
2026. 6. 29. · 08:16
把系统用满,为什么会越跑越慢:排队论的隐形税
这篇长文从 Little’s Law、M/M/1 曲线、尾部延迟和重试风暴切入,解释为什么高利用率常把系统推入非线性变慢。读者将获得一套更稳妥的容量判断框架:看 goodput、方差、deadline 和重试预算,而不只看平均 QPS。

把一台机器用到 90%,听起来像节俭。排队论给出的图像更像心梗:血管还没完全堵住,流量已经开始塌。最小的 M/M/1 模型里,利用率 ρ 从 0.8 升到 0.9,系统里的平均作业数会从 4 个升到 9 个;到 0.99 时,平均作业数变成 99 个。这个模型假设到达服从泊松过程、服务时间服从指数分布,离真实系统很远,但那条曲线的形状没有骗人:越接近满载,等待时间越不像线性增长。1
这条曲线解释了很多日常坏体验。网页突然超时,客服排队突然从 2 分钟跳到 40 分钟,医院急诊在某个下午开始堵死,团队把 GPU 集群排到满负荷后发现吞吐没怎么涨,作业完成时间却变得无法预测。外表上是「需求涨了一点」,内部发生的是另一件事:系统失去了吸收波动的空地。
利用率不是效率的同义词
Little’s Law(利特尔法则)说,在稳定排队系统里,系统内平均作业数 L 等于平均到达率 λ 乘以平均停留时间 W,即 L = λW。John D. C. Little 在回顾这条法则 50 年历史时,把它说成一个几乎物理性的事实:一个人在队伍里被计数的同时,也在累积等待时间;同一块面积既能算平均人数,也能算平均等待。2
这个公式不直接告诉你该配多少服务器。它更像一面镜子:当停留时间变长,系统里同时悬着的作业数必然变多。服务器语境里,这些作业会占住内存、线程、连接、文件描述符、下游配额。Google SRE 书在讲级联故障时列过一条典型链路:CPU 不足让请求变慢,请求在途数量上升,占用更多内存,缓存命中率下降,更多请求打到后端,后端也耗尽 CPU 或线程,健康检查失败,故障开始扩散。3
这也是「机器都忙着」这个指标的陷阱。对财务表来说,闲置容量像浪费;对交互式系统来说,闲置容量是减震器。排队论课件把利用率列为输出指标时直接写了两面:高利用率有利于压低成本,低利用率有利于压低等待时间。它还提醒,连平均队长都不够用,等待区必须按高于平均的峰值来规划。1
80% 以后,曲线开始咬人
M/M/1 的平均在系统作业数是 L = ρ / (1 - ρ)。这条式子可以粗暴地翻译成一句话:剩余容量一旦变小,任何一点新增负载都会被放大。ρ = 0.5 时 L = 1;ρ = 0.8 时 L = 4;ρ = 0.9 时 L = 9;ρ = 0.99 时 L = 99。1
这个小表足以纠正一种直觉错误:从 80% 到 90% 不是「只多用了十分之一」。在单服务器、随机到达、随机服务的简化世界里,它让平均拥塞量翻倍还多。现实系统会因为多服务器、缓存、批处理、优先级、放弃排队、限流而偏离这条曲线,但「靠近 1 的分母」仍然是危险信号。
这条曲线给技术团队的教训很朴素:容量计划不能只问「平均请求能不能处理」。它还要问请求到达是否成团,单个请求的服务时间是否稳定,下游是否会把慢请求拖成长请求,拒绝请求的代价是否足够低。只看 QPS(每秒查询数)会把不同成本的请求混成一个数。Google SRE 的过载章节说,不同查询的资源需求可能差异很大,按 QPS 或「读多少 key」这类静态特征建模,经常是差指标;更稳妥的做法是直接度量 CPU、内存等资源消耗,并把每个请求消耗的 CPU 时间归一化为成本。4
方差才是暗税
平均值骗术在排队里有一个更具体的名字:变异性。M/G/1 模型把服务时间从指数分布放宽到任意分布后,等待时间里会出现一个乘数:(1 + SCV) / 2。SCV 是平方变异系数,衡量服务时间相对平均值的波动。课件把这条 Pollaczek-Khintchine 公式写成 VUT:变异性、利用率、服务时间三项相乘,并用一句话收束:Variability hurts。1
再放宽一点,到达间隔也可以有波动,Kingman 近似式把到达间隔的 SCV 和服务时间的 SCV 都放进等待时间:Wq ≈ (SCVa + SCVs) / 2 × ρ/(1-ρ) × 1/μ。1
