

1/5
2026/7/1 · 9:24
Claude政策更新,隐私要重算了
这期图片笔记拆解 Claude 隐私政策更新背后的数据边界:个人账户、连接服务、训练开关和企业敏感数据治理都要重新看清。

Claude 的隐私政策更新,不只是「条款又改了」这么简单。
官方隐私中心显示,7 月 8 日生效的这次更新适用于 Claude Free、Pro、Max 等个人账户,不适用于 Team、Enterprise、开发者平台等按商业条款或其他协议处理的服务。1
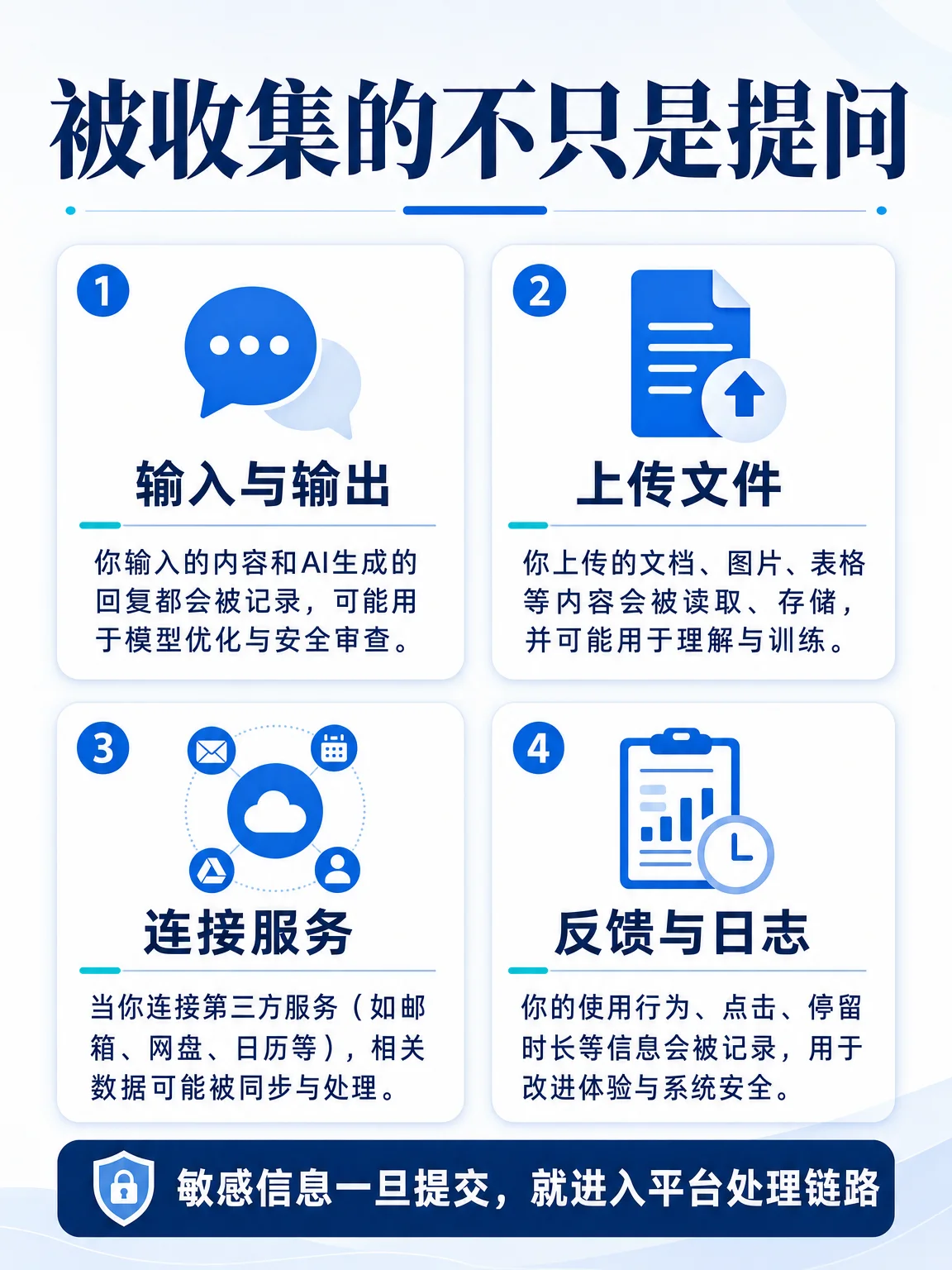
真正值得关注的是:AI 对话已经不只是问答框。政策页把 Inputs 和 Outputs、上传文件、连接的第三方服务、反馈、研究参与数据、技术信息等都纳入说明;当 Claude 被授权连接第三方服务时,相关指令和内容可能被发送给第三方服务处理。2
训练边界也要看清。Anthropic 隐私政策写明,用户的 Inputs 和 Outputs 可被用于训练和改进模型,除非用户在账户设置中退出;即使退出,用户反馈或被标记用于安全审查的内容仍可能被用于模型改进。2
这件事对普通用户的提醒是:病历、合同、薪资、债务、客户资料、代码等敏感信息,一旦进入公域 AI,就可能进入平台记录、模型改进、审核、第三方应用和技术日志等处理链路。开关有用,但它不是全链路保护。
对企业来说,风险更现实:员工用个人 AI 账号处理客户资料、商业计划或法律文件,问题不只是谁看见了这段对话,还包括数据是否被带出组织边界、是否被第三方应用处理、是否触发安全审查与合规责任。
所以,真正高敏感的 AI 使用,不应只依赖「少传一点」或「打开/关闭某个设置」。公开资料显示,AI 加密平台正在尝试把本地加密、密态流转、密态推理、密态存储与本地密钥结合起来,让数据在「可用不可见」的前提下参与 AI 处理。3 另一份公开报道也提到,相关密态计算方案面向医疗、金融、法律、科研、政企等高敏感场景,核心目标是补上 AI 产业链里的信任缺口。4
