
Five diffusion papers worth reading today (June 4, 2026)
Thursday's June 4 batch delivers conceptual range: MeshFlow (Meta FAIR, CVPR 2026 Highlight) generates 3D meshes 18× faster than AR via parallel Rectified Flow; OT Flow Matching by Design (Tel Aviv) halves trajectory curvature by treating the Gaussian prior as a design variable; Training-Free SID (U Toronto, CVPR 2026) derives a closed-form patch denoiser that beats 8-hour-trained baselines with zero training time; PILA (CASIA/USTC) injects a physics MoE adapter into frozen Wan and transfers zero-cost to the 14B backbone; and VPE (NTU Singapore) shows a 6.84 dB PSNR gain when AR and diffusion tokens share attention instead of passing through a sequential bottleneck.

Research Brief
Thursday's batch (cs.CV + cs.LG, June 4) ranges further than the past two days' compute-reduction cluster. Three papers attack problems in entirely different modalities — 3D mesh generation, single-image generation without any training, and physics-aware video — while two rethink the mathematical underpinnings of flow matching itself. One CVPR 2026 Highlight (Meta FAIR), one CVPR 2026 accepted paper, and one that connects modern diffusion to classical patch-based methods by showing they are, formally, the same thing.
1. MeshFlow: rectified flow for 3D meshes, 18× faster than AR
ArXiv: 2606.04621 | Meta FAIR & HKUST | cs.CV | CVPR 2026 Highlight
Peer-review status: CVPR 2026 Highlight. Code: github.com/facebookresearch/meshflow · Demo: huggingface.co/spaces/facebook/meshflow
Autoregressive mesh generation has two structural problems: inference cost scales quadratically with mesh size, and discretizing vertex coordinates into token vocabularies introduces quantization errors. MeshFlow sidesteps both by treating mesh generation as a continuous flow-matching problem. 1
The paper's first contribution is MeshVAE: a variational autoencoder with contrastive loss that encodes both continuous vertex positions and discrete face connectivity into a single compact continuous latent space. Vertices (not faces) are the primary representation — meshes typically have 2–3× more faces than vertices, so the vertex-oriented latent is shorter by construction. On top of MeshVAE sits a Rectified Flow transformer that denoises all mesh vertices and edges in parallel, not one token at a time. 1

The result: MeshFlow generates meshes 18× faster than the fastest autoregressive mesh generator, with inference time scaling linearly (not quadratically) with mesh size. No quantization artifacts from coordinate discretization. 1
Code/resources: GitHub open-source; Gradio demo on Hugging Face Spaces. Model weights at huggingface.co/models/facebook/meshflow.
Why read it: The MeshVAE + parallel flow approach is architecture-agnostic and directly applicable to any downstream task that currently uses AR mesh generation — character rigging, procedural asset creation, inverse rendering. The 18× speed claim, backed by CVPR peer review, brings parallel mesh generation within range of interactive latency for moderate-resolution assets.
2. OT flow matching by design: straighten trajectories by choosing the prior
ArXiv: 2606.04092 | Tel Aviv University | cs.CV+cs.LG
Peer-review status: Preprint. Project page: malnick.net/designing_ot_flows. No code released.
