
2026/7/1 · 6:36
Claude Sonnet 5:Anthropic 把 Agent 主力模型推到 Opus 边上
Anthropic 发布 Claude Sonnet 5,把更强的 Agent 执行能力下放到默认 Sonnet 档位。本文拆解它的 benchmark、effort 控制、价格与安全边界,并对照 GPT-5.6 Sol 看模型竞争如何转向执行预算。

Anthropic 6 月 30 日发布 Claude Sonnet 5,并把它设为 Free 与 Pro 计划的默认模型,同时开放给 Max、Team、Enterprise、Claude Code 和 Claude Platform。API 首发价到 8 月 31 日前是每百万输入 token 2 美元、每百万输出 token 10 美元,随后回到 3 美元和 15 美元。1
这次发布的重点不是「又多一个旗舰」。Sonnet 本来就是 Anthropic 的主力工作马,承担聊天、代码、企业自动化和大部分 API 场景。Sonnet 5 要回答的问题更具体:不把用户推到更贵的 Opus,也能不能跑完长程 Agent 任务。
Sonnet 5 的位置:不是追最高分,而是追「够强且便宜」
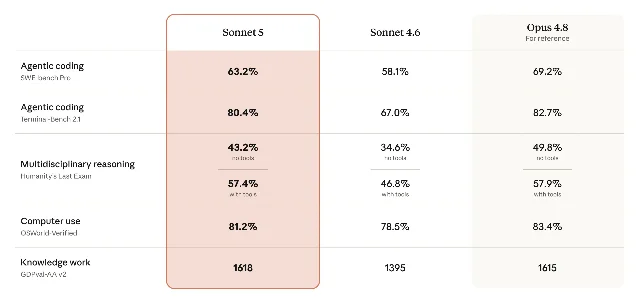
Anthropic 给 Sonnet 5 的定位很清楚:它是「最 agentic 的 Sonnet」,性能接近 Opus 4.8,但价格更低。官方 benchmark 里,Sonnet 5 在 Terminal-Bench 2.1 上是 80.4%,明显高于 Sonnet 4.6 的 67.0%,离 Opus 4.8 的 82.7% 很近;在 OSWorld-Verified 上是 81.2%,也接近 Opus 4.8 的 83.4%。1
这组数据最值得看的不是单项第一。SWE-bench Pro 里,Sonnet 5 是 63.2%,仍低于 Opus 4.8 的 69.2%;Humanity's Last Exam 无工具得分 43.2%,也落后 Opus 4.8 的 49.8%。Anthropic 这次想证明的是另一件事:Sonnet 档位已经能覆盖很多过去需要 Opus 档位才稳的 Agent 工作。1
这对开发者的含义很直接。真正贵的 Agent 应用,成本不只来自模型单价,还来自反复计划、调用工具、读写文件、回查结果和自我纠错。Sonnet 5 如果能用更低单价接近 Opus 的长程执行能力,就会把「默认用高端模型」改成「先用 Sonnet 跑,必要时再升 Opus」。
价格表之外,effort 才是这代 Sonnet 的关键旋钮
Claude Sonnet 5 的 API ID 是
claude-sonnet-5,上下文窗口为 100 万 token,最大同步输出为 12.8 万 token,可靠知识截止时间标为 2026 年 1 月。模型总览页同时说明,Sonnet 5 在 AWS Bedrock 与 Google Cloud 中也使用对应的 Sonnet 5 ID。2更重要的是
effort 参数。Anthropic 文档说,effort 不是只控制「思考 token」,而是会影响所有输出 token,包括文本、工具调用和函数参数。换句话说,低 effort 可能让 Claude 少调用几次工具,高 effort 则让它更愿意花 token 检查和推进任务。3Sonnet 5 默认是 high effort;xhigh 面向超过 30 分钟的长程 Agent 和编码任务;medium 是成本折中档,文档把它描述为接近 Sonnet 4.6 high effort 的能力;low 则适合高并发、低延迟或非编码聊天场景。3
这会改变调用策略。过去开发者常用「换模型」来调成本:复杂任务上 Opus,普通任务上 Sonnet。Sonnet 5 之后,更可行的做法是先固定模型,再按任务阶段调 effort。例如规划阶段 high,批量子任务 low 或 medium,最后审查再 high。这个颗粒度比单纯换模型更细,也更适合 Agent 编排。
不过成本账不能只看单价。Anthropic 在脚注里提醒,Sonnet 5 使用了更新的 tokenizer,同样输入映射出的 token 数可能变成原来的 1.0 到 1.35 倍,具体取决于内容类型;首发价被设置为大致抵消这部分迁移成本。1 对企业客户来说,8 月 31 日以后回到标准价时,真实账单要重新测一遍。
