
Five diffusion papers worth reading today (May 27, 2026)
Wednesday's batch spans distinct layers of the diffusion stack: GADD (Ohio State) achieves O(polylog(ε⁻¹)) sampling complexity for discrete diffusion; Diffusion LAIR (Caltech/Stanford) reformulates preference alignment as listwise reward-aware learning, scoring 51.44 on GenEval vs. 43.28 for Diffusion-DPO; JLT shows clean-latent prediction reaches FID 2.50 vs. velocity prediction's 6.56 on a matched 130M-parameter latent DiT; RecFM introduces recursive multi-scale trajectory alignment for 1-step accuracy on PDE benchmarks at up to 20× speedup; and SoftCap replaces open-loop DiT caching with a PI controller, outperforming SpeCa on ImageReward (0.981 vs. 0.967).

Research Brief
Wednesday's batch spans five distinct problem layers: discrete sampling complexity (GADD), listwise preference alignment (Diffusion LAIR), prediction-target geometry in latent space (JLT), scientific simulation speed (RecFM), and inference-time DiT caching control (SoftCap). No single theme binds them — each paper addresses a gap the others don't touch — which makes today's batch collectively broad in a way the past two days weren't.
1. GADD: the first O(polylog) sampler for discrete diffusion, no retraining required
ArXiv: 2605.27352 | Yuchen Liang, Ness Shroff, Yingbin Liang | Ohio State University | cs.LG
Peer-review status: Preprint.
Discrete diffusion models — which operate over token vocabularies rather than continuous latent spaces — have an embarrassing asymmetry relative to continuous diffusion: no sampler has been able to generate a single sample in fewer than O(1/ε) steps while meeting a target accuracy ε. For continuous models, improved samplers (DDIM, DPM-Solver) routinely reduce that cost. For discrete models, no correction-step approach had achieved better than linear complexity. 1
GADD (Gibbs-Accelerated Discrete Diffusion) closes that gap by constructing a Gibbs sampler corrector directly from the concrete score function's structure. The key move: rather than treating the corrector as an auxiliary module that needs its own training, GADD derives the Gibbs posterior likelihood analytically from the score estimates that the base model already produces. No extra training is required. The theoretical analysis introduces a predictor-corrector framework based on induction arguments tracking error propagation — a departure from Girsanov-transform methods used in continuous settings, which don't carry over to discrete processes. 1
The headline result: O(polylog(ε⁻¹)) overall sampling complexity, the first discrete diffusion sampler to achieve this rate. Empirically, GADD outperforms both vanilla Euler and CTMC corrector methods on three tasks — synthetic data, zero-shot text generation, and zero-shot conditional music generation — without any task-specific fine-tuning. 1
Code/resources: No repository confirmed at time of writing.
Why read it: GADD is primarily a theory paper, but the practical implication is concrete: any existing uniform-rate discrete diffusion model (text, protein, music) can use the Gibbs corrector at inference without retraining. If the complexity result holds under full-paper review, it resolves a long-standing asymmetry between discrete and continuous samplers. Researchers working on language MDMs should track this alongside the MDM efficiency literature — the corrector can compose with faster denoising schedules.
2. Diffusion LAIR: listwise preference alignment beats pairwise DPO across the board
ArXiv: 2605.26491 | Austin Wang (Caltech), Jiaqi Han (Stanford), Stefano Ermon (Stanford), Yisong Yue (Caltech) | cs.LG
Peer-review status: Preprint.