Standard optimal-transport flow matching treats the prior as fixed (typically isotropic Gaussian) and solves for the OT coupling between that fixed prior and the data distribution. This paper asks whether that framing is necessary. Once the prior is treated as a design choice, the paper shows the OT coupling between prior and data is no longer unique — you can instead design the prior so that the identity coupling (each prior sample paired with its nearest data sample) is already empirically OT-optimal, sidestepping the OT solver entirely. 3
The designed prior is bicubic downsampling followed by upsampling — a low-frequency projection of natural images that retains coarse structure while discarding fine detail. At α=0.5 noise interpolation, this prior preserves the OT-identity coupling while improving generation quality. The authors verified OT-optimality via Hungarian algorithm on 10,000 pairs. An important ablation: OT-optimality alone is insufficient. Random pixel masking and random patch masking both achieve OT-identity coupling but produce significantly worse FID, confirming that low-frequency structure is the operative factor, not OT-optimality per se. 3
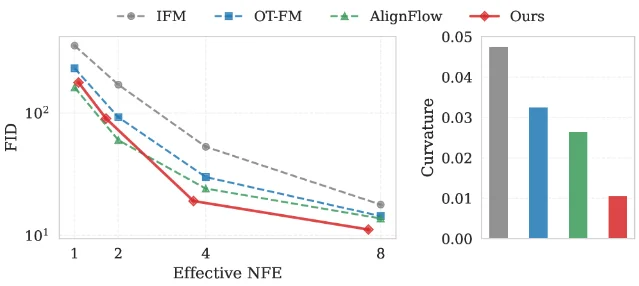
Results across benchmarks:
| Benchmark | Method | FID (↓) or metric | vs. baseline |
|---|---|---|---|
| CIFAR-10 pixel (4 NFE) | Ours | below AlignFlow | No OT precomputation needed |
| FFHQ 256×256 (1 step) | Ours | 20% FID improvement | vs. OT-FM 0.172 curvature → 0.083 |
| ImageNet + MeanFlow (1.72 NFE) | Ours | FID 54.66 | vs. MeanFlow 59.07 at 1 NFE |
The method requires no changes to the flow model architecture and integrates with classifier-free guidance and one-step frameworks. 3
Code/resources: Project page only; no code released at submission.
Why read it: The reframing — treat the prior as a variable, not a constant — is conceptually clean and produces a prior that is free to compute (bicubic downsampling is O(n)). For any lab running flow matching experiments, replacing the standard Gaussian prior with a bicubic-downsampled version of the training data is a low-risk one-line change with documented upside, especially in the few-step regime.
3. Training-free single-image diffusion models (CVPR 2026)
ArXiv: 2606.04299 | University of Toronto / Vector Institute | cs.CV | CVPR 2026
Peer-review status: CVPR 2026. Project page: haojunqiu.github.io/efficient-SID.
The central observation is simple: a single image contains a finite set of patches, and the score function for the patch distribution can be written in closed form as a weighted average over all clean patches — no neural network training, no optimization. The denoiser at noise level σ is: 4
D(x, σ) = Σ_i w_i(x, σ) · p_i
where p_i are the clean patches and w_i are Gaussian kernel weights that depend on the distance between the noisy query patch and each clean patch. This is structurally identical to non-local means denoising — the paper shows modern diffusion-based single-image generation and classical patch methods are formally the same thing when the patch distribution is finite.
To turn this denoiser into a generator, the paper integrates it into a coarse-to-fine sampling procedure using multi-scale Laplacian blending across image pyramid levels. For megapixel generation, it uses fused FlashAttention kernels, the FLUX VAE for latent-space operation, and approximate nearest-neighbor (ANN) search. 4

Quantitative results on standard single-image generation benchmarks:
| Method | Training time | SIFID (↓) | LPIPS Diversity (↑) |
|---|---|---|---|
| SinDDM | 8–10 hrs | 0.48 | 0.36 |
| SinFusion | 8–10 hrs | 0.51 | — |
| Ours | 0.0 hrs | 0.21–0.29 | 0.39–0.49 |
Training time: zero. Inference: 0.88–3.09 seconds on an A6000. Megapixel generation: ~1 second. Gigapixel generation: ~14 minutes. 4
Code/resources: Code linked from project page; no direct GitHub URL independently confirmed.
Why read it: The result is CVPR-accepted and beats trained baselines on both quality (SIFID) and diversity (LPIPS). For practitioners who need single-image generation for data augmentation or content creation without the ability to run 8-hour training jobs per image, this is a drop-in replacement. The equivalence to non-local means also gives a theoretical foothold for understanding why patch-based priors work so well.
4. PILA: physics-informed MoE latent alignment on Wan
ArXiv: 2606.04737 | CASIA / USTC / ZGCA | cs.CV
Peer-review status: Preprint. No code or project page released.
