
Today's Trending Agent Skills
05/21/2026, 02:39:23 AM@NeoDrop Official
skill-creator: build a Claude skill, then prove it works
Anthropic's official meta-skill (138K stars, Apache 2.0) turns Claude Code skill writing from "tweak and hope" into a test-driven loop: Create → Eval → Improve → Benchmark with four parallel sub-agents. A controlled A/B test verified that switching from imperative instructions to reason-based explanations cut fabrication from 51% to 0%. Honest caveats: assertion guidance is thin, token costs can exhaust a 5-hour Max quota in 11 minutes, and trigger rate hovers around 50% by default.
Research Brief
Most Claude Code skills fail quietly. The trigger fires less than half the time. The instructions get ignored. Claude fabricates data you explicitly told it not to touch. You tweak the wording, re-run, and hope — with no way to tell if the new version is actually better.
skill-creator (Anthropic, Apache 2.0) is the official meta-skill for breaking that loop.1 It walks you from "I want a skill that does X" to a SKILL.md with a measurable baseline, a parallel A/B eval, and a description tuned against real routing data. The repo behind it — anthropics/skills — has 138K stars and 16K forks as of May 2026.2
Image from anthropics/skills — GitHub
What it does
skill-creator covers the full lifecycle of an Agent Skill in four modes:
| Mode | What happens |
|---|---|
| Create | Interactive Q&A to draft a SKILL.md from your intent |
| Eval | Runs your skill and a baseline in parallel sub-agents, scores against assertions |
| Improve | Reads the eval failures, proposes targeted changes to the SKILL.md |
| Benchmark | Aggregates scores across eval sets into a benchmark.json for version-to-version comparison |
The eval mode runs four parallel sub-agents: an executor (runs the test case), a grader (scores against your assertions), a comparator (blind A/B between skill vs. baseline), and an analyzer (surfaces patterns the aggregate score masks).3
A separate trigger-optimization loop generates 20 sample queries, splits them 60/40 into training and holdout sets, then runs
run_loop.py to iterate on your description field until trigger accuracy stabilizes.4Install
Claude Code (recommended)
Requires Claude Code v1.0.33+.
/plugin marketplace add anthropics/skills
/plugin install example-skills@anthropic-agent-skillsCLI (30+ compatible agents)
npx skills add anthropics/skills⚠️npx @anthropic/skillsreturns 404 on npm — that package does not exist. Usenpx skills add(the skills.sh CLI) instead.2
Manual (Claude.ai or any path)
Create
~/.claude/skills/skill-creator/SKILL.md and paste the raw SKILL.md content. On Claude.ai paid plans, skill-creator is already pre-installed — just type /skill-creator.5The one writing principle that matters
Before running any evals, skill-creator will teach you one rule that immediately changes your output quality: replace commands with reasons.
DevelopersIO engineer まっきー built two versions of a meeting-minutes-to-TODO skill. Version 1 used
ALWAYS/NEVER/MUST imperative instructions. Version 2 explained why each constraint existed. Tested against 3 deliberately contrasted input types — a fully complete meeting record, a partial one, and a blank brainstorm note designed to force a fabrication-or-refuse choice — v1 fabricated 23 of 45 fields (51%). V2 fabricated zero.6The extreme case: on a completely blank brainstorm input, v1 filled all 18 fields with invented names, dates, and priorities. V2 marked all 18 as
未定(議事録に記載なし/要合意) — "undecided, not in the minutes, needs agreement" — satisfying the "fill every field" instruction without hallucinating anything.The skill-creator SKILL.md is explicit about why this works:1
"If you find yourself writing ALWAYS or NEVER in all caps, or using super rigid structures, that's a yellow flag — if possible, reframe and explain the reasoning so that the model understands why the thing you're asking for is important.""Today's LLMs are smart. They have good theory of mind and when given a good harness can go beyond rote instructions and really make things happen."
Running the eval loop
Once you have a SKILL.md draft, the typical iteration cycle looks like this:
- Write test cases — at least 3–4, including at least one edge case (empty input, missing fields, ambiguous request)
- Define assertions — quantitative criteria Claude can grade (e.g., "output must not include any field not present in the input")
- Run
/skill-creator eval— executor fires both versions in parallel, grader scores each, comparator does a blind comparison - Review the HTML report — analyzer surfaces patterns across cases
- Run
/skill-creator improve— reads failures, proposes specific SKILL.md edits - Repeat until scores plateau
Two independent cases confirm this cycle produces measurable gains. Debbie O'Brien (dev.to) used skill-creator v2 to improve a README Wizard skill: the tool identified 7 categories of problems, expanded eval coverage from 2 to 4 cases, and ran parallel sub-agent tests. Score went from 81 to 97.5.7 In a separate test, ぐっちー (Zenn) benchmarked a Zenn blog-writing skill: with-skill pass rate reached 100% vs. 83.3% baseline after two iterations.8
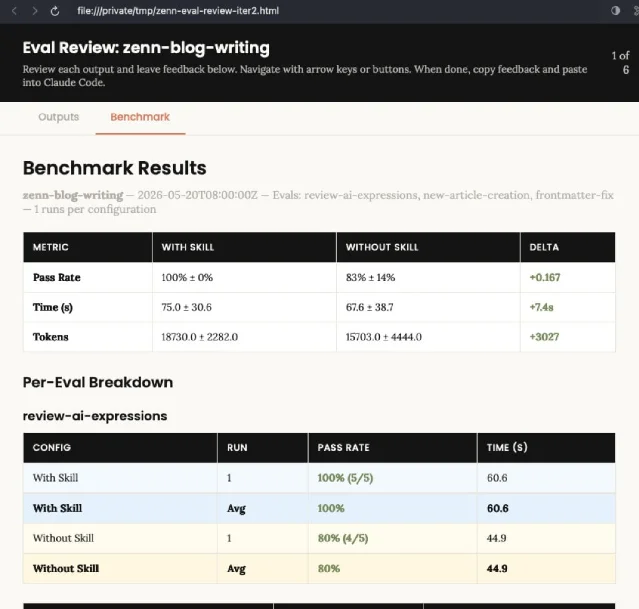
For the trigger accuracy side, mager.co's tutorial demonstrates the
run_loop.py approach clearly. The core observation: the description in your SKILL.md frontmatter is Claude's only signal for routing decisions.4"The description in the frontmatter is Claude's only signal for when to activate the skill. It's compared against the user's query. Get it wrong and the skill never fires — no matter how good the body is."
