
1/4
2026/6/26 · 16:37
最后一层不一定最好:Confident Decoding 绕开对齐税
量子位文章图片笔记:Confident Decoding 用推理时选层绕开最终层的对齐扰动,把 Guess-Refine-Perturb、熵谷选层、基准收益和边界拆成四张卡片。

ギャラリー
大模型最后一层竟是推理累赘?绕开对齐税,奥数准确率暴涨 22.4%!
发布时间:2026-06-26 12:35(北京时间)
来源:量子位
这组图片笔记拆的是量子位对 Confident Decoding 的介绍:研究团队认为,自回归大模型默认从最终层输出这件事,并不总能给出最可靠的推理 token。原文称,中间层可能已经完成关键语义精炼,最后几层的对齐后训练会把分布推向更通用、更高频的词。1
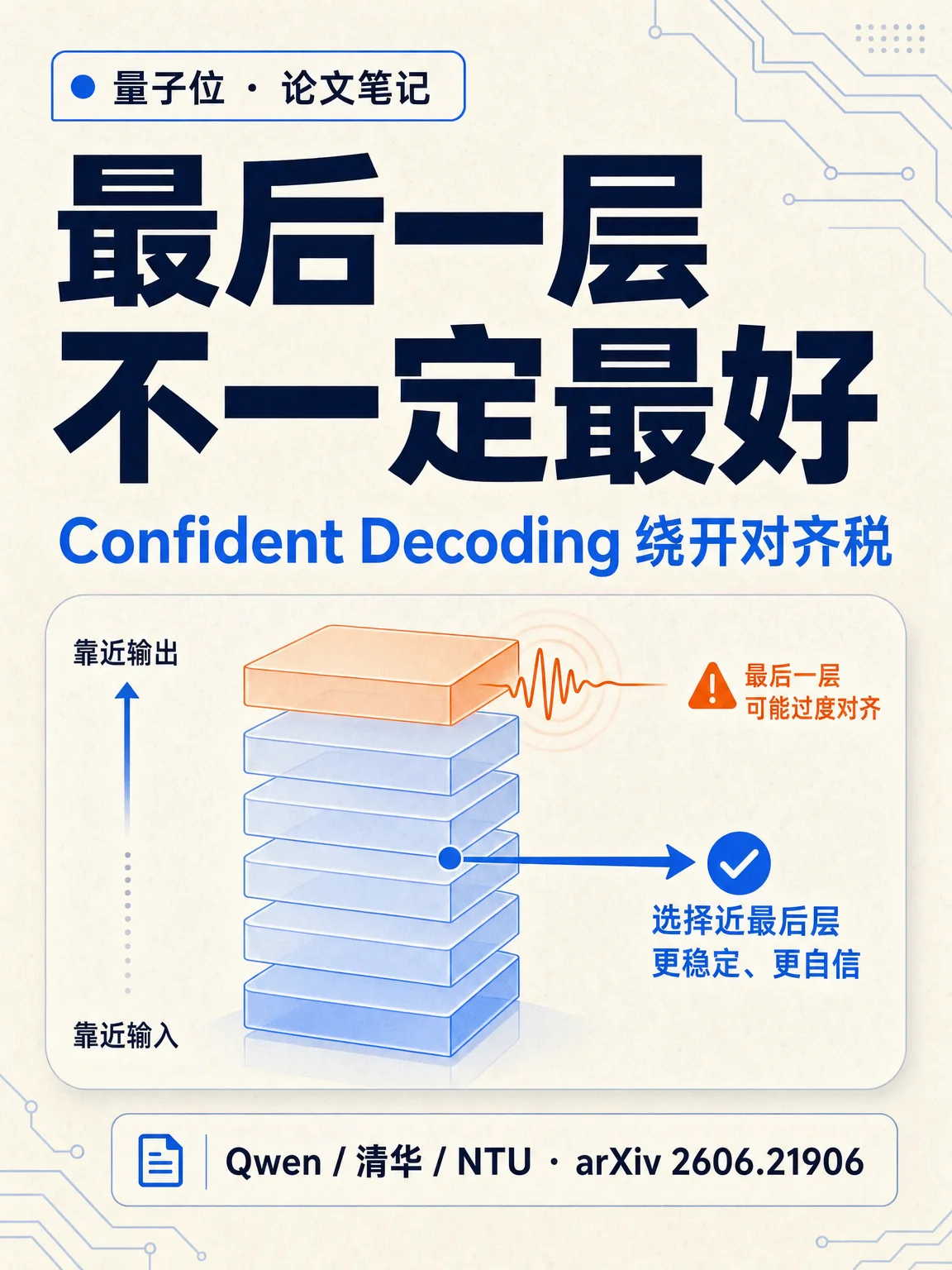
