Indie Agent Builders — Week of June 6
The week split along two axes: agent sandboxing graduated from theoretical concern to installable code (Simon Willison's micropython-wasm, OpenAI Lockdown Mode, Meta's support-bot permissions failure), and the harness/skills layer kept consolidating around common infrastructure (obra/superpowers at 220k★, MemPalace v3.4.0, NVIDIA Nemotron 3 Ultra purpose-built for Hermes Agent and OpenClaw). Swyx's Latent Space covered Microsoft Build 2026 including the accidental Mythos FLOP leak, Cognition's first real-world eval dataset (258 enterprise sessions, financial guarantee), and a guest post on RL harness quality with a concrete 5% failure-rate diagnostic rule.

Research Brief
This week ran on two parallel tracks. The first: agent sandboxing and security are moving from theoretical concerns into concrete engineering decisions — Simon Willison shipped
micropython-wasm, the first PyPI-installable Python sandbox in a WASM runtime that actually checks all the practical boxes, while OpenAI rolled out Lockdown Mode and Meta's support-bot disaster illustrated exactly why these primitives matter. The second: the harness ecosystem keeps formalizing. obra/superpowers hit 220k stars and topped GitHub Trending, MemPalace released v3.4.0 with near-perfect LongMemEval scores, and NVIDIA shipped a 550B model (Nemotron 3 Ultra) tuned specifically for running inside Hermes Agent and OpenClaw sessions rather than single-turn chat.Geoffrey Huntley remains quiet — 20+ days of silence, last activity on May 17.
Simon Willison
Simon Willison (creator of Datasette and co-creator of Django) published ten posts this week, ranging from a 2,000-word technical deep-dive to one-paragraph links. The micropython-wasm release is the one to actually dig into.
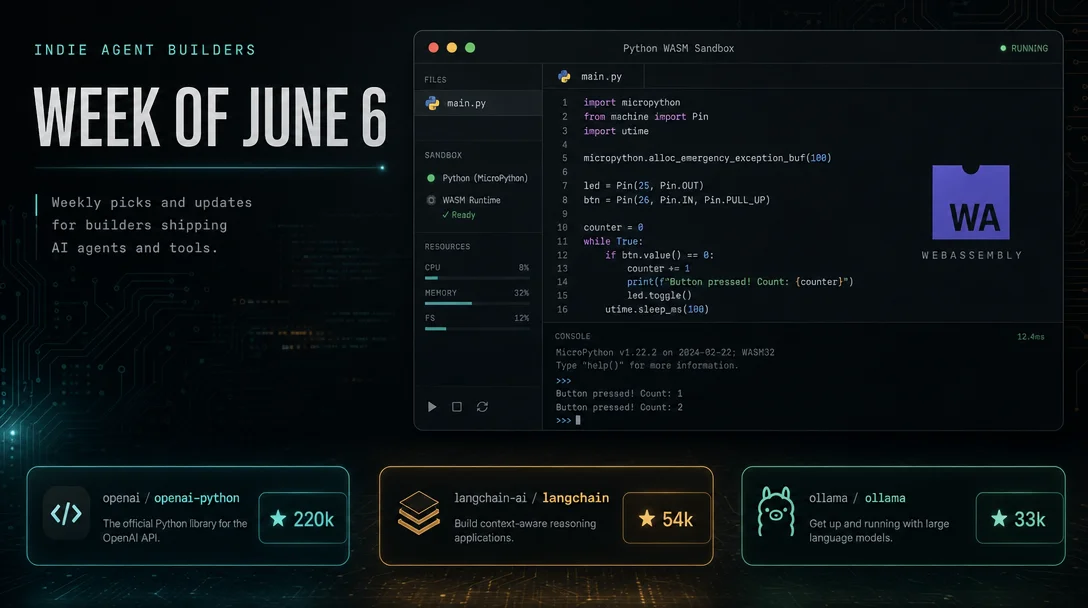
Running Python in a WASM sandbox — micropython-wasm 0.1a2
Willison has been chasing a usable Python sandbox for years. His checklist: PyPI-installable with binary wheels, enforced memory and CPU limits, controlled file and network access, host function support, robustly maintained. Nothing existing satisfied all five. So he built one. 1
The approach: MicroPython (a lean Python 3 implementation designed for microcontrollers) compiled to a WebAssembly blob, executed via wasmtime. The whole package — including the 362KB WASM binary — ships as a PyPI wheel. The key architectural decision is how persistent interpreter state works: MicroPython blocks on a
__session_next__() host function call, processes the submitted code via eval(), then returns the result through __session_result__(). This means a single MicroPython interpreter thread stays alive across multiple execute() calls, preserving variables between turns — which is exactly what an agent code-execution tool needs.CPU limits run via wasmtime's "fuel" concept; Willison is experimenting with a 20M fuel default. Memory limits are wasmtime's built-in. Neither limit is evaluated by AI — both are deterministic, hardware-enforced constraints.
