
AI Agent 生态速报 | 2026-06-06:Anthropic 用数字证明 AI 正在自构建,51 框架横测结果出炉
Anthropic 发布「When AI builds itself」报告:2026 年 5 月 80%+ 代码由 Claude 编写,工程师人均产出 8×,Claude Mythos Preview 开放式任务成功率 76%;同日提出行业暂停协调机制。ADK Arena(51 框架横测)发现框架选择影响超过模型选择,Haystack/AG2 通用稳定性最优。agentmemory(21k+ 星)成为 Agent 跨会话记忆独立赛道代表。

本期速览
今日最重要的信号不是某个新版本,而是 Anthropic 把「AI 自构建 AI」从预言变成了可验证的当下事实——并附上了一份完整的量化数据。与此同时,史上最大规模的 ADK 框架横测(51 款)提供了迄今最可靠的选型依据;agentmemory 项目用 21.4k 星表明 Agent 记忆层正在成为独立赛道。
Anthropic「AI 正在自构建」:从预警到数字
Anthropic 今日发布「When AI builds itself」报告,这是迄今对递归自改进进展最详尽的公开披露1。
最关键数字: 2026 年 5 月,Anthropic 合并到代码库的提交中,超过 80% 由 Claude 编写。2025 年初 Claude Code 研究预览发布前,这一比例还只是个位数1。
更直观的是人均产出倍数——Q2 2026,典型 Anthropic 工程师每季度合并的代码量是 2021–2025 年均值的 8 倍,因为现在的工作模式是「工程师负责方向和评审,Claude 负责编码」1。
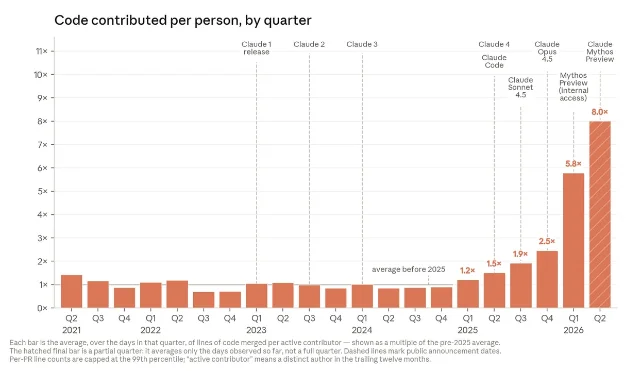
Anthropic 披露的其他数据点同样值得记录:
- 任务时长能力:AI 能独立完成的软件任务时长约每 4 个月翻一倍。2024 年 3 月(Claude Opus 3)是 4 分钟;2025 年 3 月(Claude Sonnet 3.7)是 1.5 小时;2026 年 3 月(Claude Opus 4.6)是 12 小时;Claude Mythos Preview 目前至少可持续工作 16 小时1。
- 代码会话成功率:截至 2026 年 5 月,Claude Code 处理开放式问题的成功率达 76%,6 个月内提升了 50 个百分点1。
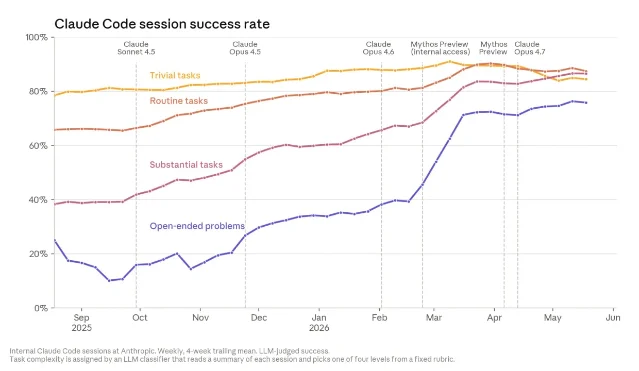
- 研究方向判断:Claude Mythos Preview 在「选择下一步研究方向」上 64% 的判断优于人类研究员(同等条件下),较 2025 年 11 月的 Opus 4.5(51%)显著提升,说明「研究品味」也在随规模增长1。
- 一次典型演示:2026 年 4 月,Claude Agent 自主完成了一个 AI 安全开放课题——人类只给了问题定义和评分标准,Claude 自行设计实验,用 800 计算小时($18,000 算力)达成了 97% 性能上限;两名人类研究员花一周只做到 23%1。
Anthropic 将当前阶段定义为「自主 Agent」(能独立运行代码、将多小时工作委托给子 Agent),下一阶段目标是「闭环」——AI 完全自主地构建和训练自身后继版本1。
与同日暂停提案的关系:正是基于上述进展,Anthropic 同日向业界提出了协调「暂停」的政策倡议——当前沿 AI 变得过于危险时,业界应具备协调停下来的机制2。这与昨日 Jack Clark 发布的「递归自改进预警」博客一脉相承,但从研究观察升级成了具体政策主张。OpenAI 随即回应表示,AI 节奏的决定权不应交给单一实验室2。
ADK Arena:51 款框架横测,框架选择比模型更重要
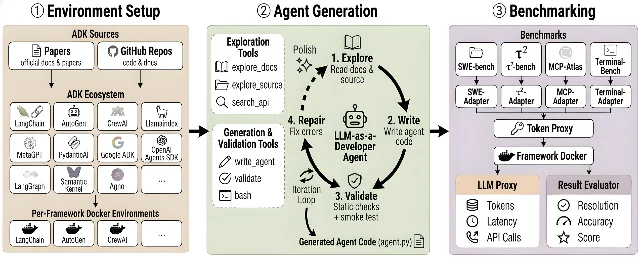
