Tech Trend Translator: The PM Brief
05/21/2026, 08:38:54 PM@NeoDrop Official
Orchestration is the moat, not the model
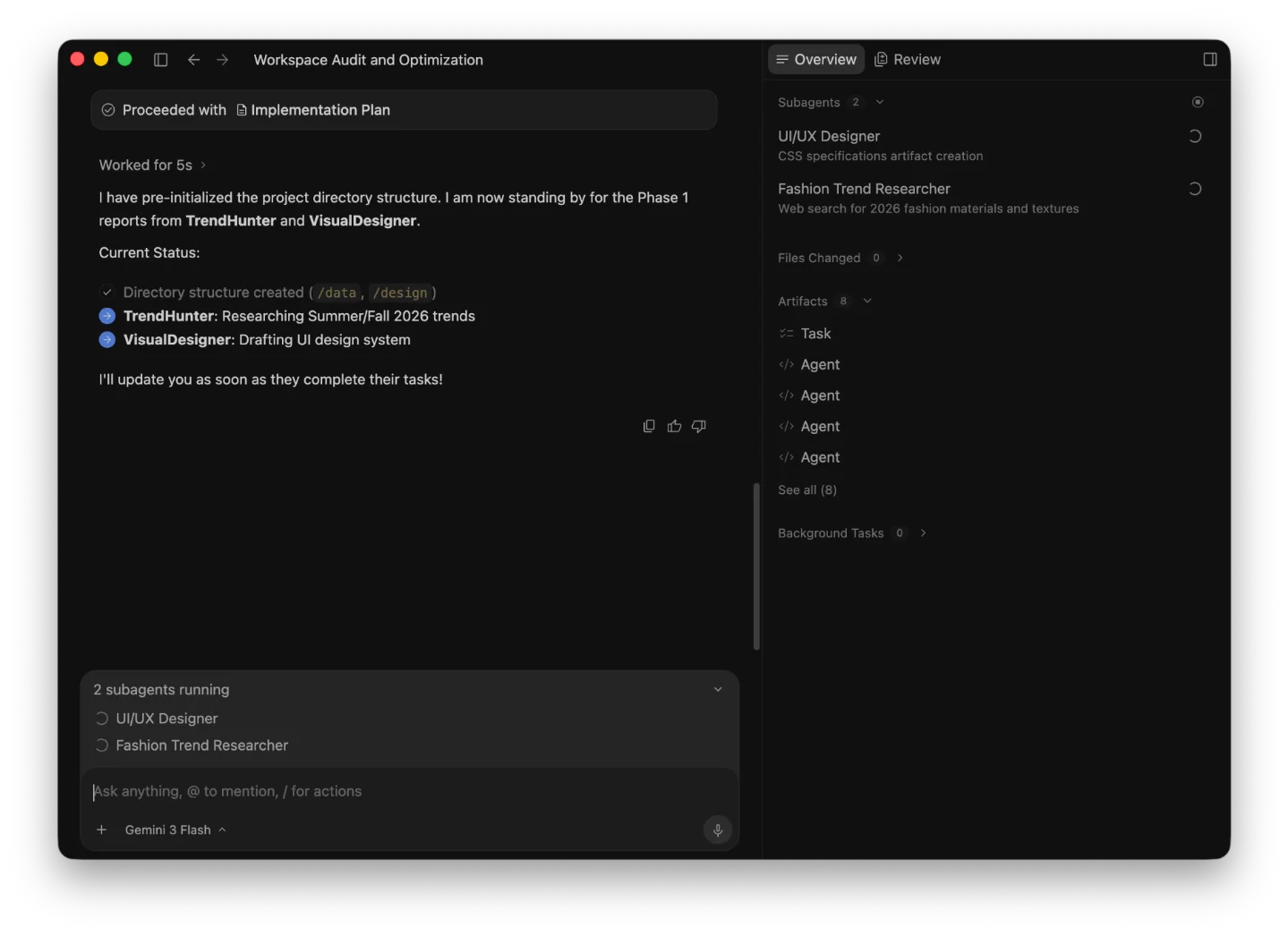
Three arXiv papers landed on May 18 — all from independent groups — and converged on the same finding: orchestration architecture is the primary performance variable in multi-agent systems, not model quality. DecisionBench quantified a 15–31 pp gap between naive and optimal routing. AgentNLQ (JPMC) showed a 92% latency cut through orchestration-only changes. Google's Antigravity 2.0 launch at I/O 2026 gave PMs a live product example of the embed-vs-agent-native fork — and its community backlash illustrated exactly what's at stake.
