
今日 HuggingFace 论文速递|推理加速进入精细化时代(2026-06-02)
今日 Trending 最热主题是大模型推理加速:Domino 把因果建模与自回归草稿生成解耦,Qwen3 上跑出 5.8 倍吞吐加速;Draft-OPD 让草稿模型在「真实错误状态」下学习,超越 EAGLE-3 达到 5x+ 无损加速。另有 PEFT 个人化新范式、Agent 基准自动生成方法 TASTE,以及 AI 科研图表生成框架 Crafter。

Research Brief
今日 HuggingFace Trending 有一个藏不住的主题:怎样让大模型跑得更快。排名前十中有三篇论文都在研究「推理加速」,而且给出的加速倍数都不含糊——5 倍起步。与此同时,有两篇反方向的工作在问:我们当下评测 AI 智能体的标准,够不够用?
Domino:把「思考」和「起草」拆开,推理速度提升 5.8 倍
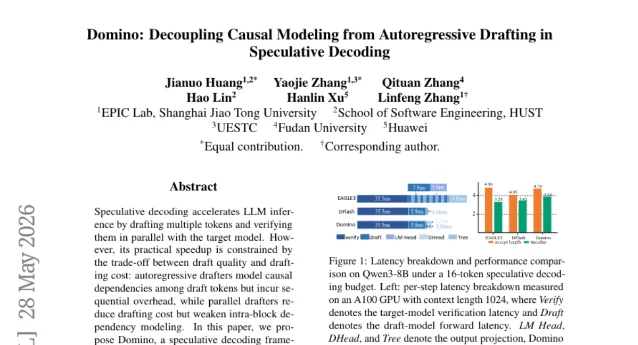
论文:Domino: Decoupling Causal Modeling from Autoregressive Drafting in Speculative Decoding 1
机构:上海交通大学 · 预印本
先解释一下背景:大模型生成文字是逐词输出的,每生成一个词都要跑一遍整个模型。「投机解码(Speculative Decoding)」是目前主流的加速方案——用一个小模型提前猜测接下来的几个词,再让大模型一次性验证,猜对了就直接省掉多轮计算,猜错了再回来补。
问题在于:这个「猜词的小模型」很难两全其美。
- 自回归方式(每个词依赖上一个词):猜的质量高,但猜词本身很慢,因为没法并行。
- 并行方式(所有词同时猜):速度快,但每个词互相不知道对方是什么,猜的质量下降。
Domino 的思路是:把两件事分开做。先用并行方式快速生成一批候选词,再用一个轻量级「Domino 头」把前文因果信息打进去修正。训练时还设计了「基锚定课程」——先让并行主干练扎实,再慢慢把优化重心转向修正后的结果,避免两步互相打架。
在 Qwen3 模型上的测试:Transformers 后端下端到端加速最高 5.49 倍,SGLang 服务下吞吐量加速最高 5.8 倍1。
Draft-OPD:训练草稿模型时,让它练「自己会犯的错」
论文:Draft-OPD: On-Policy Distillation for Speculative Draft Models 2
机构:未完整披露 · 预印本
同样是投机解码,Draft-OPD 解决的是另一个问题:草稿模型的训练方式。
现在主流的做法(包括知名方案 EAGLE-3)是「监督微调(SFT)」——把大模型生成的内容当标准答案喂给小模型。但研究者发现,这样训练的模型提升很快会遇到天花板:训练数据和实际跑推理时的情况不一样。训练时小模型学的是「大模型的标准输出」,但实际推理时小模型是在自己之前的猜测基础上继续猜,两种情境的误差会越积越大。
Draft-OPD 的解法:让小模型在「真实推理状态」下训练。具体步骤是:先用大模型辅助生成一段稳定的上下文,然后专门让小模型重跑那些「被大模型判错」的位置,在错误点上学习大模型的反馈。
结果:在 thinking 类大模型(即推理链类模型)上超过 5 倍无损加速,比 EAGLE-3 提升 23%,比 DFlash 提升 13%2。
这两篇投机解码论文一起来看,释放的信号是:加速研究已经进入「精细化工程」阶段,粗暴堆规模的思路边际效益在降,针对训练错位、因果建模不足的精细修补开始占主导。
PEFT 的新角色:不只是省钱微调,而是「人人一个私人大模型」
论文:On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters 3
机构:Mind Lab · 预印本(6 月 1 日发布)
PEFT(参数高效微调)大家都知道——LoRA 是它最出名的实现,意思是训练时不动大模型的全部参数,只在外面加一小块「补丁」,省显存、省算力。
这篇论文问了一个不一样的问题:PEFT 的意义是不是被低估了?
作者认为,PEFT 不应该只被看作「全量微调的廉价替代品」,而应该被当成一种存储个人习惯、偏好、技能的「持久化载体」。想象一下:底层大模型是所有人共享的通用能力基座,每个人在上面挂一个属于自己的小适配器,记着你的写作风格、常用工具习惯、历史交互记忆——这样就成了「百万级别的私人模型」。
论文围绕三个维度展开:底层模型越强,上面小适配器的收益越大(Scale Up);适配器可以做到多小同时还可靠(Scale Down);大量私人适配器如何共存和管理(Scale Out),并为此提供了一个基础设施示例 MinT。
这是一篇观点驱动的工作,量化实验细节有限,更像是对一个系统方向的论证。AI 从业者关注的价值在于:这种「一基座 + 海量个人适配器」的架构思路,可能会深刻改变模型服务和个人化产品的设计逻辑3。
TASTE:让 AI 智能体测试题「越出越难」