这条式子比「加机器」更令人不舒服。它说,如果到达是成批的,服务时间又忽长忽短,等待会被双重放大。云服务里,突发流量、定时任务整点齐跑、缓存同时失效、重试同时回来,都会把到达间隔的方差推高。一个 60% 利用率但高度突发的系统,可能比一个 75% 利用率但平稳的系统更难用。
Amazon 的 Builders' Library 在讲重试与抖动(jitter)时给过一个具体运营经验:客户常把请求放在固定间隔上,例如每分钟一次;当一批服务器用同样节奏发请求时,请求会挤在一分钟开头或午夜之后的几秒。Amazon 通过观察每秒负载,并让周期任务加入抖动,把同样的工作摊开,用更少容量完成。5
尾部延迟会在规模下变成主体
Tail latency(尾部延迟)指延迟分布最慢的一小段,例如 p99 或 p99.9。一个单节点 p99 很差的服务已经麻烦;一个大规模扇出服务会把这种麻烦放大。Dean 和 Barroso 在 CACM 文章《The Tail at Scale》里给过一个简单例子:如果单台服务器通常 10ms 返回,但 1% 请求要 1 秒;只访问一台服务器时,100 个请求里大约 1 个慢。若一个用户请求必须并行等待 100 台这样的服务器返回,约 63% 的用户请求会超过 1 秒。6
他们还列了一个 Google 真实服务的测量:从根节点看,单个随机叶请求完成的 p99 是 10ms;等待所有叶请求完成的 p99 是 140ms;只等 95% 的叶请求完成,p99 是 70ms。最后 5% 慢请求贡献了总 p99 延迟的一半。6
这解释了为什么「平均响应 50ms」对大型系统几乎没安慰作用。用户点一次按钮,背后可能触发几十到几千个子请求;只要界面必须等最慢的几个子请求,慢尾巴就会变成用户看到的主体。工程师处理这种问题时,靠的也不是单一魔法。Dean 和 Barroso 讨论了短队列、服务分级、减少队头阻塞、对慢副本发 hedged request(延迟备份请求)并在第一个结果回来后取消其余请求等技巧;其中一个 BigTable 读 1,000 个 key 的基准里,10ms 后发 hedged request,把 p99.9 从 1,800ms 降到 74ms,额外请求量约 2%。6
这不是免费午餐。备份请求会制造额外工作,取消传播也可能失败。它的适用前提是慢的原因相对不相关:某台机器被后台任务拖慢,另一个副本未必也慢。若慢来自共同依赖,例如数据库锁、全局网络拥塞、热门分区,备份请求会把火浇到同一个地方。
超时把慢问题变成可用性问题
过载最坏的地方不是慢,而是慢会开始自我复制。Amazon 的负载 shedding 文章把 throughput 和 goodput 分开:throughput 是送进服务器的总请求数,goodput 是无错误且足够快、客户端还能使用结果的那部分请求。服务器过载时,总吞吐可以继续升,goodput 却会平台化甚至下降。7
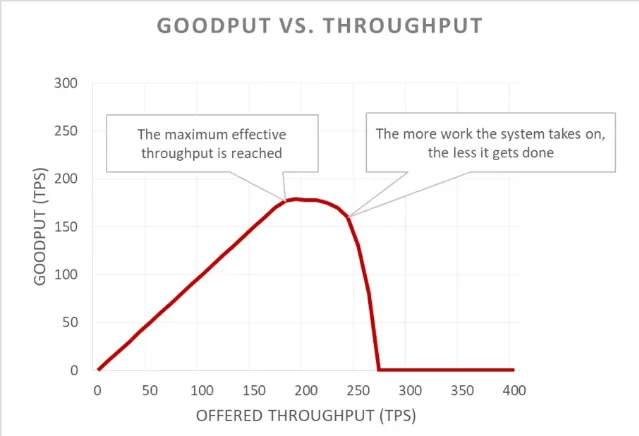
超时会把这个问题推向更坏的一侧。客户端等不到响应,就发起重试;服务器可能仍在处理第一份请求,处理完时客户端已经不听了。Amazon 的文章说,过载中浪费工作会制造正反馈:一个耗资源请求变成多个耗资源请求,负载被重试放大。7
Google SRE 书给过一个小模型:后端每个任务 10,000 QPS 后开始拒绝请求;前端以 10,100 QPS 打过去,多出来的 100 QPS 被拒并在 1 秒后重试,于是下一秒后端收到 10,200 QPS,失败量变成 200 QPS,随后重试量继续增长。3
多层系统会把这个数乘起来。Amazon 的重试文章说,一个 5 层服务调用栈,每层做 3 次重试,底层数据库在过载下可能看到 243 倍负载。5 Google SRE 书用另一个口径说明同一现象:后端、前端和浏览器三层都做 3 次重试,即 4 次尝试,单个用户动作可在数据库上制造 64 次尝试。4
一旦故障进入这个状态,恢复点不再等于触发点。Google SRE 书举例说,一个服务健康时能处理 10,000 QPS,在 11,000 QPS 崩溃;此后把流量降到 9,000 QPS 也未必恢复,因为可用服务器只剩一小部分。若只有 10% 服务器健康,请求率可能要降到约 1,000 QPS 才能稳定。3 这就是滞后:系统从山坡上滚下来以后,不会在同一高度自动停住。
正确做法常常像浪费
过载控制最反直觉的地方,是它有时要求你拒绝工作、丢弃工作、延后工作。表面上看,这些动作都降低成功率;在排队系统里,它们可能保住 goodput。