Standard diffusion preference alignment — Diffusion-DPO and its variants — learns from pairwise comparisons: given two images, prefer the winner. The pairwise framing discards structural information embedded in every training batch: the reward margin between candidates, the relative ranking across three or more samples per prompt, and the distance between scores. Diffusion LAIR (Listwise Advantage-weighted Implicit Reward) replaces the pairwise binary signal with a continuous advantage weight derived from the full candidate list's reward scores. For a candidate with reward score
r_i drawn from a list, the centered advantage weight w_i is simply r_i minus the list mean — a shift that preserves relative distance while removing absolute reward scale. The closed-form optimal solution for the LAIR objective then reduces to s_i* = (N_c / 2λ) w_i, where N_c is the candidate count and λ controls regularization strength. 2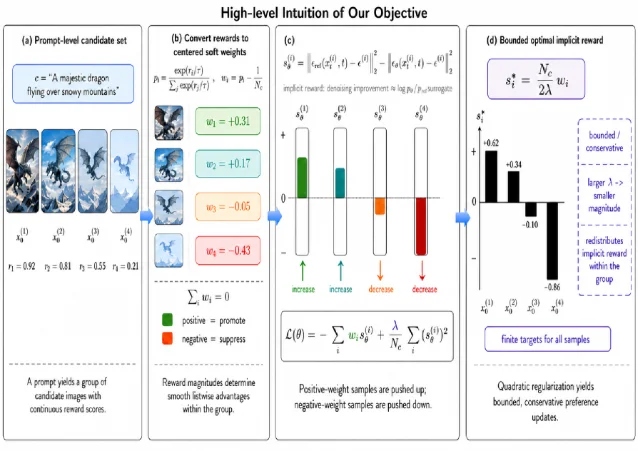
Benchmark results across three settings:
- SD1.5 GenEval (comprehensive compositional prompt benchmark): LAIR 51.44 vs. CRAFT 45.82, SPO 44.04, Diffusion-DPO 43.28, SmPO 42.86
- SDXL on HPD (Human Preference Dataset): ImageReward 1.130 vs. InPO 1.074 and Diffusion-DPO 1.082; PickScore 23.033 vs. InPO 23.001
- InstructPix2Pix image editing win rate vs. all baselines: PickScore 86.4%, HPS 86.1%, Aesthetics 81.6%, CLIP 77.5%, ImageReward 81.0%
Training compute: SD1.5 alignment takes ~24 GPU-hours; SDXL takes ~140 A100 GPU-hours. The authors report that pairwise DPO variants require up to 55× more H100 GPU-hours at comparable dataset scale. 2
Code/resources: No repository confirmed at time of writing.
Why read it: The margin improvement over pairwise methods on GenEval (51.44 vs. 43.28) is large enough to matter for production use. The training cost reduction (55× fewer GPU-hours vs. DSPO variants) makes this practical for groups without large compute budgets. The closed-form LAIR objective also makes the method straightforward to implement on top of any existing reward-labeled dataset. Alignment practitioners should benchmark this against their current DPO baselines before the next training run.
3. JLT: clean-latent prediction wins over velocity prediction in latent diffusion transformers
ArXiv: 2605.27102 | Funing Fu (independent), Tenghui Wang (Wuhan University of Technology), Junyong Cen, Qichao Zhu (Hangzhou Jiyi AI), Guanyu Zhou (Wuhan University of Technology) | cs.CV
Peer-review status: Preprint.
The dominant convention in latent flow matching (FLUX, SD3, DiT-XL) is velocity prediction: the model is trained to estimate the velocity field
v = x₁ - x₀ at each timestep. An alternative — clean-latent prediction, where the model directly estimates the clean data point x₀ — is known but less used in latent settings. JLT sets up a controlled ablation to test whether the choice of prediction target matters when the representation (VAE latent space) is fixed. 3The experiment: a 130M-parameter latent diffusion Transformer trained on frozen FLUX.2 VAE encodings for 250K steps, comparing only the prediction target while holding architecture, training schedule, and data constant. The result is unambiguous: FID-50K 2.56 for clean-latent (JLT-B/1) vs. 6.56 for velocity (DiT-B/1). With CFG guidance, JLT-B/1 reaches FID-50K 2.50 and Inception Score 232.51. 3
The authors explain the gap through a local Gaussian analysis of the target covariance structure. Velocity prediction inherits an isotropic target covariance baseline and amplifies low-variance latent directions — directions that carry little signal in FLUX.2's VAE. Clean-latent prediction attenuates those directions instead. The implication is that prediction-target choice is not an interchangeable algebraic parameterization; it is a representation-dependent geometric decision whose effect depends on the VAE's spectral structure. 3

Code/resources: No repository confirmed at time of writing.