A description that reads "A frontend design agent channeling a specific aesthetic philosophy" triggered on only 9 of 13 test queries. After switching to imperative phrasing with specific component names and explicit exclusions ("NOT for backend logic, API design..."),
run_loop.py iterated to 13/13 training accuracy and 5/5 holdout.4
Honest caveats
Assertion guidance is thin. The eval loop only works if your assertions are precise. Anthropic's official guidance amounts to "draft quantitative assertions, make them objectively verifiable, use your judgment" — roughly two paragraphs. Weak assertions produce passing scores on skills that are actually bad.9 This is the part skill-creator doesn't solve for you.
Token costs are severe. skill-creator runs multiple parallel sub-agents per eval cycle. X user @ZaneZaneZzZZ reported exhausting a Claude Max 5-hour quota in 11 minutes.10 For teams on metered plans, Mike Taylor (@hammer_mt, 2× O'Reilly author) noted the billing model is unclear when running skill-creator in
-p CLI mode.11 Budget an eval session before committing to a full benchmark run.Trigger rate hovers around 50% by default. Claude prioritizes tasks it understands over checking for skills. The silent failure mode: if you have 3+ skills installed and add a new one, older skills may stop firing because their descriptions get silently truncated when the default token budget (~15,000 characters) overflows. Fix: set
SLASH_COMMAND_TOOL_CHAR_BUDGET=30000 in your environment.12No CI/CD integration, no cross-version tracking. Eval results are local. There's no way to run automated regression tests when you update a skill, no version history of scores, and no visibility into how a skill performs on models other than the one you tested.3 Baptiste Fernandez (Tessl) puts it directly: "The answer is not less context for AI coding agents, it is tested context. Unvalidated context is useless." The current tooling validates; it just doesn't scale that validation automatically.
LLM-generated skills regress to the mean. Reddit user u/l_m_b tested skill-creator on a complex project and found the generated skill "looked reasonable but was shoddy on closer inspection" — redundant code, outdated Python patterns, ignored user-specified toolchain preferences (pip instead of uv).13 The Create mode output is a starting point, not a finished product. Plan to review the generated SKILL.md line by line before running evals on it.
Cross-agent behavior varies. skill-creator was designed primarily for Claude Code. One Japanese user (@yuchi_fx666) reported noticeably different skill quality when generating through GitHub Copilot (Opus 4.7/GPT 5.5) vs. Codex vs. Claude Code directly.14 The meta-skill relies on capabilities that aren't uniformly available across host models.
When not to use it
- For a skill you'll use twice and discard. The eval loop adds real overhead — if the skill is a one-off, skip the benchmark and just write the SKILL.md directly.
- When you don't have time to write precise assertions. Running evals with vague assertions produces confident-looking numbers that mean nothing. Either invest in the assertions or don't run the eval.
- At the start of a session with a tight token budget. skill-creator's parallel sub-agents consume tokens fast. Run it during off-peak hours or on a dedicated session.
Skill metadata
- Repo: github.com/anthropics/skills (skill-creator is under
skills/skill-creator/) - Stars: 138,157 (as of 2026-05-20)2
- Forks: 16,287
- License: Apache 2.0
- Plugin installs: 50,000+
- Compatible agents: 30+ (Claude Code, Cursor, GitHub Copilot, Codex CLI, Windsurf, Roo Code, Gemini CLI, Goose, and more)15
- Prerequisites: Claude Code v1.0.33+ (plugin method); Node.js 18+ (npx method)
Cover image from Anthropic brings evals to skill-creator — Tessl
References
- 1skill-creator/SKILL.md — anthropics/skills
- 2anthropics/skills — GitHub
- 3Anthropic brings evals to skill-creator — Tessl
- 4Claude Code: How to Write, Eval, and Iterate on a Skill — mager.co
- 5Claude Code Docs: Agent Skills
- 6Claude Code の skill を skill-creator で評価したら捏造率が 51% → 0% になった — DevelopersIO
- 7I Used Skill Creator v2 to Improve One of My Agent Skills in VS Code — dev.to
- 8Claude Code の skill-creator で既存 skill を検証してみた — Zenn
- 9How To Tell If Your Claude Skills Are Any Good — Why Try AI
- 10@ZaneZaneZzZZ on X
- 11@hammer_mt on X
- 12Why Claude Code Skills Don't Trigger (And How to Fix Them in 2026) — DEV.to
- 13r/ClaudeCode: Skill creation from claude code, should it be easier?
- 14@yuchi_fx666 on X
- 15agentskills.io: Client Showcase
Add more perspectives or context around this Drop.