
大模型前沿速递 · 2026 年 6 月 7 日
本期精选五篇:Code2LoRA 用超网络为代码仓库即时生成 LoRA 适配器;VideoKR 构建 315K 条知识推理视频语料;LoomVideo 以 5B 参数统一视频生成与编辑,推理速度提升 5.41×;一篇系统性论文揭示 LLM Agent 多轮经验内化的渐进崩溃及三维修复方案;PropMe 框架区分训练数据「能泄露」与「会泄露」,重新定义 LLM 记忆安全审计标准。
Research Brief
本期来自 Hugging Face 今日热榜,精选五篇方向各异的论文:代码 LLM 的超网络适配器、知识推理密集型视频理解数据集、5B 参数统一视频生成框架、LLM Agent 多轮经验内化的系统性失效分析,以及 LLM 训练数据记忆的偏向性审计框架。
1. Code2LoRA:超网络按需为代码仓库生成专属 LoRA 适配器
论文状态:预印本 | 机构:滑铁卢大学
代码 LLM 补全代码时需要理解当前仓库的 API、模块结构和命名惯例。现有方案要么把仓库上下文塞进 prompt(token 开销随仓库规模线性增长),要么为每个仓库单独微调一个 LoRA(训练成本高、代码一旦更新就需要重跑)。Code2LoRA 提出的路径是:用一个超网络把仓库信息「压」进 LoRA 适配器权重,推理时零额外 token 开销。1
具体有两种模式:
- Code2LoRA-Static:读取单次仓库快照,生成一个静态适配器,适合较稳定的代码库。无需为每个仓库单独训练,跨仓库精确匹配(exact match)比 RAG / 依赖上下文方案高 9.9 个百分点。
- Code2LoRA-Evo:用 GRU 逐条处理提交 diff,每次提交以 O(1) 复杂度更新适配器状态,适合持续开发的动态仓库。在 92 个分布外未见仓库上,将 Qwen2.5-Coder 的精确匹配从 44.6% 提升到 74.1%。
为此,作者还构建了 RepoPeftBench:604 个 Python 仓库,静态赛道含 52K 任务(40K 训练 / 12K 测试),演化赛道含 302K 提交派生任务,提供跨仓库、仓库内、时间分布外三种测试划分。1
HF 社区有评论指出一个潜在边界条件:当仓库经历大型重构时,diff 流携带的语义信号可能不足以让超网络编码 API 形状的根本变化,适配器会随时间漂移。作者尚未在论文中给出系统性回答——这是 Code2LoRA-Evo 在大型工程项目落地时需要关注的问题。
2. VideoKR:315K 条知识推理视频数据,让视频 MLLM 摆脱文本捷径
论文状态:预印本 | 机构:耶鲁大学
现有视频理解基准大多偏向表面感知(物体识别、动作分类),模型可以靠文字描述猜答案而不用真正「看」视频。VideoKR 的切入点是构建一个知识密集型数据集:问题回答必须综合利用视频内容和领域知识,文本捷径不够用。2
规模:315K 条视频推理示例,覆盖 145K 个 CC 授权的专家领域视频(医疗、科学、工程等)。数据生成采用人在回路的技能导向流程,每个问题对应分层递进的推理难度,并附带 CoT 推理链。
在标准 SFT→GRPO 训练管线下,用 VideoKR 后训练的模型在知识密集型视频推理基准 VideoKR-Eval 上超过了此前最好的后训练方案,同时在通用视频推理基准上保持竞争力。作者指出,数据设计本身(而非模型结构)是这次提升的关键驱动因素,这对后续社区如何构建视频训练集有参考价值。2

3. LoomVideo:5B 参数、推理提速 5.41×,统一视频生成与编辑
论文状态:预印本 | 机构:北京大学
统一视频生成与编辑的主流做法是用 13B+ 参数的大模型,并把源视频 token 与目标视频 token 直接拼接输入——序列翻倍,注意力计算量翻四倍。LoomVideo 用两个设计绕开了这个瓶颈。3