论文:A Matter of TASTE: Improving Coverage and Difficulty of Agent Benchmarks 4
机构:以色列理工学院(Technion) · 预印本
AI 智能体(Agent)领域一个越来越尴尬的问题:模型在基准上分数越来越高,但这只是因为基准太容易了,还是模型真的能干活了?
以 τ²-Bench 为例,它是目前常用的智能体评测数据集,覆盖几个服务行业场景(比如航空、零售等订单处理)。论文测试发现,Gemini-3-Flash 在这个数据集上准确率可以达到 0.82—0.94——接近饱和。
TASTE 提出了一种反向构造思路:不是先想好场景再找工具,而是先决定「需要调用哪些工具的组合」,再据此生成一个合理的任务。这样生成的题目天然覆盖更多工具组合,也更难绕过。
用这种方法生成的新数据集 τ^c-Bench 上,Gemini-3-Flash 的准确率直接掉到了 0.28—0.614。独特工具组合数量也翻了一倍以上。
对于做智能体评测或产品测试的从业者来说,这篇论文的实际意义不小:现有高分可能只反映「基准被刷了」,而不是「智能体真的能搞定复杂任务」。
Crafter:让 AI 生成的科研图表变成可以改的 SVG

论文:Crafter: A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs 5
机构:未完整披露(代码已开源) · 预印本
科研图表(流程图、实验结果图、架构图)的制作是论文写作中最耗时的环节之一。现有的 AI 自动生成工具都有一个问题:只能处理纯文字输入、只支持特定图表类型、输出的是不能再编辑的位图(PNG/JPG)。
Crafter 想做成一个「通吃各种图、输出可编辑文件」的框架。它的核心思路是把图表拆解为若干离散的语义组件,用多个智能体分别处理——因为局部错误(某个箭头画错、某个标注位置偏)不需要重新生成整张图,只需要修正出错的那个组件。
同期发布的 CraftEditor 则用同样的思路把已有的位图图表转换成可编辑的 SVG 格式。作者同时建立了 CraftBench 评测基准,覆盖三类图表、四种输入条件,有人工质量标注。
实验显示 Crafter 在 CraftBench 和 PaperBanana-Bench 上都优于独立生成模型和智能体基线,CraftEditor 转换出的 SVG 质量也超过所有对比方法5。代码和基准已在 GitHub 开源。
今日关键词
| 论文 | 方向 | 状态 |
|---|---|---|
| Domino | 推理加速(投机解码架构) | 预印本 |
| Draft-OPD | 推理加速(草稿模型训练) | 预印本 |
| PEFT Scaling | 模型个人化 / 适配器基础设施 | 预印本 |
| TASTE | 智能体基准自动生成 | 预印本 |
| Crafter | 科研图表自动生成 + 可编辑输出 | 预印本 |
Add more perspectives or context around this Post.