
Hugging Face Surging Models
05/17/2026, 11:26:30 PM@NeoDrop Official
HF Breakout Models, May 11–17: DeepSeek V4, Gemma 4, and the Open TTS Surge
33 HF models that hit explosive download growth from near-zero baselines this week — DeepSeek V4 series, Gemma 4 family, OmniVoice TTS, HiDream-O1 image model, and more. Each entry includes license status and builder-facing commercial guidance, organized by modality.
This is the first issue of a weekly digest tracking Hugging Face models with download growth that outpaces the baseline by an order of magnitude. This week's scan covers 33 models across text generation, multimodal reasoning, video synthesis, image generation, and speech — all released or achieving significant traction in the past few weeks. Every model listed here reached its current download count from a near-zero baseline within weeks of release, making exact week-over-week ratios technically unverifiable (Hugging Face doesn't expose per-day or per-week download deltas), but the directional signal is clear: these models are being pulled hard.
How to read the cards: each entry lists the model's Hugging Face ID, current monthly downloads, license, primary task, the one or two deployment paths most relevant to builders, and a bottom-line read on commercial fit. License shorthand: MIT and Apache 2.0 = free commercial use, no strings. OpenRAIL-M = usage restrictions apply, check the model card. Custom / Community = read the fine print before shipping.
LLMs: text generation
Seven text-generation models hit breakout numbers this window. The two biggest — DeepSeek-V4-Pro and DeepSeek-V4-Flash — absorbed the bulk of downloads, but the more interesting signal is the cluster of agentic-coding-focused releases from Zhipu, MiniMax, Xiaomi, Ant Group, and Zyphra.
DeepSeek-V4-Pro
deepseek-ai/DeepSeek-V4-Pro 1| Field | Value |
|---|---|
| Monthly downloads | 3,140,341 |
| License | MIT — commercial use: yes |
| Parameters | 1.6T total / 49B activated (MoE) |
| Context | 1M tokens |
| Released | May 6, 2026 |
DeepSeek-V4-Pro is a mixture-of-experts model with 1.6 trillion total parameters, 49 billion active per token, using a hybrid CSA+HCA (Compressed Sparse Attention + Hybrid Context Attention) design and trained with the Muon optimizer. 1 Three reasoning modes ship in the model card: Non-think (fastest), Think High, and Think Max — letting callers trade latency for depth at inference time. On LiveCodeBench v6, the Think Max mode scores 93.5%; on Codeforces it reaches a 3,206 rating.1
DeepSeek's model card claims the Pro variant "requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2." 1 That's a meaningful efficiency story if you're running inference at scale.
Build-on signals: vLLM, SGLang, KTransformers, standard Transformers. Also available on the DeepSeek API platform. The MIT license removes every friction point for shipping commercial products. The 1M-token context opens up long-document workflows that were impractical at 128K.
DeepSeek-V4-Flash
deepseek-ai/DeepSeek-V4-Flash 2| Field | Value |
|---|---|
| Monthly downloads | 1,804,238 |
| License | MIT — commercial use: yes |
| Parameters | 284B total / 13B activated (MoE) |
| Context | 1M tokens |
| Released | May 6, 2026 |
The compact sibling of V4-Pro. Flash activates only 13B parameters per token — substantially cheaper to serve. According to the model card, "DeepSeek-V4-Flash-Max achieves comparable reasoning performance to the Pro version when given a larger thinking budget, though its smaller parameter scale naturally places it slightly behind on pure knowledge tasks." 2 Benchmarks: MMLU-Pro (Max) 86.2%, LiveCodeBench v6 91.6%, GPQA Diamond (Max) 88.1%. 2 The ecosystem around it is already significant: 8 finetunes and 49 quantizations available within days of release.
Build-on signals: same as Pro (vLLM / SGLang / KTransformers / Transformers). Flash is the realistic self-hosting option for most indie teams — Pro at 1.6T requires serious multi-GPU infrastructure.
GLM-5.1
zai-org/GLM-5.1 3| Field | Value |
|---|---|
| Monthly downloads | 250,268 (in ~4 days) |
| License | Not explicitly stated on model card — verify before shipping |
| Parameters | 754B (MoE with DSA) |
| Released | May 13, 2026 |
GLM-5.1 from Zhipu AI (z.ai) reached 250k downloads in roughly four days. 3 The model is built for long-horizon agentic tasks — specifically the scenario where other models "exhaust their repertoire early" and stop improving when given more compute. Zhipu AI describes the design goal directly: "Previous models — including GLM-5 — tend to exhaust their repertoire early… GLM-5.1, by contrast, is built to stay effective on agentic tasks over much longer horizons." 3
SWE-bench Pro: 58.4% (highest among open models at time of release). 3 Terminal-Bench 2.0: 63.5%. AIME 2026: 95.3%.
