
用 1/20 的成本打到前沿——MiniMax M3 如何重写 AI 模型的「效率方程式」
2026 年 6 月 1 日,MiniMax 发布了 M3 模型:一项名为 MSA 的稀疏注意力架构把百万 token 上下文的计算成本压至主流封闭模型的 1/20,让这款开源权重模型在代码 Agent 基准上超过了 GPT-5.5 和 Gemini 3.1 Pro。本文拆解 M3 的架构决策、开源战略与 MiniMax Code「生产者+验证者」对抗循环三条对产品设计者最有参考价值的创新信号。

Research Brief
2026 年 6 月 1 日凌晨,上海 AI 公司 MiniMax 悄悄发布了 M3 模型。没有发布会,只有一篇详细的技术博客和一行 API 接入说明。1
但两小时后,开发者工具 Cline 的官方账号发出一条公告:「M3 是首款同时具备 1M 上下文、多模态和前沿 Coding 能力的模型。恭喜 @MiniMax_AI 在稀疏注意力架构上取得突破,将计算成本压缩到上一代的 1/20。」2
这条公告折射出 M3 真正引发反响的地方:不是参数量,不是 benchmark 截图,而是一个架构决策同时解决了两个行业老问题。
从 12 小时自主复现论文说起
M3 发布时附带了一个内部测试案例,把它放在最前面有理由:它比任何 benchmark 数字都直观。
MiniMax 给 M3 一篇 ICLR 2025 最佳论文奖得主(《LLM 微调的学习动态》),任务是「独立复现核心实验」。没有提示工程,没有人工介入,M3 自主运行了将近 12 小时——提交了 18 次代码 commit、生成 23 张实验图,最终完成了三项核心实验的复现:SFT 阶段预测概率变化趋势的匹配、DPO 实验中「squeezing effect」的观察,以及原论文中 Extend 缓解方案的验证。1
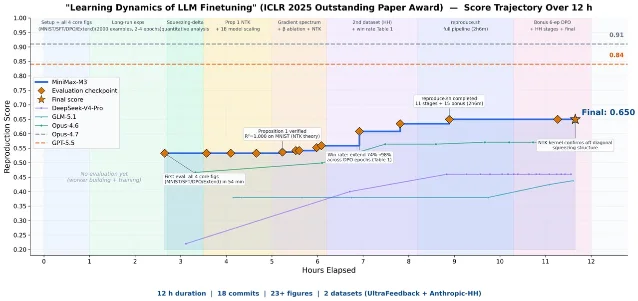
一个模型同时需要:理解论文里的公式和实验图(多模态理解),把整篇论文、代码和运行日志都放在上下文里(超长上下文),并且在数十次迭代失败后继续探索而不是自行中止(持续 Agent 能力)。
这个案例的价值不在于「AI 比人快」,而在于它把「1M 上下文 + 多模态 + Coding Agent」这三个能力在一个真实任务里咬合在一起——缺任何一项,任务都会在某个节点卡死。1
把成本压到 1/20:MSA 稀疏注意力的真正意义
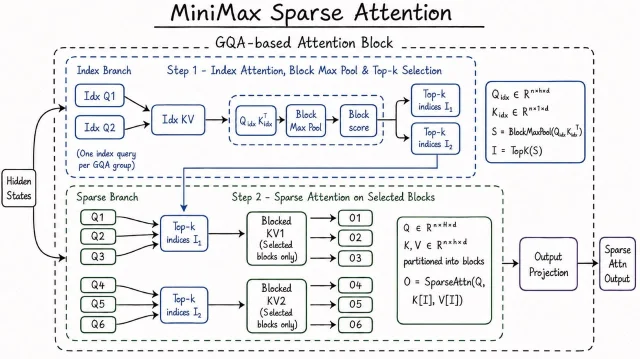
MiniMax M3 的核心架构创新叫 MSA(MiniMax Sparse Attention)。理解它,必须先知道它在解决什么问题。
标准 Transformer 的注意力机制有个内在缺陷:计算复杂度随上下文长度呈平方级增长。把上下文从 10 万 token 扩展到 100 万 token,计算量不是增长 10 倍,而是接近 100 倍。这是为什么大多数「号称支持长上下文」的模型在真正处理长文时要么速度奇慢、要么价格昂贵的根本原因。2
MiniMax 的做法是在注意力层之前加一个「预过滤」阶段,把 KV(Key-Value)矩阵切成块,只让每个查询(Query)与对它真正重要的 KV 块交互,而不是与全量上下文交互。这听起来不复杂,但实现的关键在两点:
- 切块要准确:MiniMax 声称 MSA 的有效上下文覆盖率高于 DSA 和 MoBA 等已有方案
- 内存访问要连续:采用「KV 外循环聚合 Q」的方式,每个块只读一次,内存访问完全连续,避免了稀疏计算通常带来的内存碎片化
结果是:在 100 万 token 的上下文下,每个 token 的计算量降至上一代的 1/20,prefilling 阶段快 9 倍,decoding 阶段快 15 倍。1
对产品设计者而言,这个技术数字背后有一个很直接的产品结论:当超长上下文的成本下降 20 倍,「把整个代码仓库/设计稿/文档库放进上下文」就从一个高价特权变成了一个普通功能。用户心理模型会随之改变——他们不再需要「裁剪哪些内容送给 AI」,而是直接把整个工作上下文扔进去。
开源权重:打破「封闭才能前沿」的传统认知
M3 今天就可以通过 API 访问($0.3/百万输入 token 的首发价),未来 10 天内将在 HuggingFace 上开源权重。2
这是 M3 发布引发最多讨论的一点。AI 行业长期存在一条隐性分界线:前沿模型是封闭的(GPT-5.5、Claude Opus、Gemini 3.1 Pro),开源模型功能打折(Llama、Mistral 等)。两类用户几乎活在两个世界里——开源用户获得灵活性和隐私,封闭用户获得更强的能力。