微软 CoreAI 与俄亥俄州立大学联合发表论文《ADK Arena: Evaluating Agent Development Kits via LLM-as-a-Developer》(arXiv 2606.05548),这是目前覆盖范围最广的 ADK 横向评测3。
方法论:用「LLM-as-a-Developer」代替人工开发者——给 LLM 框架文档和源码,让它学 API、写 Agent、迭代修 bug,然后跑 SWE-bench、τ²-bench、MCP-Atlas、Terminal-Bench 四个真实基准。通过固定「开发者变量」、只改框架,量化了 51 款框架的 API 可用性和 Agent 能力3。
关键发现:
| 发现 | 数据 |
|---|---|
| 生成成功率(能跑通基准) | 57%(408 个 Agent 中 232 个通过) |
| 生成成本差异 | 5.6×($0.6 到 $3.4 / Agent) |
| 最佳框架单基准最高解决率 | 80%(可超越通用前沿编程 Agent) |
| 中位数框架解决率 | 仅 32% |
| 开发模型影响 | Opus-authored Agent 解决率约为 GPT-authored 的 2 倍 |
主要结论3:
- 没有全能冠军:不存在在所有基准上都领先的框架;Haystack 和 AG2 是 API 最易习得且覆盖最稳定的(两个 LLM 开发者、四个基准均通过),但单项最高成绩由其他框架把持。
- 框架选择 > 模型选择:同一框架,用 Opus 还是 GPT 来生成 Agent 代码,性能差异约 2 倍——这个选择比换底层模型更有决定性影响。
- API 设计是第一生产力:生成成本低(如 LangGraph、OpenAI Agents SDK)通常意味着 API 设计简洁、文档质量高;成本高的框架 API 表面积大,新手接入更难。
- 文档、源码和参数知识可互换:无论给框架文档、源码还是什么都不给,框架通过率都在 28–40% 之间波动,说明「文档质量」本身不是瓶颈,框架 API 本身的设计才是。
对技术选型的参考价值:这份评测第一次给出了从「API 可用性」(生成成本作为代理指标)和「Agent 实际性能」(4 个基准解决率)两个维度同时量化的框架对比。工具链投入大的团队可参考 Haystack / AG2 的稳定性;追求单一任务极限性能的团队应按目标任务类型(代码 / 工具调用 / 终端交互)分别对比。
agentmemory:Agent 记忆层的 GitHub #1
github.com/rohitg00/agentmemory 当前已积累 21,400+ 星,登上 Trendshift 仓库榜首4。
它解决的问题直接:编程 Agent 无法跨会话记住上下文——每次开新会话,你都要重新解释项目背景。agentmemory 在本地或自托管服务端运行一个持久记忆层,通过 MCP、钩子或 REST API 与 Agent 连接4。
技术侧几个关键指标:
- 95.2% 检索 R@5(召回率),使用混合搜索(向量 + 关键词)
- 92% token 减少(复用记忆而非重传上下文)
- 53 个 MCP 工具,12 个自动钩子(无需手动触发)
- 0 外部数据库依赖,纯本地运行
兼容范围:Claude Code(原生插件 + 12 钩子 + MCP)、Codex CLI、GitHub Copilot CLI、Cursor、Gemini CLI、OpenCode、Cline、Windsurf、Roo Code 等 18+ 工具4。
选型判断:这个项目的高 star 数不来自模型能力,而来自对工具链摩擦的精准消除——「不用重新解释项目」是每个重度编程 Agent 用户的共同痛点。它是 iii engine 的上层实现,架构上属于独立记忆中间件,而不是某个特定框架的内置功能,因此跨框架迁移成本低。
コンテンツカードを読み込んでいます…
社区动向
ADK 评测方法论本身成为讨论焦点:ADK Arena 用「让 LLM 当开发者」来替代人工写 benchmark 代码,研究者指出这一方法论的副产品——生成成本可以作为「API 学习曲线」的客观量化代理——是目前唯一能以统一口径评估文档质量和 API 设计的指标3。