安全叙事:Anthropic 选择压低 Sonnet 的网络攻击能力
Sonnet 5 的安全表述和上周 OpenAI GPT-5.6 Sol 很不同。OpenAI 在 GPT-5.6 Sol 预览中强调更强的网络安全能力、
max reasoning、ultra subagents,以及政府知情下的小范围 trusted partners 预览。4 Anthropic 这次则强调:Sonnet 5 在 Agent 场景更安全,恶意请求拒绝、prompt injection 抵抗、幻觉和 sycophancy 都比 Sonnet 4.6 更好。1网络安全能力上,Anthropic 的口径更克制。它说没有刻意训练 Sonnet 5 做网络攻击任务;在 Firefox 漏洞利用评估中,Sonnet 5 和 Sonnet 4.6 都没有生成完整可工作的 exploit,成功率都是 0.0%,但 Sonnet 5 的部分成功率略高。Anthropic 因此默认开启实时 cyber safeguards,不过它也说明,Sonnet 5 的防护比 Fable 5 那套更宽松,因为整体网络安全风险被判断为较低。1
这里的分叉很清楚。OpenAI 把 GPT-5.6 Sol 放在「更强网络安全能力 + 更强安全栈」的叙事里,Anthropic 把 Sonnet 5 放在「日常 Agent 更能干 + 不主动推高危险 cyber 能力」的叙事里。前者像旗舰能力展示,后者更像生产系统升级。
Claude Science 说明了 Sonnet 5 要落在哪里
同一天,Anthropic 还发布了 Claude Science,一个面向科学家的 AI workbench。它不是普通聊天入口,而是把文献、Jupyter、R、集群终端、数据库和专门工具放进同一个研究环境,输出可审计的 artifact,并保留生成图表、代码、环境和消息历史。5
这个产品暴露了 Anthropic 对 Agent 的真实想象:Agent 不是在聊天窗口里「帮你想想」,而是在受控环境里读数据、跑代码、调集群、生成图表,再由 reviewer agent 检查引用和计算。Claude Science 预装超过 60 个面向基因组、单细胞、蛋白质组、结构生物学和化学信息学的技能与连接器,并可连接本地 macOS/Linux、SSH、HPC login node 或 Modal 计算资源。5
它目前以 beta 形式面向 Claude Pro、Max、Team、Enterprise 用户开放;Anthropic 还提供最多 50 个 AI for Science 项目名额,每个项目最高 3 万美元 credits,申请截止到 2026 年 7 月 15 日。5 这类产品会消耗大量工具调用和长上下文,正好需要 Sonnet 5 这种「较便宜但能跟任务」的模型层。
横向看:这一轮竞争从模型能力转向执行预算
如果只看一句发布稿,Claude Sonnet 5 是「Sonnet 升级」。放到过去一个月的节奏里看,它更像 Anthropic 对 Fable/Mythos 和 Opus 4.8 之后的补位:高端模型负责拉开能力上限,Sonnet 负责把 Agent 能力下放到默认入口。
OpenAI 的 GPT-5.6 Sol 还在有限预览,主叙事是 max reasoning、ultra subagents、编码、生物和网络安全评估;Anthropic 则把 Sonnet 5 直接推到免费和 Pro 默认模型,并给开发者 effort、1M 上下文、12.8 万输出和更低的首发价。4 2
接下来判断 Sonnet 5 值不值得迁移,不该只盯 benchmark。更需要实测四个变量:同一任务在 medium/high/xhigh effort 下的工具调用次数、完成率、端到端延迟和失败后的恢复成本。Anthropic 自己也在发布后更新过 BrowseComp 成本性能图,原因是早期图表使用的方法不符合其标准 agentic search 评测方法。1 这提醒开发者:Agent benchmark 的方法细节会明显改变结论,不能把一张曲线直接读成绝对排名。
Sonnet 5 真正要验证的是一个更工程化的问题:在不把成本推到 Opus 或旗舰层的前提下,模型能不能稳定完成一整串工具任务。如果答案是肯定的,Anthropic 这次升级影响最大的不是聊天体验,而是那些已经把 Claude 放进代码库、研究环境和企业流程里的团队。
このコンテンツについて、さらに観点や背景を補足しましょう。