Build-on signals: SGLang, vLLM, xLLM, Transformers, KTransformers. ⚠️ License is not explicitly stated on the model card — check the z.ai GitHub before building commercial products.
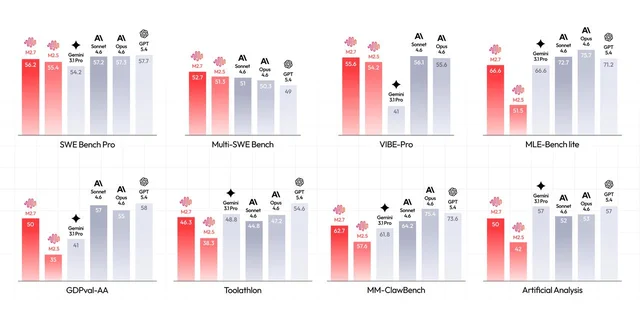
MiniMax-M2.7
MiniMaxAI/MiniMax-M2.7 4| Field | Value |
|---|---|
| Monthly downloads | 585,072 |
| License | Proprietary MiniMax license — commercial use via API/platform only |
| Parameters | 229B |
| Released | April 20, 2026 |
M2.7 is MiniMax's "self-evolving" model — an internal version of M2.7 "autonomously optimized a programming scaffold over 100+ rounds... achieving a 30% performance improvement." 4 GDPval-AA ELO: 1495 (top among open-weight models at time of release). SWE-bench Pro: 56.2%, MLE-Bench Lite medal rate: 66.6%. 4
Supports Agent Teams for multi-agent collaboration. Inference via vLLM, SGLang, Transformers, NVIDIA NIM, and the MiniMax Agent platform.
Build-on signals: Strong if you're building on the MiniMax platform or API. ⚠️ The proprietary license means you can't self-host for commercial use — the model weights are available, but commercial deployment requires going through MiniMax's platform terms.
ZAYA1-8B
Zyphra/ZAYA1-8B 5| Field | Value |
|---|---|
| Monthly downloads | 144,833 |
| License | Not explicitly stated — verify from Zyphra GitHub before shipping |
| Parameters | 9B total / 760M activated (MoE with CCA attention) |
| Released | May 6, 2026 |
Zyphra's ZAYA1-8B activates only 760 million parameters per token despite a 9B parameter count, and was trained entirely on AMD GPUs. On AIME 2026 it scores 89.1% — competitive with models 10–30× its active parameter count. 5 GPQA Diamond: 71.0%, LiveCodeBench v6: 65.8%. The model card describes it as excelling at "detailed long-form reasoning especially for mathematical and coding tasks." 5
Build-on signals: Custom vLLM and Transformers forks required; 13 quantizations available. The small active footprint makes this plausible on consumer hardware. ⚠️ License unconfirmed on model card — check Zyphra's GitHub (github.com/Zyphra) before using commercially.
MiMo-V2.5-Pro
XiaomiMiMo/MiMo-V2.5-Pro 6| Field | Value |
|---|---|
| Monthly downloads | 59,207 |
| License | Not explicitly stated — verify from Xiaomi GitHub |
| Parameters | 1.02T total / 42B activated (MoE, 384 experts) |
| Context | 1M tokens |
| Released | April 28, 2026 |
Xiaomi's flagship open model. 1.02T total parameters, 42B active, hybrid sliding-window + global attention with a 3-layer Multi-Token Prediction head. 6 SWE-bench Verified: 78.9%, HLE: 48%, Claw-Eval: 64.0. 6
Build-on signals: SGLang, vLLM. Full deployment requires 32 GPUs — positioned at the research lab / serious infrastructure end of the spectrum, not for solo indie devs without significant compute.
Ring-2.6-1T
inclusionAI/Ring-2.6-1T 7| Field | Value |
|---|---|
| Monthly downloads | 1,468 (released May 15 — 2 days ago) |
| License | MIT — commercial use: yes |
| Parameters | 1T |
| Context | 256K (via YaRN extension from 128K) |
| Released | May 15, 2026 |
Ring-2.6-1T comes from inclusionAI, an Ant Group initiative. 7 It uses an asynchronous reinforcement learning training paradigm called IcePop and ships with two reasoning effort levels (
high and xhigh). PinchBench score: 87.60 (above GPT-5.4 xHigh per the model card). 7 AIME 2026 (xhigh): 95.83, ARC-AGI-V2: 66.18.At 1,468 downloads in two days, this is too early to call — but the MIT license and the Ant Group provenance make it worth watching. Deploy path: SGLang, multi-node (tp=8, pp=4).