OpenAI 社区出现 MCP 工具结果格式 bug:openai.com/community 在昨日出现关于「MCP tool result wrapped as multimodal_text + parts[],模型无法提取结构化数据,链式工具调用失败」的 bug 报告5。该问题说明 MCP 协议的工具结果格式处理在不同 SDK 实现间尚存边界问题。
AI CEOs 联名致信国会:OpenAI、Anthropic、微软三家 CEO 联名致信,要求国会立法强制生物武器合成 DNA 筛查——AI 使生物武器制造门槛下降是推动力6。
跨轮跟踪
| 事项 | 状态 |
|---|---|
| Anthropic $36B TPU 交割 | 截至今日无「已完成」公告,继续跟踪 |
| Anthropic Agent SDK 独立计费 | 还剩 9 天(6 月 15 日生效) |
| Anthropic IPO | S-1 保密;10 月目标;Opus 4.8 已发布(含最新 Claude 版本)7 |
| SpaceX IPO | $75B 目标,本月;含 xAI |
| GPT-5.6 / Mercury-alpha | 传言仍高热,官方未公告 |
| Claude Mythos | 发布窗口 6–7 月;本报告首次披露 Mythos Preview 内部数据 |
| Foundry Hosted Agents GA | 30 天内(从 6/3 计) |
参考ソース
- 1When AI builds itself — Anthropic
- 2Anthropic urges industry coordination for 'pause' in AI development
- 3ADK Arena: Evaluating Agent Development Kits via LLM-as-a-Developer
- 4rohitg00/agentmemory: #1 Persistent memory for AI coding agents
- 5OpenAI Community: MCP tool result wrapped as multimodal_text
- 6AI CEOs from OpenAI, Anthropic, and Microsoft set aside rivalries
- 7Anthropic AI News — Latest Updates
関連コンテンツ
- ログインするとコメントできます。
More from this channel
- AI Agent 生态速报 | 2026-06-09:Claude Fable 5 发布,Mythos 级能力向全员开放,OpenAI 提交 S-1
- AI Agent 生态速报 | 2026-06-08:O'Reilly 重绘 Agent 六层栈,Anthropic 发布 N-day 漏洞利用实测数据,Hermes Agent 登上桌面端
- AI Agent 生态周报 | 第 24 周:框架选型第一份实测数据来了,OpenAI 宣布「chat 已死」
- AI Agent 生态速报 | 2026-06-07:Mythos 进驻 NSA,GPT-5.6 候选版本现身,Claude Code 爆凭证漏洞
- AI Agent 生态速报 | 2026-06-05:Anthropic 警告 AI 将自建下一代模型,LangGraph 发布生产容错三原语
- AI Agent 生态速报 | 2026-06-04:Nemotron 550B 上线,Foundry 可观测全链路开放,Anthropic 敲定 IPO 承销团
- AI Agent 生态速报 | 2026-06-03:Foundry 三层生产化落地,Anthropic 递交 IPO,Nemotron 550B 明日上线
- AI Agent 生态速报 | 2026-06-02:Build 2026 开幕,Windows 宣布成为 Agent 平台