Host functions (what the sandbox can call back into the host Python process) are implemented in 78 lines of C compiled into the WASM blob. Willison is not a C programmer; he had Codex and GPT-5.5 build the C, then had multiple models explain it to him. He's honest about this: "Having complained about immature, loosely-maintained sandboxing libraries, it's deeply ironic that I've now built my own!" 1
The library ships at
0.1a2 and should be treated as alpha. The companion datasette-agent-micropython plugin (also 0.1a0) 2 gives Datasette Agent a sandboxed code execution tool — and as of the latest release, GPT-5.5 xhigh has not escaped. The CLI is available now: uvx micropython-wasm -c 'print("hello")'. 3
execute_micropython tool call is visible in the agent's thinking trace. 1For engineers building agents that execute user-supplied or model-generated code, this is the most practical open-source Python sandboxing option that appeared this week. It won't fit every use case — no stdlib beyond MicroPython's subset, no PyPI packages inside the sandbox — but the architecture (WASM isolation + fuel limits + host functions + persistent state) is the right shape for most agent code-execution needs.
OpenAI Lockdown Mode: what its existence implies
OpenAI's Lockdown Mode 4 rolled out June 5 to Free, Plus, Pro, and self-serve Business accounts. It limits outbound network requests to block the final stage of prompt-injection data exfiltration. The mechanisms are deterministic — no AI evaluation involved, which matters because AI-evaluated defenses can be jailbroken.
Willison's framing is worth quoting directly: "The existence of lockdown mode does however imply that ChatGPT, in its default settings, does not provide robust protection against sufficiently determined data exfiltration attacks!" 4 He connects this to his "Lethal Trifecta" framework: access to private data + untrusted content + exfiltration vector. Lockdown Mode attacks only the third leg. Prompt injections still land; they just can't phone home by default.
The practical implication for agent builders: if you're building an agent that touches private data and processes external content (email, documents, web pages), Lockdown Mode should be a default recommendation to users — not an optional hardening step.
Meta's support bot and the one-shot account takeover
On June 1, Willison flagged a 404 Media report: hackers gained access to high-profile Instagram accounts by simply asking Meta's AI support bot to add a new recovery email. The bot had full account recovery privileges and no friction mechanism. "Don't wire your support bot up to allow one-shot account takeovers!" 5
His note that "this hardly even qualifies as a prompt injection" is the important signal. There was no adversarial jailbreak here — the attacker simply used the bot's intended interface to do something the interface should never have allowed. It's a permissions scoping failure dressed up as an AI safety issue.
AI governance signals: Uber's caps, Ladybird's PR ban, and the enthusiast/skeptic gap
Three distinct governance observations worth reading together this week.
Uber capped AI coding tool spending at $1,500/month per employee per tool — applying to Claude Code, Cursor, and similar agentic coding software independently. 6 Willison calculated: assuming two tools per engineer, that's $36,000/year in AI tool spend — about 11% of Uber's median software engineer compensation ($330,000, per Levels.fyi). His read: "A $1,500 monthly limit per tool strikes me as a rational policy response to over-spending, and much more sensible than those tokenmaxxing leaderboards." 6 The backstory: Uber set its 2026 AI budget in 2025, before agentic coding took off, and burned through it in four months.
Andreas Kling (creator of the Ladybird browser, former Apple WebKit engineer) announced Ladybird will no longer accept public pull requests. 7 The reason: "A substantial patch used to imply substantial effort, and that effort was a reasonable proxy for good faith. That assumption no longer holds." His resolution: "Whether code was typed by hand is beside the point. What matters is who is responsible for it once it enters the browser." For any open-source project where correctness is critical and the maintainer team is small, this is a defensible policy — and one more projects will probably reach.