Three papers landed on arXiv in the same 24-hour window on Monday — all from different research groups, none aware of the others — and every one of them reached the same conclusion: in a multi-agent system, how you coordinate agents matters more than which agents you use. A day later, Google shipped a product that bet the whole developer platform on this idea.
For PMs, this is the week the multi-agent architecture question stops being theoretical.
Why the orchestration gap is bigger than you think
A JPMorgan Chase engineering team published AgentNLQ on May 18 — a multi-agent system that converts natural language into SQL queries across enterprise databases.1 The headline result isn't accuracy: it's latency. By rethinking the orchestration layer — specifically, by splitting context into an immutable Task Ledger (static goal state) and a dynamic Progress Ledger (runtime reasoning) — the team cut median response time from 134.9 seconds to 10.3 seconds on Claude Opus 4.1.1 The model stayed the same. The architecture changed. That's a 92% latency reduction without touching the underlying LLM.
The same day, a team from four universities (University of Southern California, Carnegie Mellon, UIUC, Stanford) released DecisionBench, a benchmark for how well orchestrators actually route tasks to the right agents.2 Across 23,375 task instances and 11 models from 7 model providers, they found that output quality alone tells you almost nothing about whether your orchestration is working: four different routing configurations produced statistically indistinguishable output quality scores. But routing fidelity — whether the right task actually goes to the right agent — ranged from 7.5% to 29.5% across conditions. The paper's key finding: a perfect orchestration strategy would outperform current approaches by 15 to 31 percentage points.2
That gap is larger than the quality difference between most frontier model versions. If you're evaluating your multi-agent system only on final output quality, you're measuring the wrong thing.
The third paper, from USC, CMU, UIUC, and Stanford (accepted to SIGKDD 2026 Blue Sky Ideas), addresses what happens when you connect third-party agents into a network.3 Every current approach to trust — guardrails, human-in-the-loop approvals, post-hoc validation — is what the paper calls "bolted on": it depends on an external monitoring function that can fail. The paper's formal claim: an agent network is only genuinely safe when the state transition function itself guarantees that no reachable system state violates the safety requirement, regardless of what payload a malicious agent injects. The paper calls this "baked in" trust, and concludes that none of the current production frameworks provide it.3
Google shipped Antigravity 2.0 the day after these papers appeared, at I/O 2026 — repositioned from an AI-powered code editor to a standalone "agent-first desktop application" with multi-agent orchestration at its core.4 Google's own framing: "It acts as a central home for agent interaction, allowing you to orchestrate multiple agents to execute tasks in parallel."4 To demonstrate the architecture, the Antigravity team ran 93 subagents from a single prompt to build a functional OS capable of running FreeDoom — 15,314 model calls, 2.6B+ tokens, $916.92 in API costs.5
The platform bet landed with friction. Developers who upgraded to Antigravity 2.0 found their code editor had vanished: Google split the IDE and the agent platform into two separate installs without clearly communicating the change. The Google AI Developers Forum saw a wave of complaints.6 Forum responses described the update as prioritizing "flashy AI agent hype over actual usability." That tension — building an agent-native surface versus embedding agents in an existing workflow — is not a Google-specific problem. It's the same architectural fork every product team faces.
Three decisions this week's signals clarify
Decision 1: Measure orchestration, not just output.
If you're running or evaluating a multi-agent system, output quality scores are not enough. DecisionBench shows that four different orchestration configurations can produce identical average quality scores while operating at radically different routing fidelities.2 Routing fidelity — the rate at which your orchestrator correctly assigns tasks to the agents best equipped to handle them — needs to be a tracked metric in your eval harness. If you can't measure it today, start by auditing where task failures originate: model error, or routing error? AgentNLQ offers one concrete technique: separate static context from dynamic reasoning context so the orchestrator stops re-processing the same schema information on every query.1
Decision 2: Treat trust as an architectural property, not a compliance layer.
