
www.assemblyai.com
AssemblyAI Voice Agent API: One unified pipeline for real-time voice applications
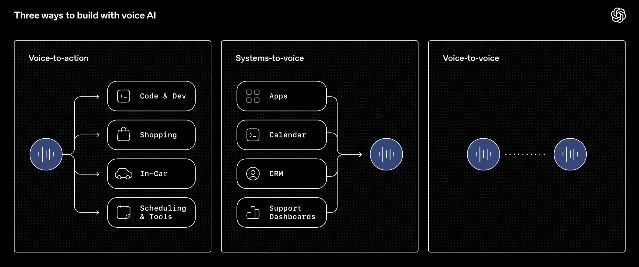
AssemblyAI's new Voice Agent API collapses the STT + LLM + TTS pipeline into a single managed endpoint, with sub-300ms round-trip latency in production benchmarks.
Add more perspectives or context around this Drop.