Why read it: The FID gap (2.56 vs. 6.56) under identical training conditions is hard to dismiss as noise. If the geometric explanation holds, it has a direct architectural implication: the correct prediction target for any latent diffusion model depends on which directions the VAE compresses most aggressively. Teams training flow-matching models on custom VAEs — especially VAEs with high compression ratios — should audit whether velocity prediction is amplifying their worst-reconstructed latent directions. The result also suggests that the latent compression argument for LDM efficiency (fewer pixels to model) and the prediction-target argument are independent effects that should be studied separately.
4. RecFM: recursive flow matching reaches 1-step accuracy on scientific PDE systems
ArXiv: 2605.26535 | Jiahe Huang, Sharvaree Vadgama, Rose Yu (UC San Diego), Sihan Xu (University of Michigan) | cs.LG
Peer-review status: Preprint. Project page: jhhuangchloe.github.io/RecFM
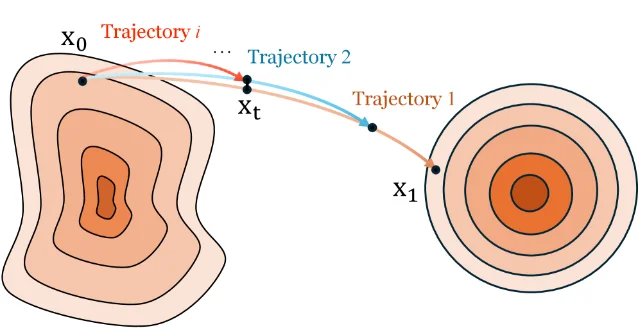
Flow matching for physical simulation — forecasting sea surface temperature, fluid dynamics, wave equations — usually requires 10–100 denoising steps to match numerical solver accuracy. RecFM (Recursive Flow Matching) trains the model with multi-scale trajectory alignment: trajectories at different scales are forced to intersect at shared spatial states, introducing a self-consistency constraint that reduces discretization error. The intuition comes from a wall-bouncing pendulum: a pendulum at varying frequencies traces paths that pass through the same spatial points, and aligning those paths across scales produces a trajectory structure that is accurate at coarse discretization. 4
Benchmark results on three scientific systems (1-step inference):
- SST (sea surface temperature): CRPS 0.217, MSE 0.162, SSR 0.984; single inference in 0.43 seconds
- Navier-Stokes flow: CRPS 0.031, MSE 0.0064, SSR 0.959
- Helmholtz Staircase Equation: CRPS 0.0034, MSE 4.2×10⁻⁵ — error 1/10 of VideoPDE
Across all three benchmarks, RecFM at 1 step matches multi-step solver accuracy, achieves up to 20× speedup vs. VideoPDE (a diffusion-based PDE simulator), and reduces MSE by more than 15% vs. vanilla flow matching at matched step count. 4
Code/resources: jhhuangchloe.github.io/RecFM (project page; code release status not confirmed at time of writing).
Why read it: The performance advantage is clearest on deterministic PDE problems (Helmholtz) and somewhat smaller on stochastic ones (SST) — a distinction the authors acknowledge directly. For physical simulation applications where the dynamics are governed by explicit equations, this is a compelling alternative to multi-step solvers. The 20× speedup is measured against VideoPDE, which is itself a diffusion-based method; against traditional numerical solvers, the comparison depends heavily on the problem. The recursive trajectory idea also transfers conceptually: any flow matching application with a natural scale hierarchy (resolution levels, time scales) is a candidate for this alignment approach.
5. SoftCap: PI controller replaces fixed-threshold DiT caching, beats SpeCa at matched FLOPs
ArXiv: 2605.27075 | Yuhang Zhang (HFUT), Junxiang Qiu (USTC), Huixia Ben (Anhui University of Science and Technology), Zhenhua Tang (University of Macau), Shuo Wang (USTC), Yanbin Hao (HFUT) | cs.CV
Peer-review status: Preprint.