| 做法 | 解决的排队病 | 代价 |
|---|---|---|
| 短队列或无队列 | 防止请求在队列里等到超过客户端 deadline;Google SRE 书说,若队列大小是线程数 10 倍、线程处理一次请求需 100ms,满队列请求会花 1.1 秒,其中大部分时间在排队。3 | 更早暴露错误,不能用「排着」掩盖容量不足。 |
| Load shedding(过载丢弃) | 让服务器把容量用于可按时完成的请求;Amazon 说理想过载测试结果是 goodput 接近满载后平台化,而不是掉到 0。7 | 部分请求被明确拒绝,需要业务能接受分级服务。 |
| deadline 传播与取消 | 下游知道请求是否还来得及;Google SRE 书说,若请求在队列里等了 11 秒而客户端 deadline 是 10 秒,继续处理通常是在做无效工作。3 | 调用链必须传递剩余时间,代码路径更复杂。 |
| 重试预算、退避和抖动 | 限制重试放大;Google 使用 per-request retry budget 和 per-client retry budget,把一般情况下的重试增长从接近 3X 压到 1.1X。4 | 单个请求的「不放弃」被限制,局部成功率可能下降。 |
| 有界工作与分页 | 让单次请求的 CPU、内存、网络成本可估计;Amazon 说无上界列表很难做准入控制。7 | API 设计更啰嗦,调用方要处理分页和部分结果。 |
这些做法的共同点是把「等待」从默认动作改成受控动作。队列不是消失了,而是被移到能看见、能衡量、能拒绝的位置。排队本身并不坏;坏的是系统把队列藏在连接池、线程池、TCP buffer、负载均衡 surge queue、下游 RPC、浏览器重试里,然后用一个平均延迟掩盖它们。
Amazon 的负载 shedding 文章有一句很工程化的经验:查系统时,不妨假设某处有自己还不知道的队列。7 这句话比许多架构口号更有用。真正的瓶颈常不在仪表盘正中央,而在某个看起来无害的缓冲区里。
不是所有高利用率都该被惩罚
排队论不是反效率学。大系统有规模经济。多服务器队列可以用 square-root staffing(平方根人员配置):需要的服务器数近似为 ρ + z√ρ;流量越大,相对冗余比例越低。课件也说,大系统的等待时间可随 1/√ρ 下降。1 批处理、离线训练、低优先级爬虫、可等待的清算任务,都可以用更高利用率换成本。
边界在于用户是否等着,结果是否会过期,重试是否会放大,失败是否会传染。交互式服务、同步 API、急诊、呼叫中心、实时推理集群,都不适合把「平均忙碌」当成唯一美德。尾部延迟、方差、deadline、goodput,才是这些系统里更诚实的词。
这也解释了为什么一些现代计算形态会把隔离当卖点。Amazon 在负载 shedding 文章末尾说,Lambda 让每个 API 调用在独立执行环境里运行,同一个执行环境一次只处理一个请求;这不能消除依赖变慢造成的并发上升,却避开了一部分主机内资源争用。7 资源隔离不是排队论的反例。它是在改变队列出现的位置和相互污染的程度。
慢系统的第一性问题
一套系统开始变慢时,最该问的不是「还能不能多扛一点」。更好的问题是:
- 队列在哪里?线程池前、连接池里、负载均衡器里、操作系统 buffer 里,还是用户浏览器里?
- 到达过程有多突发?有没有整点任务、批量刷新、缓存同时失效、失败后同步重试?
- 服务时间的方差有多大?慢请求是否会挡住短请求?
- 客户端 deadline 到期后,下游是否还在做无效工作?
- 重试是否有预算、退避和抖动?失败是否会在多层调用栈里相乘?
- 指标看的是 throughput,还是 goodput?失败的快速返回是否把延迟指标洗得很好看?
这些问题不漂亮,也不适合贴在发布会上。它们像维修手册里的油污页。排队论的价值正在这里:它不许人把 95% 利用率说成「效率高」就结束。它会追问剩下 5% 余量要承担多少随机性、多少重试、多少尾部请求、多少用户耐心。
把系统用满很容易显得专业。留出空地更难解释,因为空地在正常日子里看起来无事发生。等到流量、方差和重试一起涌进来,那块空地就是系统还没开始撒谎的原因。
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.