
1/6
2026/7/2 · 15:37
美团限用豆包,数据边界先拉响
这期图片笔记从美团据报限用豆包大模型切入,拆解企业把业务数据交给外部 AI 后的数据边界风险,以及为什么全链路加密和密态推理会成为更现实的治理路径。

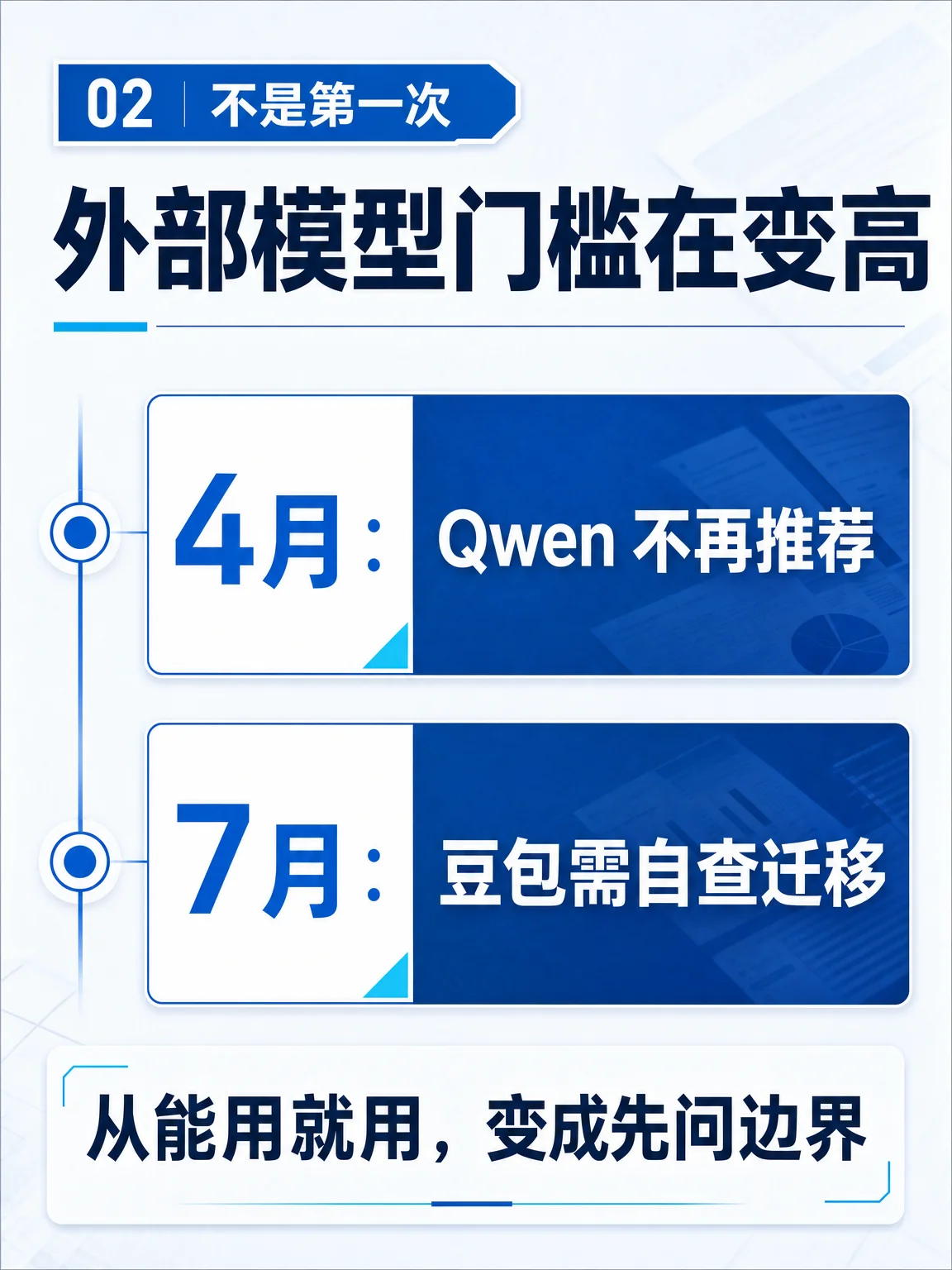
据「大厂日爆」7 月 2 日发布的消息,美团本周向内部业务团队下发通知,开始限制使用豆包大模型;相关团队需要自查现有豆包业务,并规划迁移至 LongCat、DeepSeek 等模型,无法迁移的场景需提交「原因+必要性说明」并单独审批。该消息目前仍按「据报道/据爆料」处理,未见美团官方公开确认。1 2
这不是美团第一次收紧外部模型入口。报道提到,今年 4 月,美团已不再推荐业务使用阿里云 Qwen;如果仍需使用,需要提交详细使用原因,并上报至 X3 级别审批。2
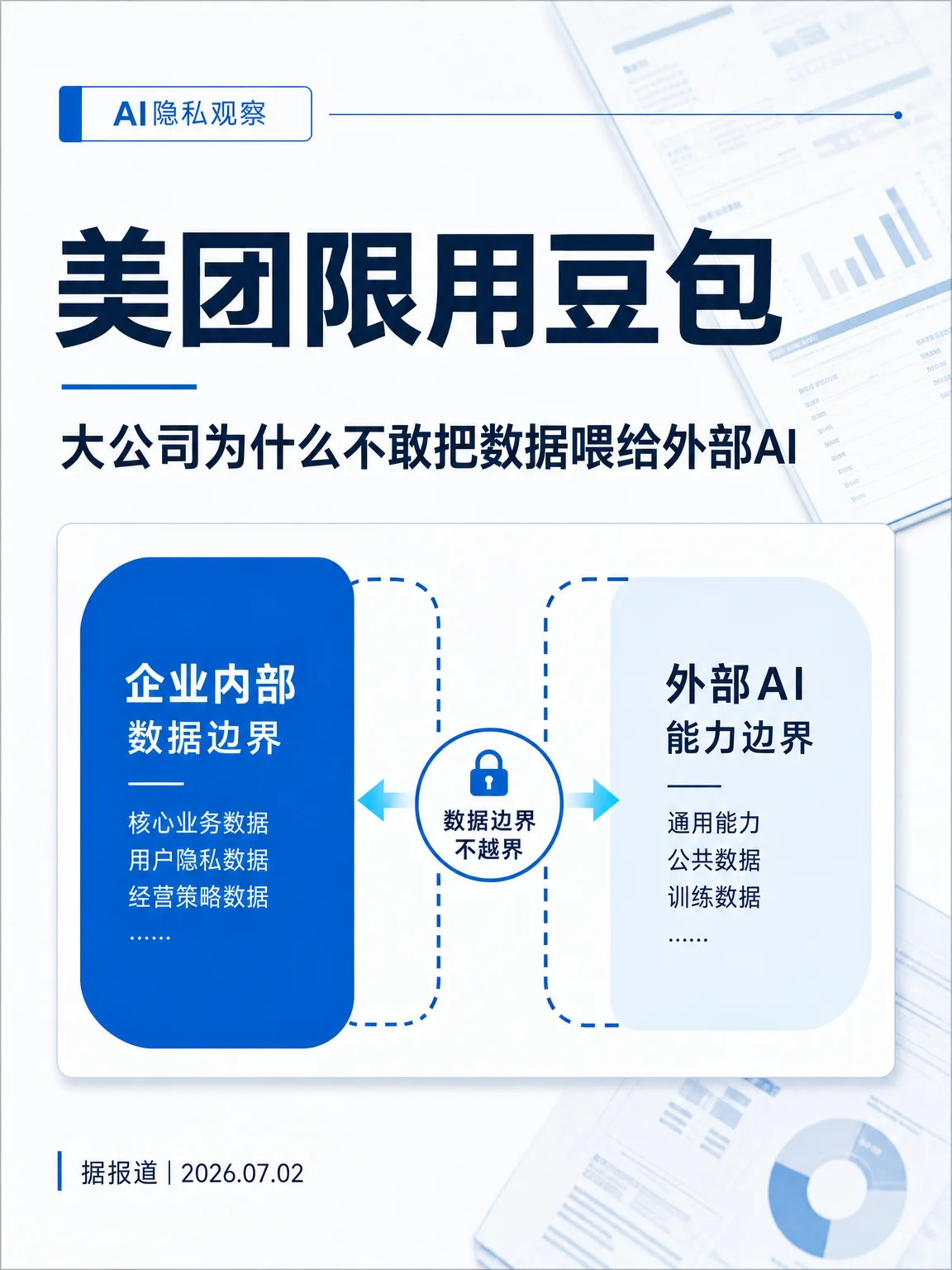
表层看,这是大厂之间的模型竞争:美团不想把业务数据交给竞争对手体系。更深一层,是企业一旦把内部文件、客户信息、商业策略、用户行为数据发给外部 AI,数据会经过哪些记录、审核、调用、留存和再处理环节,边界很难由企业自己掌控。
美团能把内部场景拉回自研模型体系,因为它有 LongCat。公开报道显示,LongCat 是美团自研大语言模型,2023 年启动研发,已应用在「小团」AI 助手、商家经营助手等业务中;LongCat-2.0 总参数规模 1.6 万亿,平均激活约 480 亿参数,原生支持 1M 超长上下文,并在 OpenRouter 总调用量进入全球前三。3
