
2026/7/2 · 14:23
gget virus:生物 Agent 的短板不只在模型
解读 Anthropic Science 与 arXiv 论文:VirBench 如何证明科学 Agent 在病毒序列检索中会被数据库接口拖住,以及 gget virus 这类确定性检索层为什么能把准确率推到 90% 以上。

如果只看模型分数,这篇论文很容易被误读成「更强的模型终于会做生物信息学了」。Anthropic 这篇官方 Science 博客和配套 arXiv 论文的结论更冷静:在病毒序列检索这种任务里,Agent 的瓶颈不只是推理能力,而是它拿不到一个稳定、可复现、可检查的查询接口。作者把这个问题用 120 个真实检索任务压了一遍,结果很直观:模型自己闯 NCBI Virus,答案经常错;接上确定性的 gget virus 后,多数系统的准确率直接越过 90%。12
它要解决的不是「会不会生物学」,而是「能不能拿对数据」
论文题目是 Deterministic access to global viral sequence data enables robust agentic scientific discovery,6 月 4 日提交到 arXiv;Anthropic 随后在 6 月 8 日发布了 Laura Luebbert 的解读文章。研究团队来自 Hasso Plattner Institute、Broad Institute、MIT、NCBI、Anthropic、FutureHouse 等机构。2
这里的任务很具体:让科学 Agent 从 NCBI Virus 这类公共病毒基因组资源中,按照物种、宿主、地区、采样日期、序列长度、完整性、片段名等条件,取回正确的序列集合。听起来像数据库检索,但生物数据库不是一个干净的 SQL 表。很多过滤逻辑只在网页界面里好用,API 暴露不完整;同一个地点可能在 location、region、virus name 这些字段里出现;大数据集还涉及分页、中断、批量下载和本地过滤。
这就是论文里说的「deterministic access」:给定同一个查询和同一个数据库状态,返回的 accession 集合应该完整、可复现,不因为分页、批处理或接口选择而变化。对普通聊天任务来说,差几个结果也许只是小错;对病毒监测、疫苗靶点、系统发育树来说,第一步数据集错了,后面的树、变异判断和治疗靶点分析都会跟着偏。
VirBench 把 Agent 放进 120 个检索坑里
研究团队构造了 VirBench:120 个专家人工核验过的病毒序列检索任务,覆盖 40 种病原体,查询条件最多同时包含 9 个过滤器,中位数为 6 个,预期返回数量从 0 到 3226 条不等。除 3 个 accession 查询外,任务还设置了最晚 release date,避免数据库后续更新把答案冲掉。3
他们测试了六类 Agent 或模型系统:Claude Sonnet 4、Claude Opus 4.7、Biomni OSS、Edison Analysis、GPT-5.2-pro、GPT-5.5。每个查询重复三次,评估 exact-match accuracy、重复运行稳定性、误差幅度、运行时间和工具调用次数。3
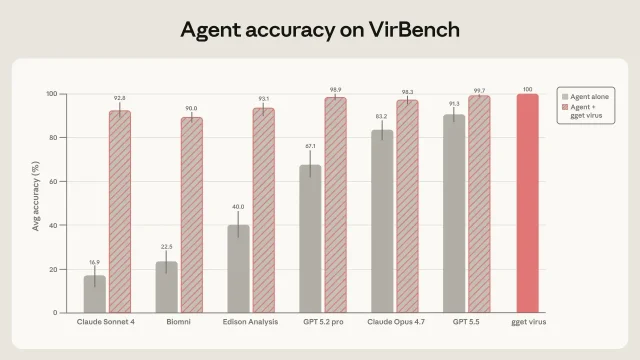
没有专用检索层时,差距非常大:Claude Sonnet 4 平均准确率为 16.9%,Biomni 为 22.5%,Edison Analysis 为 40.0%,GPT-5.2-pro 为 67.1%,Claude Opus 4.7 为 83.2%,GPT-5.5 为 91.3%。这些数字不只是「旧模型差、新模型好」。论文指出,即使较强模型仍会出现后果很重的残余错误,因为病毒序列检索通常是更长科研流程的第一步。3
gget virus 做的事很朴素:把「点网页」变成可复现函数
