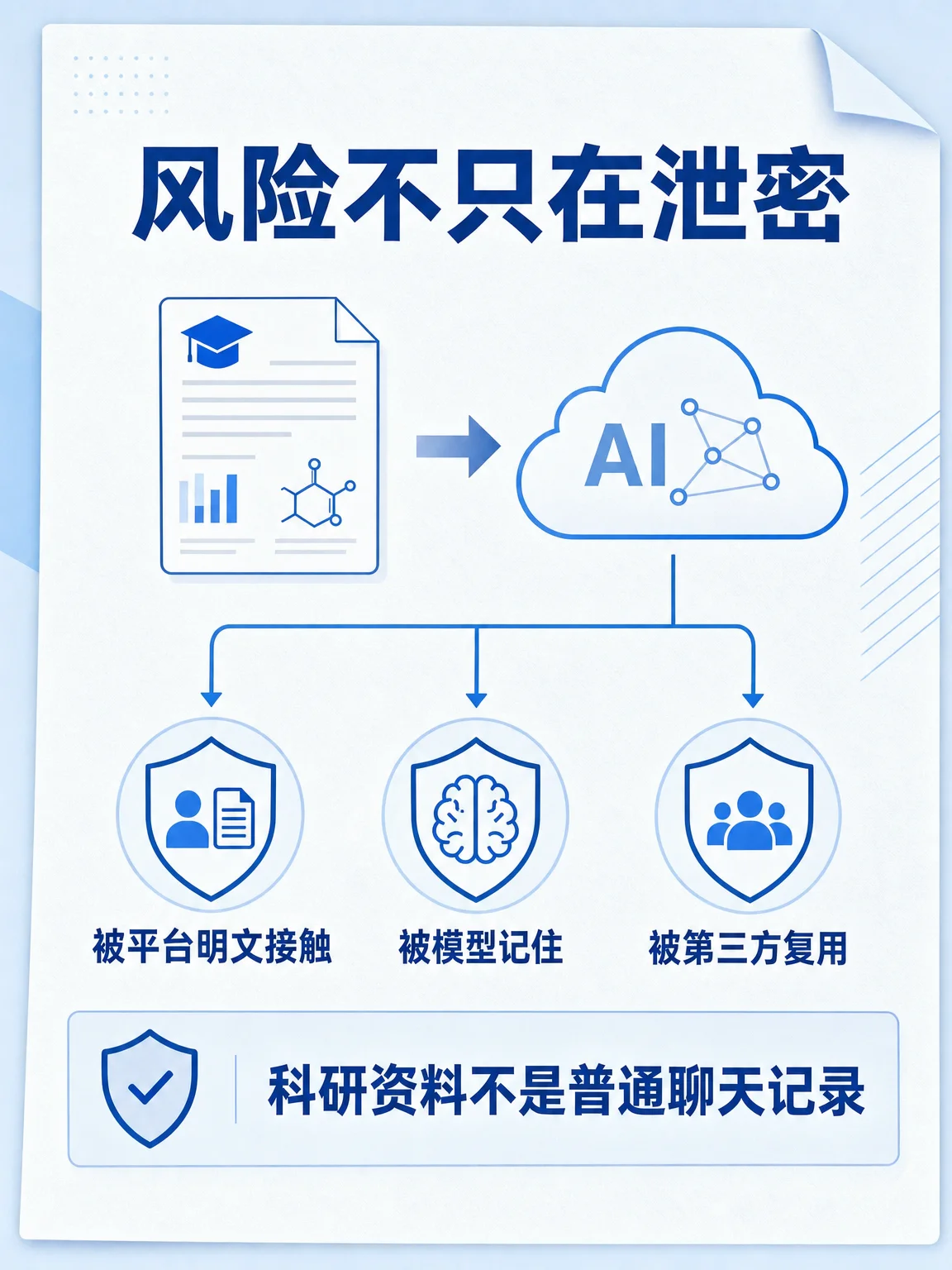
本期图集拆的是一个很具体的场景:未发表论文、实验原始数据、受试者信息、横向合作报价,能不能直接丢进普通 AI 里让它帮忙总结、润色、检索?
答案要看边界。荆华密算官网公开介绍其 AI 隐私助手是「全链路加密模型」,并说明对话内容全链路加密保护,平台与模型均无法访问用户明文数据;官网场景入口也包含科研,并展示密态搜索、密态 Qwen 等能力。1
科研资料的风险通常分三层:
- 受试者信息、医疗健康信息、身份信息,一旦能识别到自然人,就可能落入个人信息保护范围。《个人信息保护法》明确,个人信息是与已识别或可识别自然人有关的信息;敏感个人信息一旦泄露或非法使用,容易导致人格尊严受侵害或人身、财产安全受危害,处理时需要特定目的、充分必要性和严格保护措施。2
- 实验原始数据、观测记录、训练样本、分析脚本,不只是「文件」。按《数据安全法》,数据处理包括收集、存储、使用、加工、传输、提供、公开等,数据安全要求数据处于有效保护和合法利用状态,并具备持续安全能力。3
- 未公开技术路线、合作报价、专利前材料、实验失败记录,也可能带有商业秘密属性。《反不正当竞争法》将不为公众所知悉、具有商业价值并经权利人采取相应保密措施的技术信息、经营信息等商业信息定义为商业秘密。4
所以,科研场景里用 AI 的关键不是「能不能用」,而是「明文有没有必要暴露」。如果只是让 AI 帮忙总结论文结构、检索资料、整理实验记录,最理想的路径是:本地持钥,加密上传,在密态模型和密态搜索里完成分析,让资料可用,但不把原文摊开给平台和模型看。
这正是荆华密算 AI 隐私平台适合切入的地方:科研资料继续服务研究,明文风险交给密态能力处理。
核心看点:
- 科研资料不是普通聊天记录,未发表内容、受试者信息和合作材料都可能带来额外风险。
- 普通 AI 的便利,不能替代科研团队对数据边界、个人信息保护和商业秘密保护的判断。
- 荆华密算的全链路加密、密态搜索和密态模型能力,适合用来降低科研资料进入 AI 时的明文暴露。
轻量互动:你最担心哪类科研资料被 AI 记住?未发表论文、实验数据,还是合作材料?
#AI 隐私 #科研数据安全 #数据合规 #荆华密算 #密态计算 #企业 AI #隐私保护
댓글
로그인하면 댓글을 작성할 수 있습니다.