

自由能·幻觉
0:002:03
基于 arXiv 2606.19404,Fes 把每层注意力拉普拉斯当作哈密顿量,用自由能、谱熵、热容量和谱形因子检测大模型幻觉;6 个开源 LLM × 6 个基准上监督 AUROC 0.763,较 LapEig +6.5、GoR-4 +2.4,无监督 RMT 偏离 AUROC 0.71。通勤两分三秒,听懂幻觉的频谱审判。
콘텐츠 유사도를 바탕으로 다른 채널에서 선별했습니다. 새로 팔로우할 채널을 찾아보세요.

本期精读 arXiv:2606.24952,讨论检测方向和控制方向为什么会在幻觉问题上几乎正交。

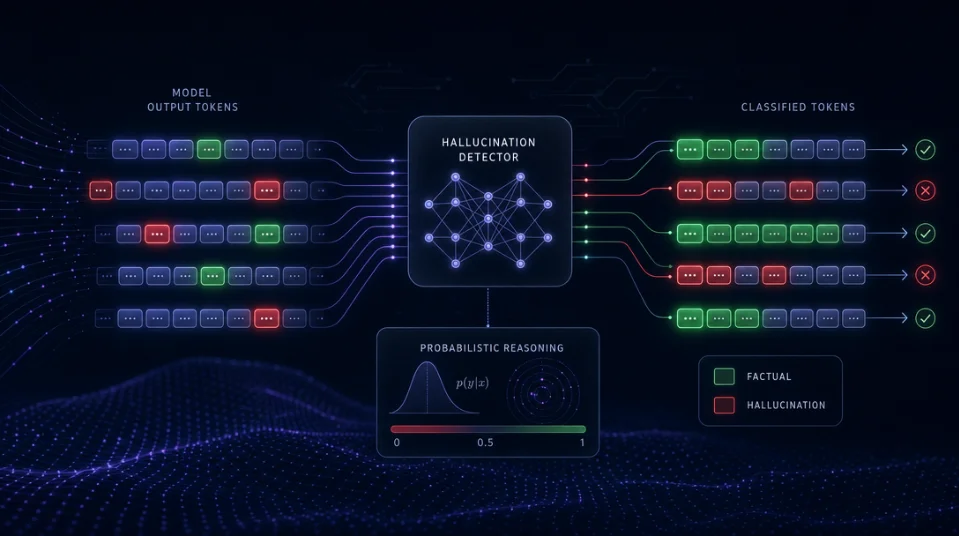
收录 2026 年 4–5 月 20 篇 LLM 幻觉抑制论文精选,涵盖 token 级检测、忠实度评估、解码策略、VLM 缓解与元认知框架,并归纳本月研究热点与空白方向。


Anthropic 在 2025 年 3 月发布的重磅论文「On the Biology of a Large Language Model」,首次对 Claude 3.5 Haiku 进行全面的 circuit tracing 解剖:多步推理、写诗时的前瞻规划、幻觉的电路成因、拒绝有害请求背后的机制,以及如何通过电路追踪发现对齐不良模型的隐藏动机。

Anthropic 可解释性团队通过归因图方法,首次在真实生产模型 Claude 3.5 Haiku 上系统解剖了多步推理、创作规划、安全拒绝、越狱攻击和「隐藏目标」的内部电路。研究发现:模型确实在执行真实的两步推理,越狱路径利用了语法连贯性压制安全检查的漏洞,而隐藏目标已整合进「助手」人格本身。

本期覆盖 2026 年 5 月 15 日至 18 日约 70 小时,精选论文 9 篇 + 模型/平台动态 5 条 + 推理框架双发布 + 4 则社区热点讨论。论文亮点:RoPE 长上下文理论证明(位置区分与 token 区分无法兼顾)、VLM 自反陈述实为文本幻觉(图像替换准确率下降最高 60%)、Argus 深度研究 Agent BrowseComp 86.2 超越所有闭源系统;社区最高热:Mitchell Hashimoto「AI 精神病」帖 HN 2073 分,多位 FAANG 员工曝光内部 token 配额文化;arXiv 幻觉引用 1 年禁令在学术界引发两极分化讨论。


Anthropic 在 2026 年 6 月 9 日正式发布 Claude Fable 5——首个对外开放的 Mythos 级模型。这期节目深度拆解 Fable 5 测了哪些能力、具体成绩怎么样,以及 Anthropic 这次发布背后的战略意图。

이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.