
HuggingFace 论文日报
05/22/2026, 02:16:20 PM@gritty
HuggingFace 论文日报 · 2025/05/22
今日 HuggingFace Trending:阿里 GSPO 让 MoE 强化学习训练更稳(Qwen3 背后算法)、MUR 推理减算力 50% 同时涨点、ByteDance Captain Cinema 从故事文字生成短片、TTS-VAR 图像生成质量提升 8.7%、EarthCrafter 生成数千平方公里 3D 地形、Spelke Segments 按联动关系而非语义类别来分割物体。
Research Brief
今天 HuggingFace 上跑出来的 trending 论文覆盖了大模型训练算法、推理效率、AI 视频生成、视觉生成和 3D 地球建模五个方向,几个结果颇有意思,值得挑出来讲清楚。
GSPO:阿里 Qwen 团队用它训练了 Qwen3
一句话版本:训练大模型的强化学习算法从「按词算奖励」升级到「按句算奖励」,训练更稳、效果更好。
现在很多大模型用强化学习做最后一步「对齐」训练——让模型学会更符合人类偏好的回答方式。之前最流行的算法叫 GRPO,它的做法是把模型生成的每个词单独打分,看这个词出现的概率相比基准提高了多少,然后据此调整训练方向。
GSPO(Group Sequence Policy Optimization)把这个逻辑反过来想了:一句话是不是好,应该看整句话,而不是看里面每个词。 它把重要性打分从词级别提升到序列级别——整句话生成得好,整句一起奖励;整句话跑偏了,整句一起惩罚。
这个改动对「混合专家模型」(MoE,一种让模型又大又高效的架构)尤其重要。过去 MoE 的强化学习训练容易出现数值不稳定,GSPO 的序列级操作让这个问题明显改善。
结果:训练效率和模型性能都超过 GRPO,Qwen3 系列模型背后就跑的是这套算法。1
MUR:让大模型「想得更少」但答得更准
一句话版本:借鉴物理学里「动量」的概念,让大模型在推理时只在真正不确定的地方多花时间,其他地方快速跳过。
近两年「思维链」推理很火——让模型在给出答案前先想一遍,往往效果更好。但随之而来的问题是「过度思考」:模型哪怕面对简单问题也绕很多圈子,白白浪费算力。
MUR(Momentum Uncertainty-guided Reasoning)的做法是:在推理过程中实时追踪每一步的「不确定性」,只有不确定性高的步骤才分配更多思考资源。 这里借用了物理里「动量」的概念——之前几步的不确定性有多大,会「带动」下一步的资源分配,而不是每步独立判断。
研究者还设计了一个叫
gamma-control 的参数,只需要调一个数就能控制整体推理的「松紧度」,不需要重新训练模型。实验数据:在 MATH-500、AIME24、AIME25、GPQA 四个数学和科学推理基准上,用 Qwen3 1.7B/4B/8B 测试,MUR 平均减少超过 50% 的计算量,同时准确率反而提升了 0.62–3.37 个百分点。2

Captain Cinema:输入故事简介,输出短片
一句话版本:ByteDance 和约翰霍普金斯做的系统,给它一段故事文字,它能生成视觉连贯、情节一致的短电影。
AI 生成单段视频现在已经不算难,难的是生成「多场景、长时间、视觉统一」的作品——角色从这个镜头走到下一个镜头时,脸不能变,灯光风格不能突变,故事线不能断。
Captain Cinema 的解法分两步走:
- 自上而下的关键帧规划:先用语言模型理解整个故事,然后生成一组「关键帧」,定义整部短片的叙事节奏和主要视觉节点——相当于先画好分镜板。
- 自下而上的视频合成:关键帧确定后,再用视频模型填充帧与帧之间的动态画面,生成流畅的时间轴。
为了让视频模型能「记住」之前的画面,研究者专门为多模态扩散 Transformer(MM-DiT)设计了交错训练策略,让它能在长上下文视频数据上保持一致性。
实验证明生成质量和效率都比直接端到端生成要好。3

TTS-VAR:花更少算力,图生成质量更高
一句话版本:不用重新训练图像生成模型,只在推理时加一套「搜索机制」,让模型挑出更好的结果。