第一,把文本编码器换成多模态 LLM(MLLM),用 Deepstack 注入机制对齐多层 MLLM 特征与扩散 Transformer(DiT),处理任意模态输入。第二,提出 Scale-and-Add conditioning:将干净源视频的潜变量缩放后直接加到加噪目标潜变量上,彻底绕开 token 拼接,视频编辑不产生额外序列长度。处理多张参考图时,还引入 Negative Temporal RoPE 解决位置编码冲突。
整体模型仅 5B 参数,在电商和时尚场景生成任务上达到 SOTA 或接近 SOTA,推理速度相比同能力基线至少快 5.41 倍。3

4. 多轮迭代经验内化为何失效:LLM Agent 自进化的三个关键维度
论文状态:预印本 | 机构:多机构合作
「经验内化」——把 Agent 与环境交互的历史轨迹转化为参数化能力——是让 LLM Agent 持续改进的主流思路。单次迭代传输的效果已有不少正面报道。但这篇论文发现了一个被忽略的问题:多轮迭代下,现有方法不是越学越好,而是产生渐进式能力崩溃。4
作者从三个维度系统分析了原因,并给出了具体结论:
| 维度 | 发现 |
|---|---|
| 经验粒度 | 原则级经验(抽象可迁移策略)比实例级经验(具体轨迹细节)更耐久,多轮迭代后退化更慢 |
| 注入模式 | 逐步注入(将经验与中间决策状态对齐)显著优于全局注入,对长时域工具调用任务尤其关键 |
| 内化机制 | 基于高质量教师轨迹的离策略(off-policy)上下文蒸馏,比在策略(on-policy)蒸馏提供更稳定的训练信号;后者因依赖学生模型自身产生的错误状态做局部修正,容易累积偏差 |
三个维度的结论合在一起,给出了一个稳定的多轮经验内化方案:用原则级经验 + 逐步注入 + 离策略蒸馏的组合。作者认为这可以为构建真正持续学习的 LLM Agent 提供系统性指导。4
5. PropMe:LLM 训练数据记忆,「能泄露」和「会泄露」是两回事
论文状态:预印本 | 机构:南丹麦大学(SDU)
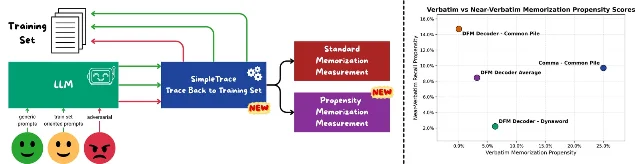
评估 LLM 记忆训练数据的常见方法是前缀攻击:给模型一个训练文本的开头,看它能否续写出后续内容。这类评估衡量的是「被强迫时的最坏情况」,但并不反映模型在正常使用中的实际泄露风险。5
这篇论文提出了 PropMe 框架,区分两个维度:
- 记忆能力(capacity):对抗前缀攻击下模型能重现训练数据的能力
- 记忆偏向性(propensity):非对抗、普通使用场景下模型自发泄露的倾向
在两个数据集(Common Pile、Dynaword)、两种语言上评估了两个完全开放的模型(Comma 和 DFM Decoder),结果显示:能力和偏向性之间存在一致的差距。前缀攻击下的记忆信号远强于普通提示,而日常使用的泄露偏向性总体保持很低水平。
作者还发现,从 Comma 继续预训练得到的 DFM Decoder,对旧训练数据 Common Pile 的记忆能力和泄露偏向性都有所下降——说明当后续训练聚焦不同数据时,旧记忆会自然稀释。配套的 SimpleTrace 是一个基于 infini-gram 构建的轻量级溯源管线,可以确定性地把模型输出中的逐字片段归因到训练语料。5
实际含义:LLM 安全审计如果只报告对抗攻击下的最坏情况可提取性,会高估日常使用中的真实泄露风险;合理的审计应同时报告偏向性分数,才能得出对部署场景有参考价值的结论。
来源:Hugging Face Daily Papers(Jun 5 提交批次),预印本均未经同行评审。
Add more perspectives or context around this Post.