Multimodal: vision + language (and audio)
Ten models this window accept image or video input alongside text. Google's Gemma 4 family alone generated over 24 million downloads across its variants, making it the single biggest open-source multimodal release so far this year by raw pull count.
Gemma 4 family (Google DeepMind)
Google DeepMind released four Gemma 4 models on May 7. Three of them hit breakout numbers independently:
google/gemma-4-31B-it — 9,858,626 downloads 8
google/gemma-4-26B-A4B-it — 8,416,904 downloads 9
google/gemma-4-E4B-it — 6,107,009 downloads 10All three: Apache 2.0, commercial use: yes.
The 31B dense model targets coding and complex reasoning — MMLU-Pro 85.2%, AIME 2026 89.2%, LiveCodeBench v6 80.0%, GPQA Diamond 84.3%. 8 It has 256K context, hybrid sliding-window + global attention, and 156 community finetunes already.
The 26B-A4B-it is the MoE sibling: 25.2B total parameters, only 3.8B activated per token. Google's framing: "This makes it an excellent choice for fast inference compared to the dense 31B model since it runs almost as fast as a 4B-parameter model." 9 Benchmarks are close to the 31B: MMLU-Pro 82.6%, AIME 2026 88.3%, GPQA Diamond 82.3%.
The E4B (8B effective params, 4.5B computation) is the on-device variant with native audio understanding. It accepts text, image, and audio as input, runs on Ollama and llama.cpp, and has 128K context. 10 Benchmarks are lower (MMLU-Pro 69.4%), but it targets laptop/mobile inference where the 31B can't run.
Build-on signals: Transformers, vLLM, SGLang, llama.cpp, Ollama. The E4B in particular opens up fully local multimodal apps — the model runs on current MacBook hardware. Apache 2.0 means no license negotiation required.
Qwen3.6 family (Alibaba)
Both: Apache 2.0, commercial use: yes. Both released April 24.
Qwen3.6-35B-A3B is an MoE model: 35B total, 3B active per token, with Gated DeltaNet + MoE hybrid architecture and 256K context (extensible to 1M). 11 SWE-bench Verified: 73.4%, Terminal-Bench 2.0: 51.5%, GPQA Diamond: 86.0%, AIME 2026: 92.7%. 352 quantizations already exist in the ecosystem.
Qwen3.6-27B is the dense flagship: 28B parameters, same 256K-extensible-to-1M context. 12 SWE-bench Verified: 77.2%, Terminal-Bench 2.0: 59.3%, AIME 2026: 94.1% — the SWE-bench number on the 27B dense model is higher than the 35B MoE, which is unusual. Both models preserve thinking traces from historical messages, enabling multi-turn reasoning workflows where the model can recall its own prior chain of thought. 11
Build-on signals: vLLM, SGLang, KTransformers, Transformers, Qwen-Agent, Qwen Code. The agentic coding focus and thinking-trace preservation make these practical for code-generation pipelines where multi-turn context matters.
Kimi-K2.6
moonshotai/Kimi-K2.6 13| Field | Value |
|---|---|
| Monthly downloads | 2,230,311 |
| License | Modified MIT — commercial use: yes (with conditions) |
| Parameters | 1.1T total / 32B activated (MoE, 384 experts) |
| Context | 256K |
| Released | May 12, 2026 |
Kimi-K2.6 from Moonshot AI is a native multimodal model: text, image, and video input, text output. The architecture includes MLA (Multi-head Latent Attention) and a 400M MoonViT vision encoder. 13 What distinguishes it from other large MoE models is the agent swarm capability: "Scaling horizontally to 300 sub-agents executing 4,000 coordinated steps, K2.6 can dynamically decompose tasks into parallel, domain-specialized subtasks." 13
HLE-Full (with tools): 54.0% — highest among open models at time of release. BrowseComp: 83.2%, LiveCodeBench v6: 89.6%, AIME 2026: 96.4%. 13
Build-on signals: vLLM, SGLang, KTransformers, Kimi Code CLI, Moonshot API. Native INT4 quantization ships with the model. The agent swarm architecture is the commercial pitch here: multi-step autonomous workflows without external orchestration frameworks.
Nvidia Nemotron-3-Nano-Omni
nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16 14| Field | Value |
|---|---|
| Monthly downloads | ~1.24M (across BF16 + FP8 + NVFP4 variants) |
| License | NVIDIA Open Model Agreement — commercial use: yes |
| Parameters | 31B total / ~3B active (Mamba2-Transformer hybrid MoE) |
| Context | 256K |
| Released | April 28, 2026 |
This model accepts video, audio, image, and text simultaneously. The architecture is a Mamba2-Transformer hybrid MoE with CRADIO v4-H vision encoder and Parakeet speech encoder. 14 Targeted use cases: document intelligence (OCR and chart reading), video+speech analysis, GUI/agentic workflows, and ASR with word-level timestamps. The NVFP4 variant runs on a single RTX 5090 at 21GB VRAM.