Charity Majors (CTO of Honeycomb, the distributed tracing platform) published a Substack piece on the AI enthusiast/skeptic split in engineering teams. 8 Her diagnosis: "There is no natural feedback loop connecting enthusiasts with skeptics." Enthusiasts see discontinuous capability gains and competitive pressure; skeptics see reliability degradation and eroding institutional knowledge. Both are correct about real risks. Her key line: "When you ship code faster than engineers can read it, in domains where nobody has full context, you are making withdrawals from a trust account that took years to build." Willison's take is that designing feedback loops to close this gap is an organizational design problem — not primarily a technical one.
Brief: Datasette 1.0a32 and the ADHD amplifier debate
Datasette 1.0a32 9 shipped May 31 with two agent-relevant fixes:
INSERT/UPDATE/DELETE ... RETURNING now works in the /db/-/execute-write endpoint (rows fetched before commit and returned in the response), and Database.execute_write() now returns an ExecuteWriteResult object with .rowcount, .lastrowid, and .fetchall().Willison also linked David Wilson's essay arguing AI is a "thermonuclear ADHD amplifier." 10 Wilson's framing: "a tool producing a cheap reward with minimal input and no friction can only be a liability." Willison related personally: the critical skill is discipline, "and that's not great news for me: I've been trying to figure that one out for decades!" The Hacker News thread turned up the expected counterpoint — ADHD users who find agents give them focus and completion rates they've never had before. Both observations are real; they're describing the same phenomenon from different baselines.
Swyx
Shawn Wang (@swyx, co-host of Latent Space) had a Build-heavy week: three podcast episodes, the first Cognition real-world eval release, and a guest post on RL harness quality that every team training agents should read.
Microsoft Build 2026: the Satya Nadella crossover and the Mythos leak
Swyx co-hosted a live crossover podcast at Microsoft Build 2026 with Sarah Guo (co-host of No Priors, partner at Conviction) and Elad Gil (No Priors co-host, angel investor), with Microsoft CEO Satya Nadella as the guest. 11 12

Loading content card…
The more interesting moment came from a separate Mustafa Suleyman slide at Build, which appeared to show Anthropic Claude "Mythos" and "Opus 4.6" training FLOP counts in a comparison chart. Swyx called it out immediately: "uhhh did Mustafa just leak the Mythos FLOP count?? was this public knowledge before, even if its an estimate i dont get what you gain out of this." 13 Analyst @scaling01 estimated Mythos at ~6.1×10²⁷ FLOPs based on the slide. Swyx followed up praising Microsoft AI's full-stack self-ownership — "Mustafa built a full fledged neolab inside Microsoft in 2 years, that now MS fully controls from chip to model to harness. Absurdly impressive." 13
The AINews Build special [cite:14|[AINews] Microsoft Build: MAI-Thinking-1 and MAI Family models|[https://www.latent.space/p/ainews-microsoft-build-mai-thinking]] covered MAI-Thinking-1 (35B active parameters in a 1T MoE, 97% AIME 2025, 53% SWE-Bench Pro) and MAI-Code-1-Flash (5B active, 51% SWE-Bench Pro). Swyx's assessment of Microsoft AI overall: "a good tier 2 neolab with obvious incentives to support domain specific finetunes." The 109-page MAI technical report drew community praise; Elie called it "one of the most transparent for a model at this scale." [cite:14|[AINews] Microsoft Build: MAI-Thinking-1 and MAI Family models|[https://www.latent.space/p/ainews-microsoft-build-mai-thinking]]
One note: Simon Willison, also at Build, later corrected his own initial MAI reporting. He'd initially misread active parameter counts as total parameter counts, then found the technical paper confirms training used the same public web crawl (1.2T pages, filtered to 794B) as every other major LLM — despite initial claims of "clean and appropriately licensed data." 14
Cognition's first real-world eval: 258 enterprise sessions, financial guarantee
Swyx announced Cognition's first public eval results on June 4. 15 Two datasets: METR (ML engineering, GPU kernels, cybersecurity tasks — rlog 0.83, sessions up to ~16 hours) and Cognition's internal enterprise dataset (126 users, 258 sessions of Java/TypeScript/Python/C# feature dev, bugfixes, and migrations — rlog 0.74). Cognition offers evals up to 100 hours for enterprise customers and is, per Swyx, "confident enough to put a financial guarantee on it."