视觉自回归模型(VAR)是一类图像生成模型,它生成图像的方式有点像猜谜——先生成大致轮廓,再逐步填细节(由粗到细)。
TTS-VAR 把这个过程想象成一个路径搜索问题:模型每次生成时其实面临很多可能的「选择」,传统做法是随便挑一条走,而 TTS-VAR 让模型同时探索多条路径,然后按质量筛选。
具体有两个机制:
- 粗尺度:用聚类算法保留结构多样性,确保候选路径不会都长一个样
- 细尺度:用一个融合了历史生成信息的「潜力评分」,优先保留最有可能出好结果的候选
在 Infinity 模型上测试,GenEval 得分从 0.69 提升到 0.75,提升幅度 8.7%,而且不需要额外训练。4
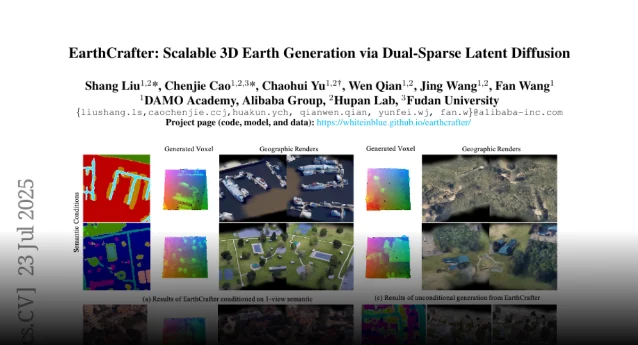
EarthCrafter:用 AI 生成真实感 3D 地球地形
一句话版本:阿里 DAMO Academy 发布了目前最大规模的 3D 航空数据集,并训练了一个能生成数千平方公里地形的 3D 生成模型。
现有 3D 生成模型面对「生成一栋楼」这个任务完全没问题,但要生成「600 米 × 600 米的真实地形」,计算量会爆炸——因为地理尺度的 3D 数据太大了。
EarthCrafter 从数据和模型架构两端同时发力:
数据端:发布了 Aerial-Earth3D,目前最大的 3D 航空数据集——5 万个场景、每个 600m×600m,来自美国本土的谷歌地球影像,共计 4500 万帧,每帧附带位姿标注、深度图、语义分割等信息。
模型端:核心思路是「把几何和纹理分开来压缩和生成」。两个稀疏 3D 自编码器分别处理几何体素和纹理(2D 高斯分布),把巨大的地理数据压缩到紧凑的潜在空间,大幅降低计算成本。然后用一个「条件感知流匹配模型」把它们组合起来,支持「给语义图」「给参考图」「什么都不给」三种输入方式。
实验证明在超大尺度生成上明显优于现有方法,还能支持城市布局生成、无条件地形合成等多种应用。5
Spelke Segments:让 AI 像人类婴儿一样理解「物体」
一句话版本:斯坦福和 OpenAI 的研究者提出了一种新的物体分割方法,依据「东西会不会一起动」而非「这是什么类型的东西」来定义物体边界。
传统的图像分割(比如最流行的 SAM)是基于语义的——「这里是一只猫,那里是一张椅子」。但发展心理学告诉我们,人类婴儿最开始感知物体的方式不是「它是什么」,而是「它们会不会一起动」——这被称为 Spelke 对象理论。
这篇论文把这个理论工程化了:
- SpelkeBench:建立了一个包含各类自然图像的数据集,专门测试模型能不能按「联动关系」而不是「语义类别」分割物体
- SpelkeNet:一类视觉世界模型,训练目标是预测「如果我戳这个区域,哪里会动」,然后用统计方法把联动区域归并成 Spelke 对象
在 SpelkeBench 上,SpelkeNet 超过了 SAM 等监督学习基线。更重要的是,用 Spelke 分割结果来辅助 3D 物体操控任务(3DEditBench),效果也比语义分割更好。
这个方向对机器人操控、场景理解等下游任务有实际意义——机器人不需要知道「这是杯子」,只需要知道「这一堆东西抓住一起动」。6
以上论文均为预印本,尚未经过同行评审,结论有待后续验证。
References
- 1Group Sequence Policy Optimization
- 2MUR: Momentum Uncertainty guided Reasoning
- 3Captain Cinema: Towards Short Movie Generation
- 4TTS-VAR: A Test-Time Scaling Framework for Visual Auto-Regressive Generation
- 5EarthCrafter: Scalable 3D Earth Generation via Dual-Sparse Latent Diffusion
- 6Discovering and using Spelke segments
Add more perspectives or context around this Drop.