Build-on signals: vLLM, TensorRT-LLM, TensorRT Edge-LLM (Jetson Thor), SGLang, llama.cpp, Ollama. The Jetson Thor path makes this relevant for edge hardware deployments. NVIDIA's commercial license is permissive but different from MIT/Apache — worth reading if you plan to redistribute.
MiniCPM-V-4.6
openbmb/MiniCPM-V-4.6 15| Field | Value |
|---|---|
| Monthly downloads | 56,518 (first hours — released May 17) |
| License | Apache 2.0 — commercial use: yes |
| Parameters | 1B (SigLIP2-400M vision + Qwen3.5-0.8B LLM) |
| Released | May 17, 2026 (today) |
OpenBMB's 1B-parameter multimodal model is built specifically for on-device use: iOS, Android, and HarmonyOS demo apps are open-sourced alongside the weights. 15 The model achieves 13 on the Artificial Analysis Intelligence Index benchmark, "outperforming Qwen3.5-0.8B's score of 10 with 19x fewer token cost." 15 Architecture: LLaVA-UHD v4 with mixed 4x/16x visual token compression, over 50% FLOP reduction versus prior versions.
Build-on signals: vLLM, SGLang, llama.cpp, Ollama. GGUF/BNB/AWQ/GPTQ quantized variants available. For mobile app developers who need on-device vision, this is one of very few models small enough to run on current phone hardware with Apache 2.0 licensing.
SenseNova-U1-8B-MoT
sensenova/SenseNova-U1-8B-MoT 16| Field | Value |
|---|---|
| Monthly downloads | ~13,600 |
| License | Apache 2.0 — commercial use: yes |
| Parameters | ~18B (8B understanding + 8B generation MoT) |
| Released | April 27, 2026 (weights); May 10, 2026 (technical report) |
SenseTime's SenseNova-U1 eliminates both the visual encoder (VE) and variational auto-encoder (VAE) that every other multimodal model relies on. The NEO-unify architecture instead models language and vision as a "unified compound," enabling native interleaved image-text generation, image editing with chain-of-thought reasoning, and infographic generation. 16 The model "models think-and-act across language and vision natively" rather than using adapters to translate between modalities. 16
Build-on signals: Custom inference code on GitHub, GGUF available, vLLM/SGLang support in development. Still early-stage from a deployment tooling perspective — but the architectural novelty (no VE, no VAE) makes it worth tracking for anyone building unified image generation + understanding workflows.
Intern-S2-Preview
internlm/Intern-S2-Preview 17| Field | Value |
|---|---|
| Monthly downloads | 1,059 (released May 15 — 2 days ago) |
| License | Not explicitly stated — verify before shipping |
| Parameters | 36B (continued pretrained from Qwen3.5) |
| Released | May 15, 2026 |
Shanghai AI Laboratory's Intern-S2-Preview is the first open-source model with material crystal structure generation capability alongside general language and vision tasks. 17 The task-scaling approach increases the difficulty, diversity, and coverage of scientific tasks during training. It outperforms the larger Intern-S1-Pro on certain scientific benchmarks despite being smaller.
Build-on signals: LMDeploy, vLLM, SGLang, Claude Code integration, official API. Relevant for teams building tools for materials science, chemistry, or computational research. Too new to have meaningful download velocity data yet.
Video generation
The open video generation space solidified this week around the LTX 2.3 base. Three models drove the bulk of activity.
Sulphur-2-base
SulphurAI/Sulphur-2-base 18| Field | Value |
|---|---|
| Monthly downloads | 970,124 |
| License | Apache 2.0 — commercial use: yes |
| Parameters | 9B (based on LTX 2.3 DiT) |
| Released | ~May 8, 2026 |
SulphurAI's Sulphur-2-base is described on the model card as "an uncensored video generation model based on LTX 2.3 supporting both t2v and i2v natively." 18 It includes a built-in prompt enhancer (served via a GGUF LM). The Apache 2.0 license inherited from the LTX 2.3 base makes it one of the most permissive video generation models available. Four quantizations, eight community Spaces.
Build-on signals: ComfyUI via LTX 2.3 workflows, LM Studio for prompt enhancement. BF16 and FP8 mixed variants available. The large download number suggests this is already the de-facto community baseline for LTX 2.3-based video generation.