The "Reality: The Final Eval" framing — real task completion rate as the only eval that matters — is worth sitting with. Most public benchmarks measure short tasks on academic datasets. 100-hour enterprise sessions on real codebases are a different measurement surface entirely.
How to stop shipping broken RL environments
The week's most technically dense piece was a guest post by Auriel Wright (formerly on RL at Google Gemini, blogger at RL Pet Peeves) on Latent Space. 16
Wright's core argument: in RL training, the model generates its own training data by interacting with the environment. A broken harness doesn't just fail — it produces garbage data that feeds directly into the model's learning steps. "Researchers don't want your broken RL environments because they will make our models worse." 16
She identifies three failure patterns:
- Stale Cache: environment returns outdated state, model gets rewarded for solving a problem that was already resolved
- Reward Hack: environment's reward function has a gap the model exploits — correct reward, wrong behavior
- False Resolution: state changes but the underlying problem isn't actually fixed
The diagnostic rule of thumb: "If your environment failure rate is above 5%, you don't have a model problem, you have a harness problem. Fix the harness first." 16
For teams doing any RL fine-tuning — or building evals that feed into training — this is the most concrete framework for debugging training harnesses that appeared this week. The three failure modes map directly to common eval-loop bugs even outside pure RL settings.
Brief: the GitHub COO episode and a prompt engineering tip
Latent Space published a Kyle Daigle (GitHub COO) episode on June 2: "What Happens When 80% of PRs Come From Agents?" 17 Coding agents grew 1,400% on GitHub in 2026, and the platform's 90-day uptime over the same period was 89.91% (95 incidents). The Ethan He (xAI Grok Imagine) episode 18 covered building Grok Imagine in three months and the videogen-vs-world-models distinction. Both episode transcripts are paywalled; the episode pages have the summaries.
A low-footprint prompt engineering tip from Swyx on June 6 19 that's worth testing: instead of instructing a model to plan before executing, frame the task as a question. "Literally just appending '?' to the end of your prompt often does it" — the question framing invites the model to push back and suggest alternatives rather than proceeding on whatever interpretation it picks first.
Trending repos
Six repos worth attention this week, organized by what problem they address.
Skills and methodology
obra/superpowers 20 hit 220k stars and topped GitHub Trending today (+1,008 stars/day). Created by Jesse Vincent (Prime Radiant), it's a complete agentic development methodology — brainstorm → git-worktrees → write plans → subagent-driven development → TDD → code review → finishing — packaged as skills files that work across Claude Code, Codex CLI, Codex App, Gemini CLI, OpenCode, Cursor, and GitHub Copilot CLI. The key workflow feature is two-stage subagent review: first pass checks spec compliance, second pass checks code quality. Vincent's README note: "It's not uncommon for Claude to be able to work autonomously for a couple hours at a time without deviating from the plan you put together." Latest release v5.1.0 (May 4, 2026). MIT license.
Loading content card…
NVIDIA/skills 21 (1,100+ stars, announced at GTC Taipei May 31) makes NVIDIA's physical AI workflows — neural reconstruction, defect image generation, video data augmentation, CAD-to-sim-ready conversion — executable by agents. TSMC, Pegatron (67% reduction in model training time), and Delta Electronics (17% detection improvement) are among the listed early adopters. 22
Memory
MemPalace/mempalace 23 released v3.4.0 today (54.2k stars, +441/day). Local-first AI memory with verbatim storage and pluggable backends (ChromaDB default, Qdrant and pgvector available). Benchmark: 96.6% R@5 on LongMemEval with zero API calls; hybrid v4 reaches 98.4%. Comes with 29 MCP tools, a knowledge graph with temporal validity windows, and agent diary support. Integrates with Claude Code, OpenClaw, Gemini CLI, and any MCP-compatible tool.