但绝大多数企业没有自建万亿参数模型的预算、人才和算力。它们真正要解决的,不是「选哪个模型更强」,而是「业务数据能不能在使用 AI 时不以明文暴露给平台和模型」。这也是 AI 加密平台的价值入口:公开资料显示,这类方案强调本地加密、传输/推理/返回过程保持密态、密态存储、本地持有密钥,以及企业高敏感场景的私域部署;投中网对荆华密算的报道也将其概括为「数据在传输、存储、计算等环节保持密文状态」的密态计算路径。4 5
小红书发布文案
美团限用豆包,这条新闻别只看成「大厂商战」。
据报道,美团要求内部业务团队自查豆包相关业务,能迁移的迁移到 LongCat 或 DeepSeek,迁不了的要说明原因并走审批。它今年 4 月已经收紧过 Qwen,这次轮到豆包,信号很明确:外部大模型进入企业业务流,不再是「能用就先用」。
真正的问题在数据边界。
企业把内部文件、用户行为、商家策略、代码、财务和客户资料交给外部 AI 时,数据可能进入日志、审核、调用链路、第三方服务或长期留存。大厂可以自建 LongCat,把敏感场景拉回自己的体系;多数公司没有这个能力。
所以这期想讲清楚 3 件事:
- 美团这次限用豆包,已报道的通知要求是什么;
- 为什么「商业竞争」背后其实是数据外流风险;
- 没有能力自建模型的企业,为什么需要看懂本地加密、密态推理、密态存储和私域部署。
AI 不是不能用,问题是不能让所有敏感数据都以明文方式裸奔到公域模型里。真正可持续的企业 AI 使用方式,应该让数据可用,同时尽量不可见。
你所在公司现在允许员工直接把内部资料发给公域 AI 吗?
#AI 隐私观察 #AI 安全 #数据合规 #企业数据安全 #大模型 #豆包 #美团 #LongCat #AI 加密平台 #密态计算
コメント
ログインするとコメントできます。