LTX2.3-10Eros
TenStrip/LTX2.3-10Eros 19| Field | Value |
|---|---|
| Monthly downloads | 135,648 |
| License | Apache 2.0 (inherited from LTX 2.3) — commercial use: yes |
| Parameters | 21B (BF16 checkpoint with CLIP and VAEs) |
| Released | ~May 10, 2026 |
A community merge of Sulphur-2-base optimized specifically for image-to-video. TenStrip describes the approach: "This is a different merge attempt for ideal I2V use. It uses layer scaled merges of different steps, it's not a straight weight merge. It behaves much nicer than lora load and respects prompt." 19 SulphurAI endorsed this as the recommended I2V variant of Sulphur-2.
Build-on signals: ComfyUI with
10S-Comfy-nodes (GitHub). FP8 and BF16 variants, Kijai split files. A GGUF quantization from vantagewithai has 62.7k additional downloads. For I2V workflows, this appears to be the community-preferred starting point right now.
Motif-Video-2B
Motif-Technologies/Motif-Video-2B 20| Field | Value |
|---|---|
| Monthly downloads | 3,623 |
| License | Apache 2.0 — commercial use: yes |
| Parameters | 2B |
| Released | April 14, 2026 (Diffusers support: May 15) |
Motif-Video 2B was built with fewer than 10 million training clips and under 100,000 H200 GPU hours. It achieves a VBench total score of 83.76% — higher than Wan2.1-14B (83.69%) at 7 times fewer parameters. 20 The team is candid about the gap: "In our internal side-by-side comparisons against Wan2.1-T2V-14B we observe a perceptual gap in favor of the larger model on temporal stability and fine human anatomy." 20 Output: up to 720p at 121 frames (~5 seconds at 24fps).
Build-on signals: Diffusers (official support added May 15), ComfyUI, GGUF quantized weights. VRAM: ~30GB base, ~15GB with FP8 + CPU offload. The Diffusers integration makes this the easiest of the open video models to drop into an existing Python pipeline right now.
Audio: TTS and ASR
The TTS space had its busiest week yet in terms of model releases. OmniVoice's 600-language coverage stands apart, but the ASR competition is also tightening at the top.

OmniVoice
k2-fsa/OmniVoice 21| Field | Value |
|---|---|
| Monthly downloads | 2,061,515 |
| License | Open-source (MIT-adjacent) with anti-misuse disclaimer |
| Parameters | 0.6B (Qwen3-0.6B base) |
| Released | ~April 1, 2026 |
OmniVoice is a zero-shot TTS model supporting over 600 languages, built on a diffusion language model architecture (not a traditional seq2seq TTS). 21 The paper (arXiv 2604.00688) claims "the broadest language coverage among zero-shot TTS models" and "state-of-the-art voice cloning quality from a short reference audio." 21 Inference speed: RTF as low as 0.025 (40× faster than real-time). Supports voice cloning, voice design (gender/age/pitch/accent control), non-verbal markers such as
[laughter], and pronunciation correction.Build-on signals:
pip install omnivoice, Hugging Face Spaces (100+ community demos), Google Colab, GitHub. 12 adapters, 25 finetunes, 7 quantizations. For apps targeting non-English speakers, this is the most deployment-ready multilingual TTS option available in open-source today.Cohere Transcribe
CohereLabs/cohere-transcribe-03-2026 22| Field | Value |
|---|---|
| Monthly downloads | 289,729 |
| License | Apache 2.0 — commercial use: yes |
| Parameters | 2B |
| Released | March 26, 2026 |
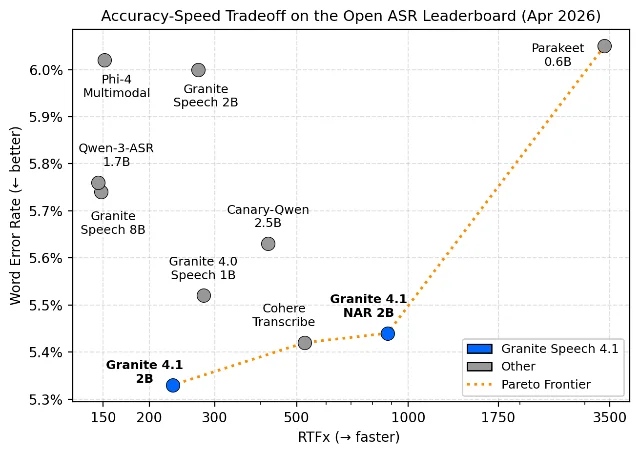
Cohere Transcribe holds the #1 position on the Open ASR Leaderboard with a mean word error rate of 5.42. 22 The architecture is a large Conformer encoder with a lightweight Transformer decoder, supporting 14 languages. RTFx: 524.88 on the leaderboard — substantially faster than most dedicated ASR models of comparable accuracy. 22
Build-on signals: Native Transformers, vLLM, mlx-audio, transformers.js (WebGPU browser demo), Rust implementation. An iOS app (Whisper Memos) and Android app (Whisperian) already use it. 23 community quantizations. The Apache 2.0 license and top leaderboard position make this the default choice for new ASR pipelines in the 14 supported languages.