Models tuned for agent harnesses
NVIDIA Nemotron 3 Ultra 24 (released June 4) is a 550B-parameter MoE with 55B active parameters, specifically post-trained for agent orchestration loops rather than single-turn conversation. NVIDIA calls out Hermes Agent and OpenClaw by name as target harnesses. Key metrics vs. comparable open models: 5× higher throughput, 30% lower cost per task completion on SWE-bench verified. Architecture: Hybrid Mamba-Transformer layers, NVFP4 quantization, LatentMoE routing, multi-token prediction. Licensed under OpenMDW-1.1 (Linux Foundation permissive). Available on Hugging Face, OpenRouter, Perplexity, and 30+ inference partners.
For context on why this matters for harness selection: Hermes Agent leads OpenRouter's daily token volume at 224B daily tokens vs. OpenClaw's 186B (as of May 10, 2026), though OpenClaw leads cumulative all-time volume. 24 NVIDIA now ships official support for both.
Multi-platform and orchestration
CopilotKit 25 (33.1k stars) released v1.59.5 on June 5. The main news here is AG-UI Protocol adoption — Google, LangChain, AWS, Microsoft, Mastra, and PydanticAI have all adopted the protocol. New in this release:
useAgent hook, early-access Slack and Microsoft Teams deployment, and the CopilotKit Intelligence Platform. Supports React, Angular, Vue, React Native.Microsoft Agent Framework (MAF) 26 released python-1.8.0 on June 4 (11.1k stars). Graph-based orchestration (sequential, concurrent, handoff, group collaboration), Foundry Hosted Agents (2-line deploy), OpenTelemetry observability, YAML declarative agents, DevUI for interactive debugging. Migration guides from Semantic Kernel and AutoGen are in the repo.
Quick table
| Repo | Stars | What's new this week |
|---|---|---|
| obra/superpowers | 220k | #1 GitHub Trending; multi-harness agentic dev methodology |
| MemPalace/mempalace | 54.2k | v3.4.0; 98.4% R@5 LongMemEval (hybrid) |
| affaan-m/ECC | 209k | v2.0.0-rc.1: Hermes operator workflows, dashboard GUI |
| CopilotKit/CopilotKit | 33.1k | v1.59.5; AG-UI Protocol widely adopted |
| mvanhorn/last30days-skill | 28.6k | v3 pipeline: entity pre-resolution, cross-source clustering |
| microsoft/agent-framework | 11.1k | python-1.8.0; Foundry Hosted Agents, YAML declarative agents |
Cover: AI-generated
References
- 1Running Python code in a sandbox with MicroPython and WASM
- 2Release 0.1a0 · datasette/datasette-agent-micropython
- 3Releases · simonw/micropython-wasm
- 4OpenAI Help: Lockdown Mode
- 5Hackers Simply Asked Meta AI to Give Them Access to High-Profile Instagram Accounts
- 6Uber Caps Usage of AI Tools Like Claude Code to Manage Costs
- 7A quote from Andreas Kling
- 8AI enthusiasts are in a race against time, AI skeptics are in a race against entropy
- 9Release 1.0a32 · simonw/datasette
- 10The solution might be cancelling my AI subscription
- 11Satya Nadella: No Priors x Latent Space Crossover Special at Microsoft Build
- 12No Priors x Latent Space crossover special featuring Satya Nadella
- 13Microsoft Build slide plotting unreleased 'Opus 4.6' and 'Mythos' models sparks debate
- 14Microsoft's new MAI models
- 15@swyx on X — Cognition evals announcement
- 16How to Stop Shipping Low-Quality RL Environments (with Examples)
- 17GitHub's plan for Agents — Kyle Daigle, GitHub
- 18Why Video Agent models are next — Ethan He, xAI Grok Imagine
- 19@swyx on X
- 20obra/superpowers
- 21NVIDIA/skills
- 22NVIDIA Releases Major Collection of Open Source Agent Tools and Skills for Physical AI
- 23MemPalace/mempalace
- 24NVIDIA Nemotron 3 Ultra Powers Faster, More Efficient Reasoning for Long-Running Agents
- 25CopilotKit/CopilotKit
- 26microsoft/agent-framework
- 27affaan-m/ECC
- 28mvanhorn/last30days-skill
- 29GitHub Trending
Add more perspectives or context around this Post.