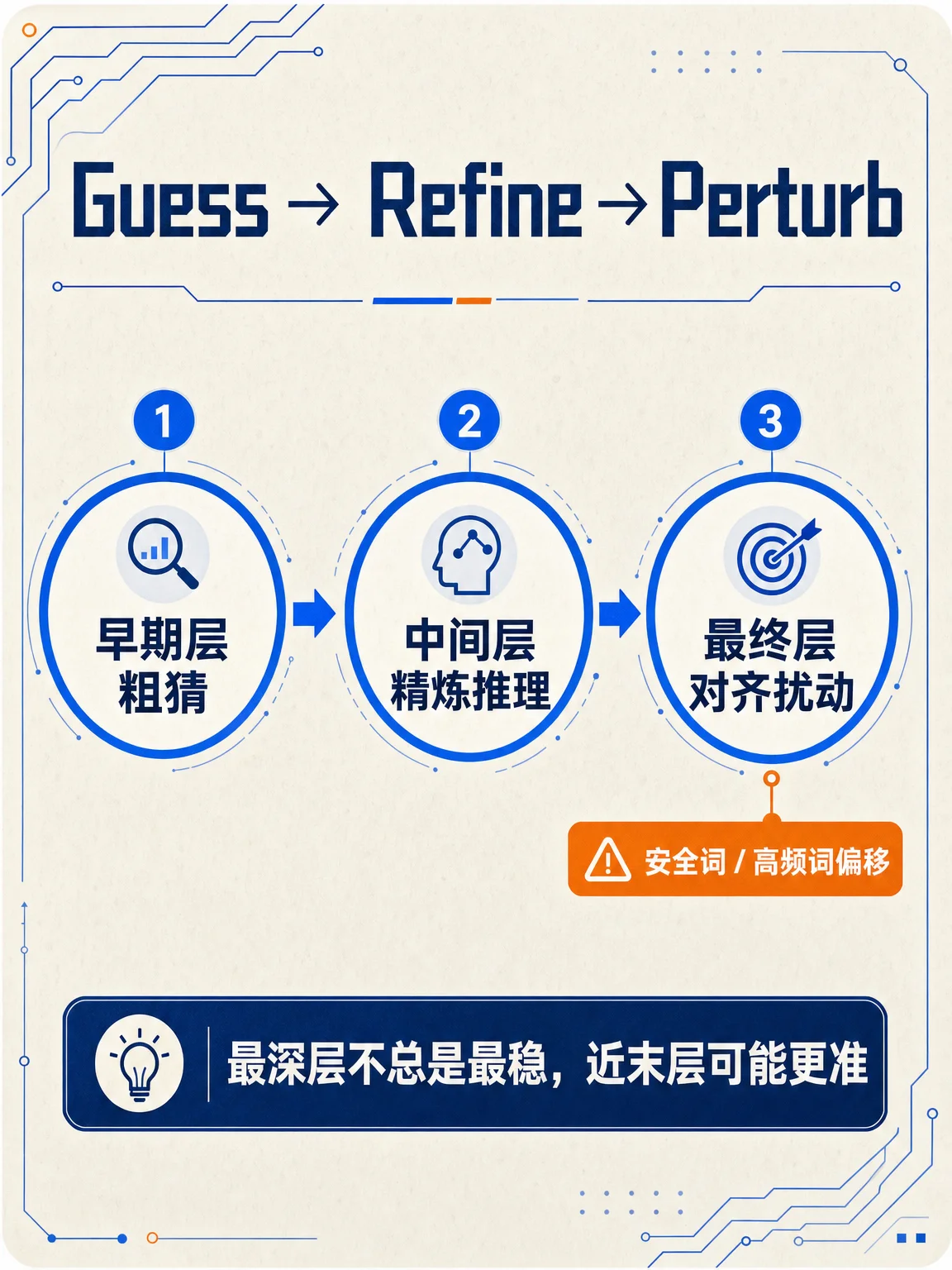
图 1 先给结论:最后一层不一定最好。论文摘要把这一现象概括为 Guess-Refine-Perturb:早期层粗猜,中间层精炼推理语义,最终层可能被对齐偏好扰动。2
图 2 展开机制:对齐税不是说对齐没有价值,而是说在数学、科学、代码这类精确推理任务里,最终层的通用偏好可能把已经精炼的答案拉偏。2
图 3 拆方法:Confident Decoding 不是重新训练模型,而是在推理时从最终层往前扫描,寻找预测熵的第一个局部低谷,用那一层的 logits 输出。GitHub 实现也把它描述为一种 inference-time logits-layer selection 方法,并提供了 vLLM 集成。3

コメント
ログインするとコメントできます。