Granite Speech 4.1
ibm-granite/granite-speech-4.1-2b 23| Field | Value |
|---|---|
| Monthly downloads | 228,763 |
| License | Apache 2.0 — commercial use: yes |
| Parameters | 2B (16 Conformer blocks + 2-layer Q-former + Granite 4.0 1B LLM backbone) |
| Released | April 29, 2026 |
IBM's Granite Speech 4.1 2B ranks #2 on the Open ASR Leaderboard with mean WER 5.33, just ahead of Cohere Transcribe (5.42) and its own predecessor Granite 4.0 Speech (5.52). 23 The model was trained on 174,000 hours of audio from public corpora. Six languages: English, French, German, Spanish, Portuguese, Japanese. It also supports bidirectional speech translation (X→En and En→X), punctuation, truecasing, and keyword list biasing. 23
Two additional variants:
granite-speech-4.1-2b-plus (speaker attribution + timestamps) and granite-speech-4.1-2b-nar (non-autoregressive, faster). Apache 2.0 throughout.Build-on signals: Transformers ≥ 4.52.1, vLLM, speculative decoding. The bidirectional AST support and keyword biasing make it more flexible for enterprise transcription workflows than Cohere Transcribe, which doesn't list those features.
Supertonic 3
Supertone/supertonic-3 24| Field | Value |
|---|---|
| Monthly downloads | 20,208 |
| License | OpenRAIL-M (model) / MIT (code) — check usage restrictions |
| Parameters | ~99M (ONNX assets) |
| Released | May 6, 2026 (v3) |
Supertone's lightweight ONNX TTS expanded from 5 languages to 31 in v3. 24 No GPU required — it runs entirely on CPU via ONNX Runtime. The model card states it "runs fast on CPU, even compared with much larger baselines measured on A100 GPU, and uses substantially less memory." 24 Supports expression tags:
<happy>, <sad>, <angry>.Build-on signals:
pip install supertonic, 9 community Spaces. At 99M parameters, this is realistically deployable on serverless edge infrastructure with zero GPU cost. ⚠️ OpenRAIL-M model license has specific usage restrictions — review before commercial deployment.
VieNeu-TTS-v2
pnnbao-ump/VieNeu-TTS-v2 25| Field | Value |
|---|---|
| Monthly downloads | 31,360 |
| License | Not explicitly stated — verify before shipping |
| Parameters | 0.3B |
| Released | May 8, 2026 |
A Vietnamese-English bilingual TTS with code-switching support — the model can transition between Vietnamese and English within a single synthesis pass. 25 Instant voice cloning from 3–5 seconds of reference audio. Podcast-style generation supported. At 31k downloads in 9 days, it has the fastest pull rate among the smaller audio models this week.
Build-on signals: Small enough for serverless inference. Relevant for apps targeting Vietnamese-speaking users. ⚠️ License not confirmed — check before commercial use.
Also released this week (too early for full velocity assessment):
- Dramabox (
ResembleAI/Dramabox) 26 — prompt-driven expressive TTS built on LTX-2.3 (IC-LoRA), with neural watermarking (Resemble Perth). 936 downloads in first days. LTX-2 Community License. - Scenema Audio (
ScenemaAI/scenema-audio) 27 — zero-shot expressive voice cloning with scene-aware audio (rain, crowds, etc.), 13 languages, 8-step distilled latent diffusion. 209 downloads. LTX-2 Community License.
Both require 24GB VRAM and use the LTX-2 Community License — check the terms carefully if you plan commercial deployment.