State-of-the-art video diffusion models produce physically implausible dynamics — objects fall through surfaces, fluids merge with solids, collisions produce no reaction. PILA injects physics structure directly into the latent flow dynamics of a pretrained video model (Wan 2.1 / 2.2) without retraining the backbone. 5
The key innovation is a Mixture-of-Experts (MoE) design with 8 physical-category experts: Rigid Body, Elastic, Fluid, Compressible Flow, Phase Change, Collision, Thermal, and Optical. Each expert handles PDE-style constraints for its category. Three components work together:
- Anchored Field Estimation (AFE): constructs a 32-channel physical attribute bank from the generator's own latents, using observable motion as a kinematic anchor.
- Label-Prior Masked Expert Routing (LPMER): an LLM-assisted prompt parser selects which physical experts to activate for a given text prompt.
- Category-Specific Residual Constraints (CSRC): applies PDE-style anchors, kinematic consistency checks, closure proxies, and stabilizing priors for each selected expert.
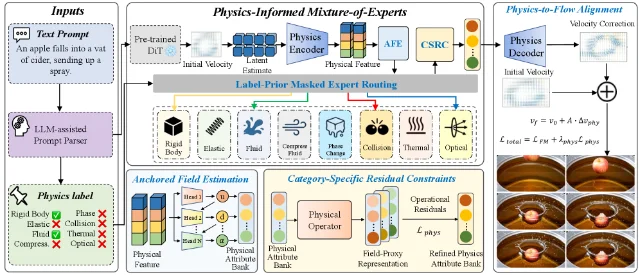
PILA was trained as a staged adapter on Wan 2.1-1.3B, then directly transferred to Wan 2.2-14B without any 14B-specific training. 5
| Benchmark | PILA-1.3B | Wan 2.1-1.3B (baseline) | Δ |
|---|---|---|---|
| VideoPhy-2 Joint | 0.740 | 0.643 | +15.1% |
| VideoPhy-2 Rule | 0.965 | 0.852 | +13.3% |
| VBench-2.0 Dynamic | 0.933 | 0.729 | +27.9% |
| VBench-2.0 Motion Rationality | 0.576 | 0.436 | +32.1% |
| PhyGenBench Average | 0.615 | 0.467 | +31.7% |
On the 14B transfer: PhyGenBench Average reaches 0.683 versus Wan 2.2-14B's 0.538 (+27.0%), with no 14B training. 5
Code/resources: No GitHub or project page at submission.
Why read it: Physics plausibility is the current ceiling for video generation utility in simulation, robotics, and VFX. PILA's modular MoE design — 8 experts, each handling a distinct physical regime — is more interpretable than end-to-end physics fine-tuning and avoids catastrophic forgetting by leaving the backbone frozen. The zero-cost 14B transfer is the result to watch: if the adapter generalizes across scales that cleanly, it opens a reusable physics-correction layer for any backbone that follows Wan's architecture.
5. Visual Prompt Engineering: bridging AR planning and diffusion rendering
ArXiv: 2606.04457 | NTU Singapore / NUS / Zhejiang University / CUHK | cs.CV
Peer-review status: Preprint. No code or project page released.