gget virus 不是一个更聪明的模型,而是一个确定性的查询层。它把 NCBI Virus 网页里隐含的过滤语义拆出来,协调 Datasets REST API、Datasets CLI、E-utilities 和 GenBank 记录,再按条件先过滤轻量 metadata,只在必要时下载完整序列或 GenBank XML。3
这类设计的价值在三个地方:
- 先缩小再下载:例如论文给出的 SARS-CoV-2 2025 年 surface glycoprotein 查询,传统「先下载再过滤」需要 284 GB 数据;gget virus 只取 3.8 GB,数据量减少超过 98%。2
- 把网页语义补成程序语义:它支持网页上常见但 API 不完整暴露的条件,比如 maximum collection date、submitter country、protein/gene specification、lab passaged、maximum ambiguous characters、segment、vaccine strain 等。3
- 留下可检查痕迹:每次查询会输出参数、版本、运行时间、传输量、过滤统计、生成文件和重试 URL。科学工作流最怕「看起来对,但不知道怎么来的」;这个日志层把可复现性补上了。3
接上这个工具后,六类 Agent 的准确率变成:Claude Sonnet 4 为 92.8%,Biomni 为 90.0%,Edison Analysis 为 93.1%,GPT-5.2-pro 为 98.9%,Claude Opus 4.7 为 98.3%,GPT-5.5 为 99.7%。重复运行稳定性也提高到 0.92-1.00。论文还说,剩下的错误多半不是检索层本身错,而是 Agent 在调用或后处理工具输出时又做了多余解释。3
为什么这篇对大模型团队有参考价值
大模型团队常把 Agent 能力讲成「更会规划、更会调用工具、更会多步推理」。这篇文章提醒另一件更基础的事:很多科学 Agent 出错,并不是因为模型不会想,而是环境没有给它一条稳定的路。
生物数据基础设施尤其典型。数据库背后有历史包袱、字段不一致、网页专属过滤器、批量下载限制和大量人类默认知道的约定。Agent 可以读文档、写脚本、尝试 API,但它每次都在临时重建一条路。路重建得像不像,取决于模型、提示词、当时搜索到的文档和 API 是否抽风。对需要 exact-match 的任务,这种不确定性很难接受。
这也解释了为什么 gget virus 让模型差异变小。它把容易出错的部分从「模型自由发挥」收束成「工具负责兑现语义」。模型仍然有用:它理解研究者想要什么,选择何时调用工具,解释结果,组织后续分析。但它不再负责猜 NCBI Virus 的分页、字段映射和过滤细节。
局限在哪里
这项结果不能外推成「科学 Agent 已经可靠」。第一,VirBench 是病毒序列检索,不代表所有生物学任务。第二,gget virus 依赖外部数据库和网络;底层标注错了、字段缺了,它不能自动纠正。第三,作者没有公开完整 VirBench 数据集,理由是防止进入模型训练语料后污染评测,这会让外部复现实验需要向作者申请访问。3
还有一个更细的限制:Agent 接上好工具后,仍可能错误地二次过滤、忽略工具、传错参数,或把结果重新解释坏。也就是说,AI-ready 工具不只是 API 可调用,还要有适合模型阅读的文档、清晰的输出格式、失败提示和最小二义性。
这篇文章真正该被带走的结论
如果你在做科研 Agent、企业数据 Agent 或任何严肃工作流,别只盯着模型参数和推理链。先问一个更笨的问题:任务里哪些步骤必须返回 exact answer?这些步骤有没有确定性接口?输出能不能被日志、版本和参数重放?
Anthropic 这篇材料的价值就在这里。它没有证明「Claude 已经会做生物学家」,反而证明了相反的一点:要让 Agent 进入高风险科研流程,必须先把数据入口、工具语义和验证链条做硬。模型可以负责判断和组合,底层事实获取最好别靠它现场摸索。
関連コンテンツ
- ログインするとコメントできます。