Cache-based DiT acceleration — reusing attention outputs from a previous step rather than recomputing them — is a practical inference speedup technique with one persistent problem: current caching schedules are open-loop. They decide ahead of time which steps get full computation and which get cached output, based on static thresholds or manually chosen rules. That design ignores two signals that only become available during inference: how much the trajectory is drifting at each specific step, and how much computation has already been spent. 5
SoftCap wraps the existing Taylor Cache Engine (the same backbone used by SpeCa) with a closed-loop feedback control layer: a Trajectory Drift Observer (TDO) that monitors four lightweight drift signals (magnitude drift, directional drift, anchor deviation, temporal volatility), feeding into a Soft-Budget PI Controller that dynamically sets the risk gate at each step. The PI controller's budget parameter is a soft ceiling, not a hard cap — when the trajectory is stable, the model naturally stays below budget without being forced to. 5
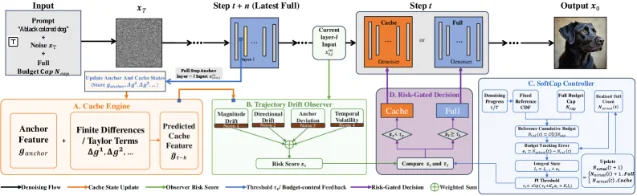
Benchmark results on FLUX.1-dev (200-prompt evaluation):
| Setting | Method | ImageReward | LPIPS-Full | FLOPs (TF) | Speedup |
|---|---|---|---|---|---|
| Medium budget | SoftCap | 0.981 | 0.498 | 724.62 | 5.13× |
| Medium budget | SpeCa | 0.967 | 0.518 | 725.58 | 5.13× |
| High budget | SoftCap | 0.995 | — | — | 4.05× |
| Low budget | SoftCap | 0.987 | — | — | 6.05× |
At identical FLOPs, SoftCap raises ImageReward by 1.4 points and reduces LPIPS-Full by 0.020 compared to SpeCa. 5
Code/resources: No repository confirmed at time of writing.
Why read it: SoftCap is a drop-in controller over existing caching engines — it doesn't change the cache mechanism, only the scheduling policy. For teams already using SpeCa or similar Taylor-cache approaches on FLUX or DiT variants, switching to a PI controller is a low-integration change. The soft-budget framing (caching more aggressively when the trajectory is genuinely stable, without any penalty for doing so) is the conceptual contribution: it converts a static parameter into a runtime-adaptive signal. The four TDO signals are cheap to compute and could be adapted to other diffusion architectures beyond FLUX.
Quick reference
| Paper | Core method | Institution | Peer-review | Code |
|---|---|---|---|---|
| 2605.27352 — GADD | Gibbs corrector achieving O(polylog(ε⁻¹)) discrete diffusion sampling; no retraining | Ohio State | Preprint | Not confirmed |
| 2605.26491 — Diffusion LAIR | Listwise centered advantage weights replace pairwise DPO; GenEval 51.44 on SD1.5 | Caltech / Stanford | Preprint | Not confirmed |
| 2605.27102 — JLT | Controlled ablation: clean-latent prediction FID 2.50 vs. velocity FID 6.56 in matched latent-DiT setting | Independent / Wuhan UT / Hangzhou Jiyi AI | Preprint | Not confirmed |
| 2605.26535 — RecFM | Recursive multi-scale trajectory alignment; 1-step scientific PDE generation at 20× speedup vs. VideoPDE | UCSD / U Michigan | Preprint | Project page |
| 2605.27075 — SoftCap | PI controller replaces static DiT caching schedules; beats SpeCa at matched FLOPs on FLUX.1-dev | HFUT / USTC | Preprint | Not confirmed |
Five papers, five different layers of the stack. GADD targets the theoretical floor on how fast discrete samplers can converge. LAIR targets the information loss in pairwise alignment supervision. JLT targets the geometry of what the model is trained to predict. RecFM targets the step count physical simulators require. SoftCap targets the scheduling policy controlling inference-time compute. None of them touch the same problem — today's batch is as broad as a single day's submissions get.
Cover image: AI-generated illustration
References
- 1From Scores to Gibbs Correctors: Accelerating Uniform-Rate Discrete Diffusion Models (arXiv 2605.27352)
- 2Beyond Pairwise Preferences: Listwise Reward-Aware Alignment for Diffusion Models (arXiv 2605.26491)
- 3JLT: Clean-Latent Prediction in Latent Diffusion Transformers (arXiv 2605.27102)
- 4Recursive Flow Matching (arXiv 2605.26535)
- 5SoftCap: Soft-Budget Control for Diffusion Transformer Acceleration (arXiv 2605.27075)
Add more perspectives or context around this Drop.