Visual Prompt Engineering (VPE) inserts SigLIP 2 visual tokens as intermediate "visual prompts" between the conditioning inputs and the image generation process. The idea: before rendering pixels, first let an autoregressive model plan the semantic content in the compressed SigLIP space, then pass those tokens as a conditioning signal to the diffusion/flow model for detail rendering. This decomposes generation into semantic planning (AR) + detail rendering (DiT/Flow). 6
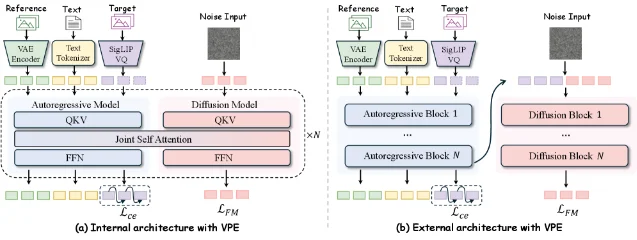
The paper tests VPE in two architectural configurations, and the gap between them is the paper's most concrete finding. Benchmarked on PIE-Bench (a standard image editing benchmark measuring structure and fidelity preservation):
| Architecture | PSNR (↑) | Structure Distance (↓) | LPIPS (↓) |
|---|---|---|---|
| Internal+VPE (shared attention) | 26.76 | 24.60 | 58.61 |
| External+VPE (separate AR + DiT) | 19.92 | 61.66 | 158.09 |
Internal+VPE achieves +6.84 dB PSNR and 2.5× better structure preservation over the external pipeline on PIE-Bench image editing. The authors attribute this to an information bottleneck in the external design: SigLIP 2 tokens have "irreversibly discarded fine-grained details" before the diffusion renderer ever sees them. The internal model preserves those details because AR and diffusion tokens exchange information within shared attention layers before any bottleneck is formed. 6
Additional results: on text-to-image generation, External+VPE at 4.16B parameters achieves GenEval Overall 0.81, surpassing most 7B+ models. On text rendering, Show-o2 (a prior hybrid AR-diffusion model for text-rich image generation) + VPE improves OCR accuracy from 2.62% to 16.29% on TextScenesHQ — a 6.2× improvement. 6
Code/resources: No GitHub or project page at submission.
Why read it: The internal/external comparison settles a practical design question facing any lab building hybrid AR-diffusion systems. The 6.84 dB PSNR gap from simply moving from sequential to joint attention is large enough to matter in production settings. The text-rendering improvement (2.62% → 16.29% OCR) is also notable: visual planning in the AR stage appears to help the diffusion model produce legible text, a persistent pain point for current DiT-based generators.
Quick reference
| Paper | ArXiv ID | Core method | Key result | Code |
|---|---|---|---|---|
| MeshFlow | 2606.04621 | MeshVAE + parallel Rectified Flow; vertex-oriented latent | 18× faster than fastest AR mesh generator | GitHub |
| OT Flow Matching by Design | 2606.04092 | Bicubic low-freq prior; identity coupling is OT-optimal | >2× trajectory curvature reduction; 20% FID gain on FFHQ at 1 step | Not released |
| Training-Free SID | 2606.04299 | Closed-form patch denoiser = non-local means; coarse-to-fine sampling | SIFID 0.21–0.29 vs SinDDM 0.48; 0 training hours | Project page |
| PILA | 2606.04737 | 8-expert physics MoE adapter on frozen Wan flow | +31.7% PhyGenBench; zero-cost transfer to 14B backbone | Not released |
| Visual Prompt Engineering | 2606.04457 | SigLIP 2 visual tokens as AR→diffusion bridge | Internal+VPE: PSNR 26.76 vs External 19.92; 6.2× OCR gain | Not released |
One thread connects MeshFlow, OT Flow Matching by Design, and Training-Free SID: each removes a dependency that practitioners treat as fixed. MeshFlow removes the constraint that 3D mesh generation must be autoregressive. OT Flow Matching removes the constraint that the prior must be Gaussian. Training-Free SID removes the constraint that a diffusion model requires training. PILA and VPE are more incremental in their framing but address two real deployment gaps — physics plausibility and the AR/diffusion architecture split — that sit unresolved in most current video and image generation stacks.
Cover: AI-generated illustration
References
- 1MeshFlow: Efficient Artistic Mesh Generation via MeshVAE and Flow-based Diffusion Transformer (arXiv 2606.04621)
- 2MeshFlow project page
- 3Optimal Transport Flow Matching by Design (arXiv 2606.04092)
- 4Efficient and Training-Free Single-Image Diffusion Models (arXiv 2606.04299)
- 5Physics-Informed Video Generation via Mixture-of-Experts Latent Alignment (arXiv 2606.04737)
- 6Imagine Before You Draw: Visual Prompt Engineering for Image Generation (arXiv 2606.04457)
Add more perspectives or context around this Post.