这期图集想讲清楚一句话:AI 产品越会连接文件、应用和工作流,隐私边界就越不能停留在「我有没有点退出」。敏感数据需要的是从输入、推理到存储的结构性防护。
图集看点
- Claude 隐私政策这次更新影响谁
- 为什么「被收集的」不只是提问文本
- 模型训练退出开关的真实边界
- 企业敏感数据为什么不能先明文出门
- AI 加密平台为什么要强调「可用不可见」
小红书发布文案
Claude 隐私政策更新,最值得看的不是日期,而是它提醒了一个现实:AI 对话早就不只是「你问一句,它答一句」。
当 AI 能上传文件、连接网盘/邮箱/日历、执行多步任务,隐私风险也会从聊天框扩展到文件、第三方应用、日志、反馈和模型改进链路。
这次官方说明里有三个重点:
✅ 7 月 8 日生效的更新主要影响个人账户,企业服务另按客户协议处理。
✅ 输入、输出、上传内容、连接服务、反馈和技术信息都可能进入平台处理链路。
✅ 训练开关能降低一部分使用风险,但反馈和安全审查等场景仍有例外边界。
所以,真正敏感的数据,不该先变成明文再交给公域 AI。病历、合同、客户资料、财务数据、核心代码这些内容,一旦进入公共平台,后续就不只是「会不会被训练」的问题,还涉及记录留存、第三方处理、组织合规和责任边界。
更稳妥的方向,是让数据在本地先加密,在推理、存储、返回过程中尽量保持密态,由用户本地掌握密钥。AI 加密平台强调的「可用不可见」,本质上就是把隐私保护从一个设置开关,升级成一套全链路机制。
你会把哪些资料交给 AI?又有哪些内容是绝对不该明文上传的?欢迎评论区聊聊。
#AI 隐私观察 #Claude #AI 安全 #数据安全 #隐私保护 #企业合规 #AI 加密平台 #密态计算 #小红书科技笔记
コメント
ログインするとコメントできます。