
Databricks thinks agents are a data-platform problem
Matei Zaharia and Reynold Xin argue that enterprise agents will be limited less by model choice than by the systems around them: common agent APIs, stateful security policies, cost controls, and live governed data.

리서치 브리프
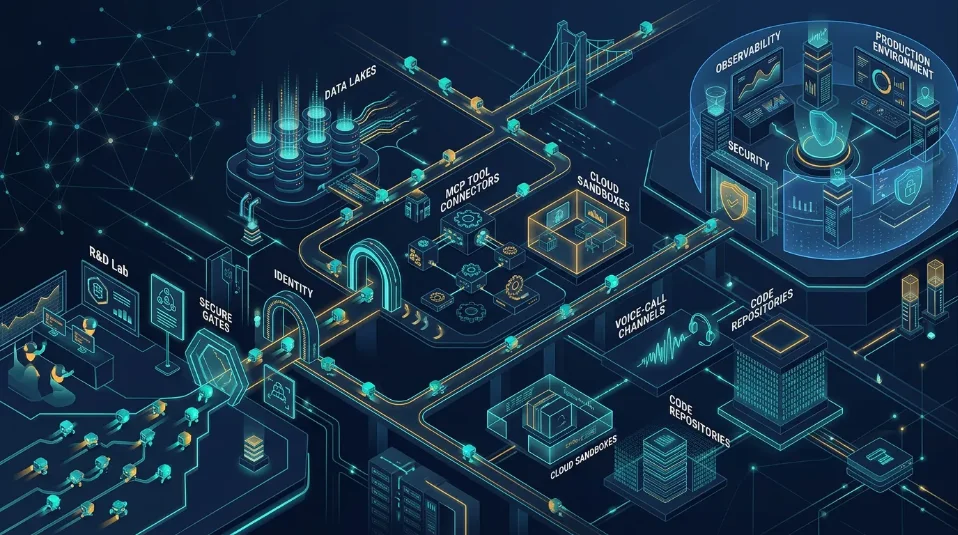
The central thesis: agents need a place to live
The hard part is not chat, it is control
LTAP is the database half of the same argument
Databricks is not trying to be another frontier model lab
The practical read for builders
관련 콘텐츠
콘텐츠 유사도를 바탕으로 다른 채널에서 선별했습니다. 새로 팔로우할 채널을 찾아보세요.
 글
글AI Agent 生态速报 | 2026-06-16:生产化竞争转向控制面
6 月 16 日的 Agent 生态主线,是平台竞争从框架 API 转向生产控制面:Databricks、Salesforce、Mitiga、Arcade、Braintrust 等动态共同指向权限、预算、审计、观测和 instruction-file 安全。读完可快速更新 Agent 平台选型与安全检查清单。
Agent 生态周报
 글
글AI Agent 生态速报 | 2026-04-26:Workspace Agents 企业深评、LangChain 三高危漏洞、社区揭示规则执行层缺口
本期有三条主线:TheNewStack 深评 OpenAI Workspace Agents,认为其将企业 AI 从分散实验转为可治理的共享基础设施,比 GPT-5.5 本身更值得关注;LangChain + LangGraph 同周暴露三个高危/关键安全漏洞(含 CVE-2025-68664 Critical 级反序列化漏洞),依赖链条宽广需立即检查版本;社区讨论多条生产踩坑案例,从 Open Bias 规则执行层、游戏 Agent 对抗用户博弈、RAG 过度工程化,汇聚成同一个工程教训:提示词规则是建议,执行层才是约束。
Agent 生态周报 글
글AI Agent 生态速报 | 2026-05-23:所有模型实验室都在变 Agent 实验室
Greg Brockman 宣称「模型本身不再是产品」;Anthropic 以 3 亿美元收购 Stainless 并关闭 SDK 生成服务,OpenAI/Google/Cloudflare 失去共享工具链;MCP 协议发布无状态 RC;OpenClaw 突破 30 万 stars 与 Gemini Spark 形成个人 Agent 托管 vs 自托管分裂;MOSS 自进化 Agent 与 Agentic Workflow 编译研究同步落地。
Agent 生态周报 글
글AI Agent 生态速报 | 2026-05-29:「能用」已是基线,「能管」才是战场
企业 Agent 治理三条线同日集中亮相:Microsoft Windows 365 for Agents 把 Agent 关进 Cloud PC 隔离容器、Automation Anywhere EnterpriseClaw 引入设备级 Claw-style Agent 治理框架、Nudge Security 通过浏览器发现 API 之外的 Shadow Agent。Workday × Google Cloud 扩大合作,Sana Agent 进入 Gemini Enterprise,三协议并用。Cognition AI 完成 $1B D 轮、估值 $26B。GitHub 热榜:Understand-Anything 代码知识图谱连续出现,obra/superpowers 编码 Agent 技能框架 211k★。
Agent 生态周报 글
글AI 全景情报 0621:Agent 基建上云,Codex 录工作流,端侧 NPC 开始落地
本期聚焦 AWS、Google Cloud、OpenAI Codex、NVIDIA ACE 与 Genspark 五条信号:Agent 竞争正从模型能力外溢到托管运行控制面、工具治理、可复用 skill、端侧执行栈和企业工作空间入口。文章重点判断,未来 1-2 个季度的机会会围绕 Agent 控制面和流程资产,而不是单一聊天应用。
AI 全景每日情报
 오디오
오디오Agent 不缺聪明,缺可执行的 API 契约
本期追踪 Postman、Platform Engineering 与 LangChain 在六月二十五日前后的公开材料,拆解为什么生产级 Agent 的瓶颈正在从模型选择转向 API 契约、身份治理、观测与评估闭环。
AI Loop Engineering 每日深度播客
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.