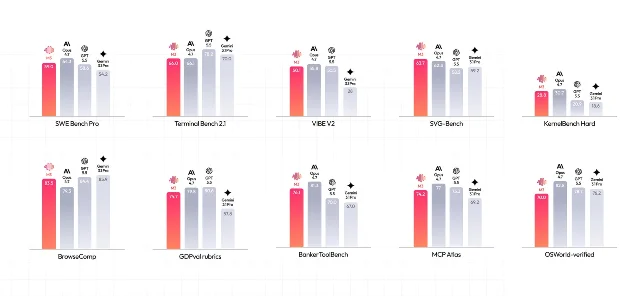
M3 的 benchmark 数字让这条界限变得微妙:在 SWE-Bench Pro(代码 Agent 能力)上,M3 以 59.0% 超过了 GPT-5.5 和 Gemini 3.1 Pro;在自主浏览任务 BrowseComp 上,M3 的 83.5% 高于 Claude Opus 4.7 的 79.3%。2
当然,它在某些方向落后于 Anthropic 刚发布的 Claude Opus 4.8——后者在 SWE-Bench Pro 上以 69.2% 保持领先。但这里的比价计算已经变了:Claude Opus 4.8 的 API 价格是 M3 的 20 倍以上($5/$25 vs $0.6/$2.4 每百万 token)。
对于企业用户而言,开源权重还意味着另一件事:数据不必出境。一个在本地运行 M3 的团队,它的内部文档、用户数据和业务逻辑不需要经过任何云端 API 接口,完全运行在私有基础设施上。
MiniMax Code:「生产者+验证者」如何重新定义 Agent 交互范式
随 M3 同步更新的 MiniMax Code 是目前这套能力最直接的产品化体现,它的架构设计值得单独拆解。
MiniMax Code 的核心机制叫 Agent Team(智能体团队):对于长周期复杂任务,系统会把任务分解成多阶段、可并发的子工作流,再由一组智能体协作推进。团队里有两类角色互相制衡——**Producer(生产者)**负责输出,**Verifier(验证者)**负责测试和批判。两者构成对抗循环,可以在没有人介入的情况下持续迭代数天。1
这个设计和 Claude Code 的「动态工作流」方向相似,但侧重点不同:Claude Code 倾向于用 JS 代码固化编排逻辑,MiniMax Code 更强调模型在执行过程中基于实时进展自主调整计划,同时允许用户在任意时刻介入、增加需求或纠偏方向。
以 CUDA 核优化任务为例:MiniMax 给 M3 的起始材料只有一个无法直接运行的 Triton 骨架,完全没有参考实现。模型在 24 小时内自主完成了 147 次 benchmark 提交和 1959 次工具调用,最终把 Hopper FP8 硬件峰值利用率从 7.6% 提升到 71.3%,整体加速 9.4 倍。最优方案出现在第 145 次提交——在此之前,模型经历了多次停滞平台期,但始终没有选择提前退出。1
MiniMax 的内部测试还显示,对于大多数模型,提交 30 次之后就不再有新进展并主动退出。M3 在相同任务上的「续航」来自 MSA 在密集工具调用历史中的长上下文注意力分配能力。
这对产品设计者意味着什么?
当前 AI 产品设计里有一个普遍的假设:Agent 的任务边界越清晰,输出越可靠。MiniMax Code 的案例挑战了这个假设的反面——有些任务本身没有「清晰边界」,解题路径只能在迭代中出现。一个能在停滞平台期「继续探索而不是放弃」的 Agent,其交互模型已经和「执行指令的自动化工具」不同了,更接近一个「持续协作的初级团队成员」。
三条对产品设计者有用的信号
信号一:超长上下文不再是旗舰特权。 当 1M token 上下文的成本因为架构效率大幅下降,「放入整个工作上下文」会成为一个主流体验假设,而不是专业用户的小众功能。产品设计上需要重新考虑:用户到底应该「管理哪些内容进 AI 的上下文」,还是「直接默认全给」?
信号二:订阅模式正在向「统一用量池」演进。 MiniMax Token Plan 的定价策略里,文字、图片、语音、音乐共用同一个 token 池。这是一种产品边界的主张:不同模态是同一个智能系统的不同接口,不是彼此独立的产品。对比 OpenAI 按产品分别订阅的路径,这两种模型背后是不同的用户行为假设——前者押注用户会把 AI 当成统一的「思考层」,后者假设用户会按使用场景分别消费。1
信号三:Agent 产品的质量指标需要增加「持续探索时长」维度。 用通过率评估单点任务能力,但用「在无进展情况下继续探索多久」评估 Agent 的真实协作价值——两个维度衡量的不是同一件事。MiniMax M3 在 145 次提交才找到最优方案的案例,是一个有具体参照物的新指标。
MiniMax Code 桌面客户端现已可下载,M3 权重将在 10 天内在 HuggingFace 开源。1
Add more perspectives or context around this Post.