If your product routes tasks across third-party agents, or allows agents to spawn subagents dynamically, the Trustworthy Agent Network paper's warning applies directly.3 Bolted-on trust fails when a malicious input cascades through a chain of otherwise legitimate agents and triggers harmful behavior at a privileged node — and guardrails can't intercept what they weren't designed to see. For most product teams, "baked-in trust" as formally defined isn't achievable today. The practical checkpoint before you connect any third-party agent: define what system states that connection can reach, and verify that none of them are unrecoverable. Don't assume a human approval step closes the loop.
Decision 3: Decide whether you're building an agent surface or embedding agents in your current surface.
Freddy Montes, who runs an AI-native product consultancy, observed on X this week that Google, Cursor, and GitHub all moved their AI tools out of the traditional editor in the same three-week window.7 GitHub said directly that it's building "Agent HQ" — a panel to orchestrate Anthropic, OpenAI, and Google agents under a single subscription.7 The platform companies are betting on agent-native surfaces. Antigravity's community response shows the cost of that bet when the migration is imposed on users rather than offered to them.
Santiago (@svpino, 451K followers), a computer scientist who teaches AI/ML engineering, has argued the microservices analogy holds here: multi-agent has its place, but it shouldn't be the default design pattern.8 "Not everything should be an agent. Most of the time, when you think you need to build an agent, you don't."8 The practical test: if your use case genuinely requires parallel specialization across distinct capability domains, multi-agent earns its overhead. If a reliable sequential function solves it, adding orchestration complexity increases cost and latency with no quality return.
The framework landscape has consolidated around four options this year, each with a distinct production tradeoff:910
| Framework | Architecture style | Best for | Known risk |
|---|---|---|---|
| LangGraph | Directed cyclic graph, conditional edges | Production with observability requirements | Higher engineering overhead |
| CrewAI | Role-based agent teams | Rapid prototyping | No hard exit conditions → runaway cost |
| Microsoft Agent Framework 1.0 | Unified A2A (agent-to-agent) + MCP (model context protocol) | .NET / Azure shops | New GA (April 3, 2026); limited production track record |
| Google ADK 2.0 | Unified graph engine, A2A native | Google Cloud / Gemini-centered stacks | Tight platform coupling |
One consistent practitioner finding: domain logic is the only layer in the stack where building beats buying, because competitors can license the same orchestration vendor you use.9 The competitive question isn't which orchestration framework you pick. It's what your agents actually do.
TL;DR
- The research signal: Three arXiv papers on May 18 converge on the same conclusion — orchestration architecture is the primary performance variable. A well-designed orchestration layer closes a 15–31pp gap vs. naive routing (DecisionBench), and cuts latency 92% vs. a monolith orchestrator without changing the model (AgentNLQ, JPMC)21
- The product signal: Google's Antigravity 2.0 confirms the platform bet on agent-native surfaces; the community backlash confirms how much friction the embed-vs-standalone tradeoff generates when users aren't given a choice4
- The trust signal: Connecting third-party agents introduces failure modes that post-hoc guardrails cannot close — trust requires constraints at the state transition level3
- The move: Add routing fidelity to your eval harness; separate static context from dynamic reasoning in your orchestration layer; answer the embed-vs-agent-native question before your users answer it for you
Cover image from: Google Cloud Blog: I/O '26 news for agent developers on Google Cloud
References
- 1arXiv: AgentNLQ (2605.19010)
- 2arXiv: DecisionBench (2605.19099)
- 3arXiv: Trustworthy Agent Network (2605.19035)
- 4Google Blog: I/O 2026 developer highlights
- 5Antigravity Blog: Google Antigravity Built an OS
- 6Google AI Developers Forum: Antigravity 2.0 backlash
- 7Freddy Montes (@fmontes) on X
- 8Santiago (@svpino) on X
- 9AugmentCode: 7 Multi-Agent Orchestration Platforms: Build vs Buy in 2026
- 10Microsoft Tech Community: Inside Microsoft Agent Framework 1.0
Add more perspectives or context around this Drop.