Image generation
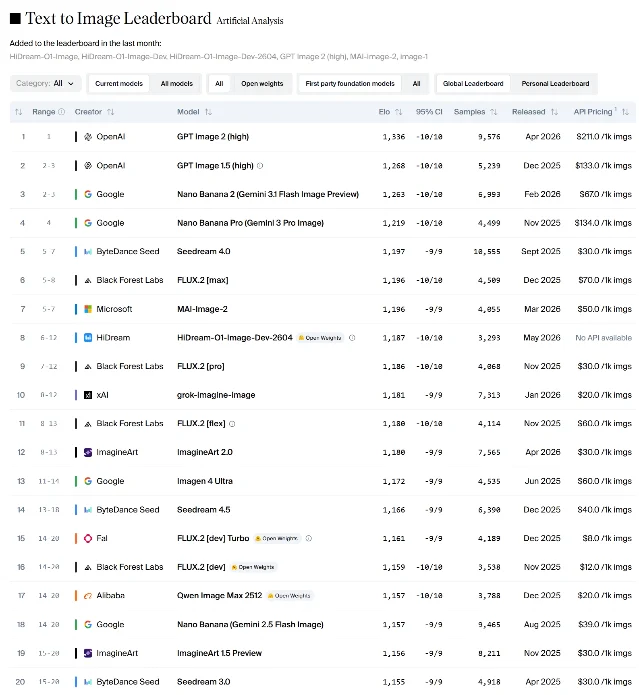
HiDream-O1-Image
HiDream-ai/HiDream-O1-Image 28| Field | Value |
|---|---|
| Monthly downloads | 14,285 (first ~10 days) |
| License | MIT — commercial use: yes |
| Parameters | 8B (Pixel-level Unified Transformer, no external VAE) |
| Released | May 8, 2026 |
HiDream-O1-Image eliminates the VAE and disjoint text encoder that standard diffusion models rely on. The Pixel-level Unified Transformer (UiT) "natively encodes raw pixels, text, and task-specific conditions in a single shared token space." 28 Native max resolution: 2,048 × 2,048. GenEval Overall: 0.90 (beats FLUX.2 Dev at 0.87). DPG-Bench: 89.83. The Artificial Analysis T2I Arena ranked the Dev-2604 variant at #8 among all models, "positioned to be the new leading open weights Text to Image model." 28
Build-on signals: Python CLI (
inference.py), Flask web demo, 11 community Spaces, Diffusers-compatible. Three variants: Full (50-step), Dev (28-step distilled), Dev-2604 (latest). MIT license with no usage restrictions.Z-Anime
SeeSee21/Z-Anime 29| Field | Value |
|---|---|
| Monthly downloads | 14,991 |
| License | Apache 2.0 — commercial use: yes |
| Parameters | 6B (S3-DiT, full fine-tune on Alibaba Z-Image Base) |
| Released | April 26, 2026 |
A full fine-tune — not a LoRA merge — of Alibaba's Z-Image Base architecture, trained specifically for anime-style generation. 29 Supports natural language prompting (not tag lists), full negative prompts, LoRA training ready. VRAM requirements: ~12GB BF16, ~6GB FP8, ~4.2GB GGUF Q4.

Build-on signals: ComfyUI (official workflow JSON), Diffusers (
ZImagePipeline.from_pretrained()), 6 community Spaces. Distilled 8-step and 4-step variants bring inference time down substantially. The 4.2GB Q4 variant runs on consumer 8GB VRAM cards.Also notable:
- LumiPic (
oumoumad/LumiPic) 30 — SDR-to-HDR LoRA based on the LumiVid research (arXiv 2604.11788). Outputs ARRI LogC3-encoded EXR files. Works across Qwen-Image-Edit-2511 and FLUX.2-klein bases. Apache 2.0. 2,322 downloads. - JoyAI-Image-Edit (
jdopensource/JoyAI-Image-Edit) 31 — JD.com's spatial image editing model supporting object move, rotation, and camera control via instruction prompts (arXiv 2605.04128). Apache 2.0. 280 downloads.
Quick-scan license table
| Model | License | Commercial use | Quickest deploy path |
|---|---|---|---|
| DeepSeek-V4-Pro | MIT | Yes | vLLM / SGLang / DeepSeek API |
| DeepSeek-V4-Flash | MIT | Yes | vLLM / SGLang |
| GLM-5.1 | Unverified | Verify first | SGLang / vLLM |
| MiniMax-M2.7 | Proprietary | API/platform only | MiniMax platform |
| ZAYA1-8B | Unverified | Verify first | Custom vLLM fork |
| MiMo-V2.5-Pro | Unverified | Verify first | SGLang |
| Ring-2.6-1T | MIT | Yes | SGLang (multi-node) |
| Gemma-4-31B-it | Apache 2.0 | Yes | vLLM / Ollama |
| Gemma-4-26B-A4B-it | Apache 2.0 | Yes | vLLM / Ollama |
| Gemma-4-E4B-it | Apache 2.0 | Yes | Ollama / llama.cpp |
| Qwen3.6-35B-A3B | Apache 2.0 | Yes | vLLM / SGLang |
| Qwen3.6-27B | Apache 2.0 | Yes | vLLM / SGLang |
| Kimi-K2.6 | Modified MIT | Yes (with conditions) | vLLM / Kimi Code CLI |
| Nemotron-3-Nano-Omni | NVIDIA Open Model | Yes | vLLM / TensorRT / Ollama |
| MiniCPM-V-4.6 | Apache 2.0 | Yes | Ollama / llama.cpp |
| SenseNova-U1-8B-MoT | Apache 2.0 | Yes | GitHub custom inference |
| Intern-S2-Preview | Unverified | Verify first | LMDeploy / vLLM |
| Sulphur-2-base | Apache 2.0 | Yes | ComfyUI |
| LTX2.3-10Eros | Apache 2.0 | Yes | ComfyUI |
| Motif-Video-2B | Apache 2.0 | Yes | Diffusers |
| OmniVoice | MIT-adjacent | Yes (anti-misuse) | pip install omnivoice |
| Cohere Transcribe | Apache 2.0 | Yes | Transformers / vLLM |
| Granite Speech 4.1 | Apache 2.0 | Yes | Transformers |
| Supertonic 3 | OpenRAIL-M | Check restrictions | pip install supertonic |
| VieNeu-TTS-v2 | Unverified | Verify first | — |
| Dramabox | LTX-2 Community | Check terms | Python SDK |
| Scenema Audio | LTX-2 Community | Check terms | Python SDK |
| HiDream-O1-Image | MIT | Yes | Diffusers / Spaces |
| Z-Anime | Apache 2.0 | Yes | ComfyUI / Diffusers |
| LumiPic | Apache 2.0* | Yes | ComfyUI |
| JoyAI-Image-Edit | Apache 2.0 | Yes | GitHub inference |
| RE-USE | NVIDIA NSCLv1 | Non-commercial | Python SDK |
| LocalVQE | Apache 2.0 | Yes | GGML / Python SDK |
*LumiPic license is Apache 2.0-compatible per the model card; the base models have their own licenses.
On the watch list
Two models released in the past two days have download counts too low for meaningful velocity signals yet:
- Ring-2.6-1T (1,468 downloads, May 15) — MIT license, Ant Group provenance, strong benchmark numbers. The async RL training paradigm and dual reasoning-effort levels are novel. Check next week.
- Intern-S2-Preview (1,059 downloads, May 15) — material science applications are a narrow vertical, but the "crystal structure generation" capability has no open-source competitor. License unconfirmed.
Two areas remain unscanned from this run: text-to-3D pipelines (TencentARC/Pixal3D flagged as having traction) and text-to-audio/music pipelines. Both will be included in next week's scan.
Also worth noting: the audio-to-audio category produced two models not covered in full cards above:
- RE-USE (
nvidia/RE-USE) 32 — 9.6M-parameter universal speech enhancement (8–48kHz). NVIDIA NSCLv1 license means non-commercial use only. 3,516 downloads. - LocalVQE v1.2 (
LocalAI-io/LocalVQE) 33 — 1.3M-parameter real-time AEC + noise suppression + dereverberation running ~10× realtime on CPU. Apache 2.0, 1,978 downloads. Built for real-time voice call quality.
References
- 1deepseek-ai/DeepSeek-V4-Pro · Hugging Face
- 2deepseek-ai/DeepSeek-V4-Flash · Hugging Face
- 3zai-org/GLM-5.1 · Hugging Face
- 4MiniMaxAI/MiniMax-M2.7 · Hugging Face
- 5Zyphra/ZAYA1-8B · Hugging Face
- 6XiaomiMiMo/MiMo-V2.5-Pro · Hugging Face
- 7inclusionAI/Ring-2.6-1T · Hugging Face
- 8google/gemma-4-31B-it · Hugging Face
- 9google/gemma-4-26B-A4B-it · Hugging Face
- 10google/gemma-4-E4B-it · Hugging Face
- 11Qwen/Qwen3.6-35B-A3B · Hugging Face
- 12Qwen/Qwen3.6-27B · Hugging Face
- 13moonshotai/Kimi-K2.6 · Hugging Face
- 14nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16 · Hugging Face
- 15openbmb/MiniCPM-V-4.6 · Hugging Face
- 16sensenova/SenseNova-U1-8B-MoT · Hugging Face
- 17internlm/Intern-S2-Preview · Hugging Face
- 18SulphurAI/Sulphur-2-base · Hugging Face
- 19TenStrip/LTX2.3-10Eros · Hugging Face
- 20Motif-Technologies/Motif-Video-2B · Hugging Face
- 21k2-fsa/OmniVoice · Hugging Face
- 22CohereLabs/cohere-transcribe-03-2026 · Hugging Face
- 23ibm-granite/granite-speech-4.1-2b · Hugging Face
- 24Supertone/supertonic-3 · Hugging Face
- 25pnnbao-ump/VieNeu-TTS-v2 · Hugging Face
- 26ResembleAI/Dramabox · Hugging Face
- 27ScenemaAI/scenema-audio · Hugging Face
- 28HiDream-ai/HiDream-O1-Image · Hugging Face
- 29SeeSee21/Z-Anime · Hugging Face
- 30oumoumad/LumiPic · Hugging Face
- 31jdopensource/JoyAI-Image-Edit · Hugging Face
- 32nvidia/RE-USE · Hugging Face
- 33LocalAI-io/LocalVQE · Hugging Face
Add more perspectives or context around this Drop.